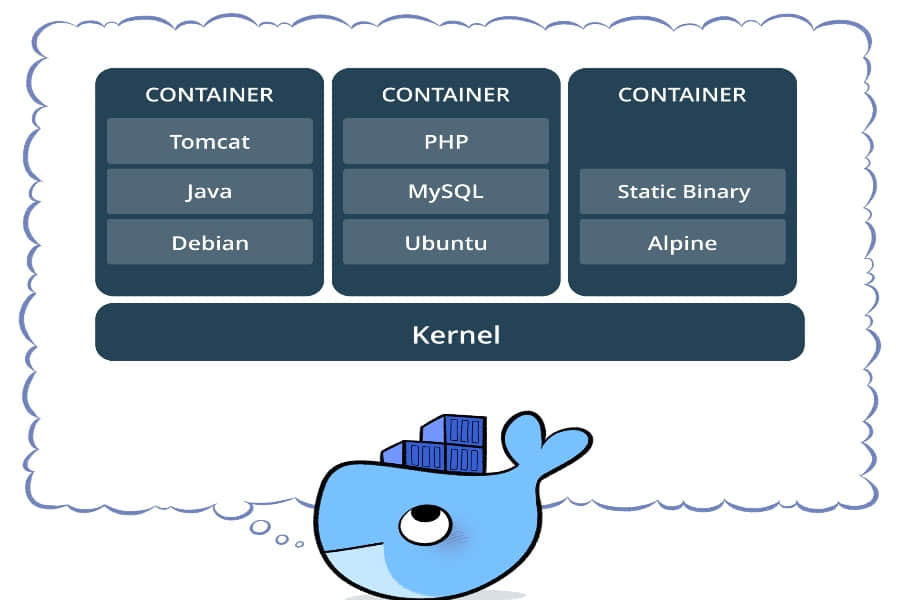
在 Ubuntu 上体验 LXD 容器

本文的主角是容器,一种类似虚拟机但更轻量级的构造。你可以轻易地在你的 Ubuntu 桌面系统中创建一堆容器!
虚拟机会虚拟出整个电脑让你来安装客户机操作系统。相比之下,容器复用了主机的 Linux 内核,只是简单地 包容 了我们选择的根文件系统(也就是运行时环境)。Linux 内核有很多功能可以将运行的 Linux 容器与我们的主机分割开(也就是我们的 Ubuntu 桌面)。
Linux 本身需要一些手工操作来直接管理他们。好在,有 LXD(读音为 Lex-deeh),这是一款为我们管理 Linux 容器的服务。
我们将会看到如何:
- 在我们的 Ubuntu 桌面上配置容器,
- 创建容器,
- 安装一台 web 服务器,
- 测试一下这台 web 服务器,以及
- 清理所有的东西。
设置 Ubuntu 容器
如果你安装的是 Ubuntu 16.04,那么你什么都不用做。只要安装下面所列出的一些额外的包就行了。若你安装的是 Ubuntu 14.04.x 或 Ubuntu 15.10,那么按照 LXD 2.0 系列(二):安装与配置 来进行一些操作,然后再回来。
确保已经更新了包列表:
sudo apt update
sudo apt upgrade
安装 lxd 包:
sudo apt install lxd
若你安装的是 Ubuntu 16.04,那么还可以让你的容器文件以 ZFS 文件系统的格式进行存储。Ubuntu 16.04 的 Linux kernel 包含了支持 ZFS 必要的内核模块。若要让 LXD 使用 ZFS 进行存储,我们只需要安装 ZFS 工具包。没有 ZFS,容器会在主机文件系统中以单独的文件形式进行存储。通过 ZFS,我们就有了写入时拷贝等功能,可以让任务完成更快一些。
安装 zfsutils-linux 包(若你安装的是 Ubuntu 16.04.x):
sudo apt install zfsutils-linux
安装好 LXD 后,包安装脚本应该会将你加入 lxd 组。该组成员可以使你无需通过 sudo 就能直接使用 LXD 管理容器。根据 Linux 的习惯,你需要先登出桌面会话然后再登录 才能应用 lxd 的组成员关系。(若你是高手,也可以通过在当前 shell 中执行 newgrp lxd 命令,就不用重登录了)。
在开始使用前,LXD 需要初始化存储和网络参数。
运行下面命令:
$ sudo lxd init
Name of the storage backend to use (dir or zfs): zfs
Create a new ZFS pool (yes/no)? yes
Name of the new ZFS pool: lxd-pool
Would you like to use an existing block device (yes/no)? no
Size in GB of the new loop device (1GB minimum): 30
Would you like LXD to be available over the network (yes/no)? no
Do you want to configure the LXD bridge (yes/no)? yes
> You will be asked about the network bridge configuration. Accept all defaults and continue.
Warning: Stopping lxd.service, but it can still be activated by:
lxd.socket
LXD has been successfully configured.
$ _
我们在一个(单独)的文件而不是块设备(即分区)中构建了一个文件系统来作为 ZFS 池,因此我们无需进行额外的分区操作。在本例中我指定了 30GB 大小,这个空间取之于根(/) 文件系统中。这个文件就是 /var/lib/lxd/zfs.img。
行了!最初的配置完成了。若有问题,或者想了解其他信息,请阅读 https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/ 。
创建第一个容器
所有 LXD 的管理操作都可以通过 lxc 命令来进行。我们通过给 lxc 不同参数来管理容器。
lxc list
可以列出所有已经安装的容器。很明显,这个列表现在是空的,但这表示我们的安装是没问题的。
lxc image list
列出可以用来启动容器的(已经缓存的)镜像列表。很明显这个列表也是空的,但这也说明我们的安装是没问题的。
lxc image list ubuntu:
列出可以下载并启动容器的远程镜像。而且指定了显示 Ubuntu 镜像。
lxc image list images:
列出可以用来启动容器的(已经缓存的)各种发行版的镜像列表。这会列出各种发行版的镜像比如 Alpine、Debian、Gentoo、Opensuse 以及 Fedora。
让我们启动一个 Ubuntu 16.04 容器,并称之为 c1:
$ lxc launch ubuntu:x c1
Creating c1
Starting c1
$
我们使用 launch 动作,然后选择镜像 ubuntu:x (x 表示 Xenial/16.04 镜像),最后我们使用名字 c1 作为容器的名称。
让我们来看看安装好的首个容器,
$ lxc list
+---------|---------|----------------------|------|------------|-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------|---------|----------------------|------|------------|-----------+
| c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 |
+---------|---------|----------------------|------|------------|-----------+
我们的首个容器 c1 已经运行起来了,它还有自己的 IP 地址(可以本地访问)。我们可以开始用它了!
安装 web 服务器
我们可以在容器中运行命令。运行命令的动作为 exec。
$ lxc exec c1 -- uptime
11:47:25 up 2 min,0 users,load average:0.07,0.05,0.04
$ _
在 exec 后面,我们指定容器、最后输入要在容器中运行的命令。该容器的运行时间只有 2 分钟,这是个新出炉的容器:-)。
命令行中的 -- 跟我们 shell 的参数处理过程有关。若我们的命令没有任何参数,则完全可以省略 -。
$ lxc exec c1 -- df -h
这是一个必须要 - 的例子,由于我们的命令使用了参数 -h。若省略了 -,会报错。
然后我们运行容器中的 shell 来更新包列表。
$ lxc exec c1 bash
root@c1:~# apt update
Ign http://archive.ubuntu.com trusty InRelease
Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB]
Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB]
...
Hit http://archive.ubuntu.com trusty/universe Translation-en
Fetched 11.2 MB in 9s (1228 kB/s)
Reading package lists... Done
root@c1:~# apt upgrade
Reading package lists... Done
Building dependency tree
...
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
Setting up dpkg (1.17.5ubuntu5.7) ...
root@c1:~# _
我们使用 nginx 来做 web 服务器。nginx 在某些方面要比 Apache web 服务器更酷一些。
root@c1:~# apt install nginx
Reading package lists... Done
Building dependency tree
...
Setting up nginx-core (1.4.6-1ubuntu3.5) ...
Setting up nginx (1.4.6-1ubuntu3.5) ...
Processing triggers for libc-bin (2.19-0ubuntu6.9) ...
root@c1:~# _
让我们用浏览器访问一下这个 web 服务器。记住 IP 地址为 10.173.82.158,因此你需要在浏览器中输入这个 IP。

让我们对页面文字做一些小改动。回到容器中,进入默认 HTML 页面的目录中。
root@c1:~# cd /var/www/html/
root@c1:/var/www/html# ls -l
total 2
-rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html
root@c1:/var/www/html#
使用 nano 编辑文件,然后保存:

之后,再刷一下页面看看,

清理
让我们清理一下这个容器,也就是删掉它。当需要的时候我们可以很方便地创建一个新容器出来。
$ lxc list
+---------+---------+----------------------+------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+----------------------+------+------------+-----------+
| c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 |
+---------+---------+----------------------+------+------------+-----------+
$ lxc stop c1
$ lxc delete c1
$ lxc list
+---------+---------+----------------------+------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+----------------------+------+------------+-----------+
+---------+---------+----------------------+------+------------+-----------+
我们停止(关闭)这个容器,然后删掉它了。
本文至此就结束了。关于容器有很多玩法。而这只是配置 Ubuntu 并尝试使用容器的第一步而已。
via: https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/
作者:Simos Xenitellis 译者:lujun9972 校对:wxy