使用 Grafana Tempo 进行分布式跟踪
Grafana Tempo 是一个新的开源、大容量分布式跟踪后端。

Grafana 的 Tempo 是出自 Grafana 实验室的一个简单易用、大规模的、分布式的跟踪后端。Tempo 集成了 Grafana、Prometheus 以及 Loki,并且它只需要对象存储进行操作,因此成本低廉,操作简单。
我从一开始就参与了这个开源项目,所以我将介绍一些关于 Tempo 的基础知识,并说明为什么云原生社区会注意到它。
分布式跟踪
想要收集对应用程序请求的遥测数据是很常见的。但是在现在的服务器中,单个应用通常被分割为多个微服务,可能运行在几个不同的节点上。
分布式跟踪是一种获得关于应用的性能细粒度信息的方式,该应用程序可能由离散的服务组成。当请求到达一个应用时,它提供了该请求的生命周期的统一视图。Tempo 的分布式跟踪可以用于单体应用或微服务应用,它提供 请求范围的信息,使其成为可观察性的第三个支柱(另外两个是度量和日志)。
接下来是一个分布式跟踪系统生成应用程序甘特图的示例。它使用 Jaeger HotROD 的演示应用生成跟踪,并把它们存到 Grafana 云托管的 Tempo 上。这个图展示了按照服务和功能划分的请求处理时间。

减少索引的大小
在丰富且定义良好的数据模型中,跟踪包含大量信息。通常,跟踪后端有两种交互:使用元数据选择器(如服务名或者持续时间)筛选跟踪,以及筛选后的可视化跟踪。
为了加强搜索,大多数的开源分布式跟踪框架会对跟踪中的许多字段进行索引,包括服务名称、操作名称、标记和持续时间。这会导致索引很大,并迫使你使用 Elasticsearch 或者 Cassandra 这样的数据库。但是,这些很难管理,而且大规模运营成本很高,所以我在 Grafana 实验室的团队开始提出一个更好的解决方案。
在 Grafana 中,我们的待命调试工作流从使用指标报表开始(我们使用 Cortex 来存储我们应用中的指标,它是一个云原生基金会孵化的项目,用于扩展 Prometheus),深入研究这个问题,筛选有问题服务的日志(我们将日志存储在 Loki 中,它就像 Prometheus 一样,只不过 Loki 是存日志的),然后查看跟踪给定的请求。我们意识到,我们过滤时所需的所有索引信息都可以在 Cortex 和 Loki 中找到。但是,我们需要一个强大的集成,以通过这些工具实现跟踪的可发现性,并需要一个很赞的存储,以根据跟踪 ID 进行键值查找。
这就是 Grafana Tempo 项目的开始。通过专注于给定检索跟踪 ID 的跟踪,我们将 Tempo 设计为最小依赖性、大容量、低成本的分布式跟踪后端。
操作简单,性价比高
Tempo 使用对象存储后端,这是它唯一的依赖。它既可以被用于单一的二进制下,也可以用于微服务模式(请参考仓库中的 例子,了解如何轻松上手)。使用对象存储还意味着你可以存储大量的应用程序的痕迹,而无需任何采样。这可以确保你永远不会丢弃那百万分之一的出错或具有较高延迟的请求的跟踪。
与开源工具的强大集成
Grafana 7.3 包括了 Tempo 数据源,这意味着你可以在 Grafana UI 中可视化来自Tempo 的跟踪。而且,Loki 2.0 的新查询特性 使得 Tempo 中的跟踪更简单。为了与 Prometheus 集成,该团队正在添加对 范例 的支持,范例是可以添加到时间序列数据中的高基数元数据信息。度量存储后端不会对它们建立索引,但是你可以在 Grafana UI 中检索和显示度量值。尽管范例可以存储各种元数据,但是在这个用例中,存储跟踪 ID 是为了与 Tempo 紧密集成。
这个例子展示了使用带有请求延迟直方图的范例,其中每个范例数据点都链接到 Tempo 中的一个跟踪。

元数据一致性
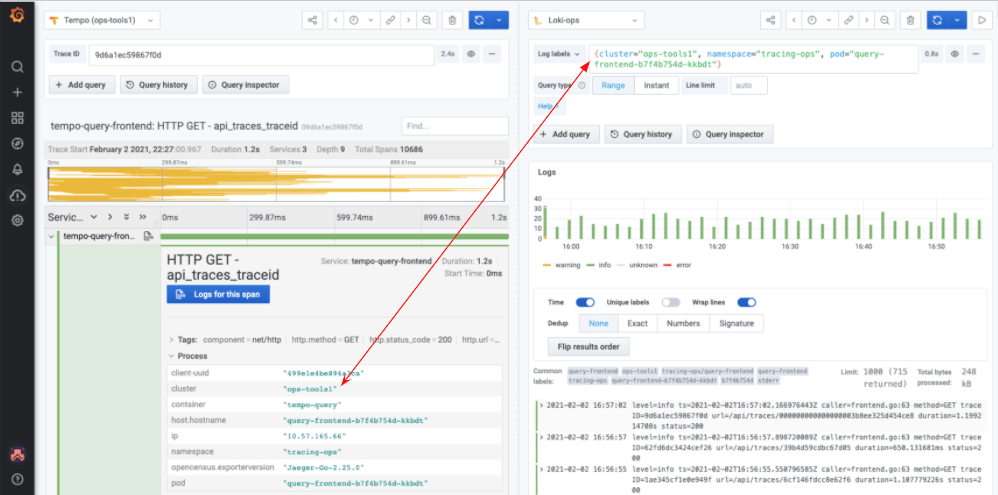
作为容器化应用程序运行的应用发出的遥测数据通常具有一些相关的元数据。这可以包括集群 ID、命名空间、吊舱 IP 等。这对于提供基于需求的信息是好的,但如果你能将元数据中包含的信息用于生产性的东西,那就更好了。 例如,你可以使用 Grafana 云代理将跟踪信息导入 Tempo 中,代理利用 Prometheus 服务发现机制轮询 Kubernetes API 以获取元数据信息,并且将这些标记添加到应用程序发出的跨域数据中。由于这些元数据也在 Loki 中也建立了索引,所以通过元数据转换为 Loki 标签选择器,可以很容易地从跟踪跳转到查看给定服务的日志。
下面是一个一致元数据的示例,它可用于Tempo跟踪中查看给定范围的日志。
云原生
Grafana Tempo 可以作为容器化应用,你可以在如 Kubernetes、Mesos 等编排引擎上运行它。根据获取/查询路径上的工作负载,各种服务可以水平伸缩。你还可以使用云原生的对象存储,如谷歌云存储、Amazon S3 或者 Tempo Azure 博客存储。更多的信息,请阅读 Tempo 文档中的 架构部分。
试一试 Tempo
如果这对你和我们一样有用,可以 克隆 Tempo 仓库试一试。
via: https://opensource.com/article/21/2/tempo-distributed-tracing
作者:Annanay Agarwal 选题:lujun9972 译者:RiaXu 校对:wxy