iptables 是一款控制系统进出流量的强大配置工具。

现代 Linux 内核带有一个叫 Netfilter 的数据包过滤框架。Netfilter 提供了允许、丢弃以及修改等操作来控制进出系统的流量数据包。基于 Netfilter 框架的用户层命令行工具 iptables 提供了强大的防火墙配置功能,允许你添加规则来构建防火墙策略。iptables 丰富复杂的功能以及其巴洛克式命令语法可能让人难以驾驭。我们就来探讨一下其中的一些功能,提供一些系统管理员解决某些问题需要的使用技巧。
避免封锁自己
应用场景:假设你将对公司服务器上的防火墙规则进行修改,你需要避免封锁你自己以及其他同事的情况(这将会带来一定时间和金钱的损失,也许一旦发生马上就有部门打电话找你了)
技巧 #1: 开始之前先备份一下 iptables 配置文件。
用如下命令备份配置文件:
/sbin/iptables-save > /root/iptables-works
技巧 #2: 更妥当的做法,给文件加上时间戳。
用如下命令加时间戳:
/sbin/iptables-save > /root/iptables-works-`date +%F`
然后你就可以生成如下名字的文件:
/root/iptables-works-2018-09-11
这样万一使得系统不工作了,你也可以很快的利用备份文件恢复原状:
/sbin/iptables-restore < /root/iptables-works-2018-09-11
技巧 #3: 每次创建 iptables 配置文件副本时,都创建一个指向最新的文件的链接。
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
技巧 #4: 将特定规则放在策略顶部,底部放置通用规则。
避免在策略顶部使用如下的一些通用规则:
iptables -A INPUT -p tcp --dport 22 -j DROP
你在规则中指定的条件越多,封锁自己的可能性就越小。不要使用上面非常通用的规则,而是使用如下的规则:
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
此规则表示在 INPUT 链尾追加一条新规则,将源地址为 10.0.0.0/8、 目的地址是 192.168.100.101、目的端口号是 22 (--dport 22 ) 的 TCP(-p tcp )数据包通通丢弃掉。
还有很多方法可以设置更具体的规则。例如,使用 -i eth0 将会限制这条规则作用于 eth0 网卡,对 eth1 网卡则不生效。
技巧 #5: 在策略规则顶部将你的 IP 列入白名单。
这是一个有效地避免封锁自己的设置:
iptables -I INPUT -s <your IP> -j ACCEPT
你需要将该规则添加到策略首位置。-I 表示则策略首部插入规则,-A 表示在策略尾部追加规则。
技巧 #6: 理解现有策略中的所有规则。
不犯错就已经成功了一半。如果你了解 iptables 策略背后的工作原理,使用起来更为得心应手。如果有必要,可以绘制流程图来理清数据包的走向。还要记住:策略的预期效果和实际效果可能完全是两回事。
设置防火墙策略
应用场景:你希望给工作站配置具有限制性策略的防火墙。
技巧 #1: 设置默认规则为丢弃
# Set a default policy of DROP
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT DROP [0:0]
技巧 #2: 将用户完成工作所需的最少量服务设置为允许
该策略需要允许工作站能通过 DHCP(-p udp --dport 67:68 -sport 67:68)来获取 IP 地址、子网掩码以及其他一些信息。对于远程操作,需要允许 SSH 服务(-dport 22),邮件服务(--dport 25),DNS 服务(--dport 53),ping 功能(-p icmp),NTP 服务(--dport 123 --sport 123)以及 HTTP 服务(-dport 80)和 HTTPS 服务(--dport 443)。
# Set a default policy of DROP
*filter
:INPUT DROP [0:0]
:FORWARD DROP [0:0]
:OUTPUT DROP [0:0]
# Accept any related or established connections
-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
# Allow all traffic on the loopback interface
-A INPUT -i lo -j ACCEPT
-A OUTPUT -o lo -j ACCEPT
# Allow outbound DHCP request
-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
# Allow inbound SSH
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
# Allow outbound email
-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
# Outbound DNS lookups
-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
# Outbound PING requests
-A OUTPUT –o eth0 -p icmp -j ACCEPT
# Outbound Network Time Protocol (NTP) requests
-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
# Outbound HTTP
-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
COMMIT
限制 IP 地址范围
应用场景:贵公司的 CEO 认为员工在 Facebook 上花费过多的时间,需要采取一些限制措施。CEO 命令下达给 CIO,CIO 命令 CISO,最终任务由你来执行。你决定阻止一切到 Facebook 的访问连接。首先你使用 host 或者 whois 命令来获取 Facebook 的 IP 地址。
host -t a www.facebook.com
www.facebook.com is an alias for star.c10r.facebook.com.
star.c10r.facebook.com has address 31.13.65.17
whois 31.13.65.17 | grep inetnum
inetnum: 31.13.64.0 - 31.13.127.255
然后使用 CIDR 到 IPv4 转换 页面来将其转换为 CIDR 表示法。然后你得到 31.13.64.0/18 的地址。输入以下命令来阻止对 Facebook 的访问:
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
按时间规定做限制 - 场景1
应用场景:公司员工强烈反对限制一切对 Facebook 的访问,这导致了 CEO 放宽了要求(考虑到员工的反对以及他的助理提醒说她负责更新他的 Facebook 页面)。然后 CEO 决定允许在午餐时间访问 Facebook(中午 12 点到下午 1 点之间)。假设默认规则是丢弃,使用 iptables 的时间功能便可以实现。
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 –timestop 13:00 –d 31.13.64.0/18 -j ACCEPT
该命令中指定在中午12点(--timestart 12:00)到下午 1 点(--timestop 13:00)之间允许(-j ACCEPT)到 Facebook.com (-d [31.13.64.0/18][5])的 http 以及 https (-m multiport --dport http,https)的访问。
按时间规定做限制 - 场景2
应用场景:在计划系统维护期间,你需要设置凌晨 2 点到 3 点之间拒绝所有的 TCP 和 UDP 访问,这样维护任务就不会受到干扰。使用两个 iptables 规则可实现:
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
该规则禁止(-j DROP)在凌晨2点(--timestart 02:00)到凌晨3点(--timestop 03:00)之间的 TCP 和 UDP (-p tcp and -p udp)的数据进入(-A INPUT)访问。
限制连接数量
应用场景:你的 web 服务器有可能受到来自世界各地的 DoS 攻击,为了避免这些攻击,你可以限制单个 IP 地址到你的 web 服务器创建连接的数量:
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
分析一下上面的命令。如果单个主机在一分钟之内新建立(-p tcp -syn)超过 20 个(-connlimit-above 20)到你的 web 服务器(--dport http,https)的连接,服务器将拒绝(-j REJECT)建立新的连接,然后通知对方新建连接被拒绝(--reject-with-tcp-reset)。
监控 iptables 规则
应用场景:由于数据包会遍历链中的规则,iptables 遵循 “首次匹配获胜” 的原则,因此经常匹配的规则应该靠近策略的顶部,而不太频繁匹配的规则应该接近底部。 你怎么知道哪些规则使用最多或最少,可以在顶部或底部附近监控?
技巧 #1: 查看规则被访问了多少次
使用命令:
iptables -L -v -n –line-numbers
用 -L 选项列出链中的所有规则。因为没有指定具体哪条链,所有链规则都会被输出,使用 -v 选项显示详细信息,-n 选项则显示数字格式的数据包和字节计数器,每个规则开头的数值表示该规则在链中的位置。
根据数据包和字节计数的结果,你可以将访问频率最高的规则放到顶部,将访问频率最低的规则放到底部。
技巧 #2: 删除不必要的规则
哪条规则从来没有被访问过?这些可以被清除掉。用如下命令查看:
iptables -nvL | grep -v "0 0"
注意:两个数字 0 之间不是 Tab 键,而是 5 个空格。
技巧 #3: 监控正在发生什么
可能你也想像使用 top 命令一样来实时监控 iptables 的情况。使用如下命令来动态监视 iptables 中的活动,并仅显示正在遍历的规则:
watch --interval=5 'iptables -nvL | grep -v "0 0"'
watch 命令通过参数 iptables -nvL | grep -v “0 0“ 每隔 5 秒输出 iptables 的动态。这条命令允许你查看数据包和字节计数的变化。
输出日志
应用场景:经理觉得你这个防火墙员工的工作质量杠杠的,但如果能有网络流量活动日志最好了。有时候这比写一份有关工作的报告更有效。
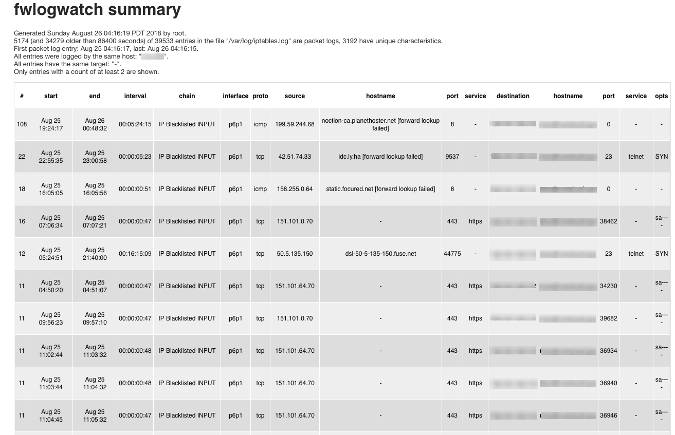
使用工具 FWLogwatch 基于 iptables 防火墙记录来生成日志报告。FWLogwatch 工具支持很多形式的报告并且也提供了很多分析功能。它生成的日志以及月报告使得管理员可以节省大量时间并且还更好地管理网络,甚至减少未被注意的潜在攻击。
这里是一个 FWLogwatch 生成的报告示例:
不要满足于允许和丢弃规则
本文中已经涵盖了 iptables 的很多方面,从避免封锁自己、配置 iptables 防火墙以及监控 iptables 中的活动等等方面介绍了 iptables。你可以从这里开始探索 iptables 甚至获取更多的使用技巧。
via: https://opensource.com/article/18/10/iptables-tips-and-tricks
作者:Gary Smith 选题:lujun9972 译者:jrg 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出












