使用条块化I/O管理多个LVM磁盘(第五部分)
在本文中,我们将了解逻辑卷是如何通过条块化I/O来写入数据到磁盘的。逻辑卷管理的酷炫特性之一,就是它能通过条块化I/O跨多个磁盘写入数据。

LVM条块化是什么?
LVM条块化是LVM功能之一,该技术会跨多个磁盘写入数据,而不是对单一物理卷持续写入。

使用条块化I/O管理LVM磁盘
条块化特性
- 它会改善磁盘性能。
- 避免对单一磁盘的不断的大量写入。
- 使用对多个磁盘的条块化写入,可以减少磁盘填满的几率。
在逻辑卷管理中,如果我们需要创建一个逻辑卷,扩展的卷会完全映射到卷组和物理卷。在此种情形中,如果其中一个PV(物理卷)被填满,我们需要从其它物理卷中添加更多扩展。这样,添加更多扩展到PV中后,我们可以指定逻辑卷使用特定的物理卷写入I/O。
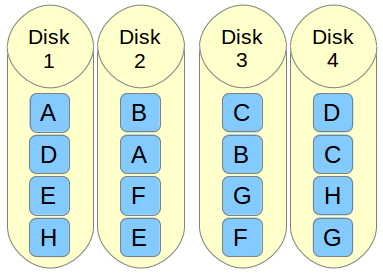
假设我们有四个磁盘驱动器,分别指向了四个物理卷,如果各个物理卷总计可以达到100 I/O,我们卷组就可以获得400 I/O。
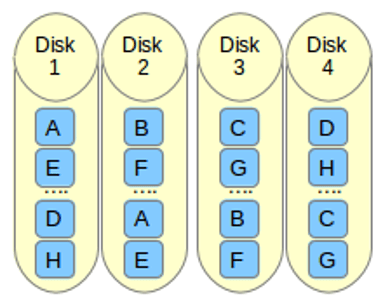
如果我们不使用条块化方法,文件系统将横跨基础物理卷写入。例如,写入一些数据到物理卷达到100 I/O,这些数据只会写入到第一个PV(sdb1)。如果我们在写入时使用条块化选项创建逻辑卷,它会分割100 I/O分别写入到四个驱动器中,这就是说每个驱动器中都会接收到25 I/O。
这会在循环过程中完成。如果这些逻辑卷其中任何一个需要扩展,在这种情形下,我们不能添加1个或2个PV,必须添加所有4个pv来扩展逻辑卷大小。这是条块化特性的缺点之一,从中我们可以知道,在创建逻辑卷时,我们需要为所有逻辑卷分配相同的条块大小。
逻辑卷管理有着这些特性,它使我们能够同时在多个pv中条块化数据。如果你对逻辑卷熟悉,你可以去设置逻辑卷条块化。反之,你则必须了解逻辑卷管理的基础知识了,请阅读更基础的文章来了解逻辑卷管理。
我的服务器设置
这里,我使用CentOS6.5用作练习。下面这些步骤也适用于RHEL、Oracle Linux以及大多数发行版。
操作系统: CentOS 6.5
IP地址: 192.168.0.222
主机名: tecmint.storage.com
条块化I/O的逻辑卷管理
出于演示目的,我已经准备了4个硬盘驱动器,每个驱动器1GB大小。让我用下面的‘fdisk’命令来列给你看看吧。
# fdisk -l | grep sd

列出硬盘驱动器
现在,我们必须为这4个硬盘驱动器sdb,sdc,sdd和sde创建分区,我们将用‘fdisk’命令来完成该工作。要创建分区,请遵从本文第一部分中步骤#4的说明,并在创建分区时确保你已将类型修改为LVM(8e)。
# pvcreate /dev/sd[b-e]1 -v

在LVM中创建物理卷
PV创建完成后,你可以使用‘pvs’命令将它们列出来。
# pvs

验证物理卷
现在,我们需要使用这4个物理卷来定义卷组。这里,我定义了一个物理扩展大小(PE)为16MB,名为vg\_strip的卷组。
# vgcreate -s 16M vg_strip /dev/sd[b-e]1 -v
上面命令中选项的说明:
- [b-e]1 – 定义硬盘驱动器名称,如sdb1,sdc1,sdd1,sde1。
- -s – 定义物理扩展大小。
- -v – 详情。
接下来,验证新创建的卷组:
# vgs vg_strip

验证卷组
要获取VG更详细的信息,可以在vgdisplay命令中使用‘-v’选项,它将给出vg\_strip卷组中所使用的全部物理卷的详细情况。
# vgdisplay vg_strip -v

卷组信息
回到我们的话题,现在在创建逻辑卷时,我们需要定义条块化值,就是数据需要如何使用条块化方法来写入到我们的逻辑卷中。
这里,我创建了一个名为lv\_tecmint-strp1,大小为900MB的逻辑卷,它需要放到vg\_strip卷组中。我定义了4个条块,就是说数据在写入到我的逻辑卷时,需要条块化分散到4个PV中。
# lvcreate -L 900M -n lv_tecmint_strp1 -i4 vg_strip
- -L –逻辑卷大小
- -n –逻辑卷名称
- -i –条块化

创建逻辑卷
在上面的图片中,我们可以看到条块尺寸的默认大小为64 KB,如果我们需要自定义条块值,我们可以使用-I(大写I)。要确认逻辑卷已经是否已经创建,请使用以下命令。
# lvdisplay vg_strip/lv_tecmint_strp1

确认逻辑卷
现在,接下来的问题是,我们怎样才能知道条块被写入到了4个驱动器。这里,我们可以使用‘lvdisplay’和-m(显示逻辑卷映射)命令来验证。
# lvdisplay vg_strip/lv_tecmint_strp1 -m

检查逻辑卷
要创建自定义的条块尺寸,我们需要用我们自定义的条块大小256KB来创建一个1GB大小的逻辑卷。现在,我打算将条块分布到3个PV上。这里,我们可以定义我们想要哪些pv条块化。
# lvcreate -L 1G -i3 -I 256 -n lv_tecmint_strp2 vg_strip /dev/sdb1 /dev/sdc1 /dev/sdd1

定义条块大小
接下来,检查条块大小和条块化的卷。
# lvdisplay vg_strip/lv_tecmint_strp2 -m

检查条块大小
是时候使用设备映射了,我们使用‘dmsetup’命令来完成这项工作。它是一个低级别的逻辑卷管理工具,它用于管理使用了设备映射驱动的逻辑设备。
# dmsetup deps /dev/vg_strip/lv_tecmint_strp[1-2]

设备映射
这里,我们可以看到strp1依赖于4个驱动器,strp2依赖于3个设备。
希望你已经明白,我们怎样能让逻辑卷条块化来写入数据。对于此项设置,必须掌握逻辑卷管理基础知识。
在我的下一篇文章中,我将给大家展示怎样在逻辑卷管理中迁移数据。到那时,请静候更新。同时,别忘了对本文提出有价值的建议。
via: http://www.tecmint.com/manage-multiple-lvm-disks-using-striping-io/
作者:Babin Lonston 译者:GOLinux 校对:wxy