让我们用这些Unix/Linux命令技巧开启新的一年,提高在终端下的生产力。我已经找了很久了,现在就与你们分享。

删除一个大文件
我在生产服务器上有一个很大的200GB的日志文件需要删除。我的rm和ls命令已经崩溃,我担心这是由于巨大的磁盘IO造成的,要删除这个大文件,输入:
> /path/to/file.log
# 或使用如下格式
: > /path/to/file.log
# 然后删除它
rm /path/to/file.log
如何记录终端输出?
试试使用script命令行工具来为你的终端输出创建输出记录。
script my.terminal.sessio
输入命令:
ls
date
sudo service foo stop
要退出(结束script会话),输入 exit 或者 logout 或者按下 control-D。
exit
要浏览输入:
more my.terminal.session
less my.terminal.session
cat my.terminal.session
还原被删除的 /tmp 文件夹
我在文章Linux和Unix shell,我犯了一些错误。我意外地删除了/tmp文件夹。要还原它,我需要这么做:
mkdir /tmp
chmod 1777 /tmp
chown root:root /tmp
ls -ld /tmp
锁定一个文件夹
为了我的数据隐私,我想要锁定我文件服务器下的/downloads文件夹。因此我运行了:
chmod 0000 /downloads
root用户仍旧可以访问,而ls和cd命令则不工作。要还原它用:
chmod 0755 /downloads
在vim中用密码保护文件
害怕root用户或者其他人偷窥你的个人文件么?尝试在vim中用密码保护,输入:
vim +X filename
或者,在退出vim之前使用:X 命令来加密你的文件,vim会提示你输入一个密码。
清除屏幕上的乱码
只要输入:
reset
易读格式
传递-h或者-H(和其他选项)选项给GNU或者BSD工具来获取像ls、df、du等命令以易读的格式输出:
ls -lh
# 以易读的格式 (比如: 1K 234M 2G)
df -h
df -k
# 以字节、KB、MB 或 GB 输出:
free -b
free -k
free -m
free -g
# 以易读的格式输出 (比如 1K 234M 2G)
du -h
# 以易读的格式显示文件系统权限
stat -c %A /boot
# 比较易读的数字
sort -h -a file
# 在Linux上以易读的形式显示cpu信息
lscpu
lscpu -e
lscpu -e=cpu,node
# 以易读的形式显示每个文件的大小
tree -h
tree -h /boot
在Linux系统中显示已知的用户信息
只要输入:
## linux 版本 ##
lslogins
## BSD 版本 ##
logins
示例输出:
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 0 0 22:37:59 root
1 bin 0 1 bin
2 daemon 0 1 daemon
3 adm 0 1 adm
4 lp 0 1 lp
5 sync 0 1 sync
6 shutdown 0 1 2014-Dec17 shutdown
7 halt 0 1 halt
8 mail 0 1 mail
10 uucp 0 1 uucp
11 operator 0 1 operator
12 games 0 1 games
13 gopher 0 1 gopher
14 ftp 0 1 FTP User
27 mysql 0 1 MySQL Server
38 ntp 0 1
48 apache 0 1 Apache
68 haldaemon 0 1 HAL daemon
69 vcsa 0 1 virtual console memory owner
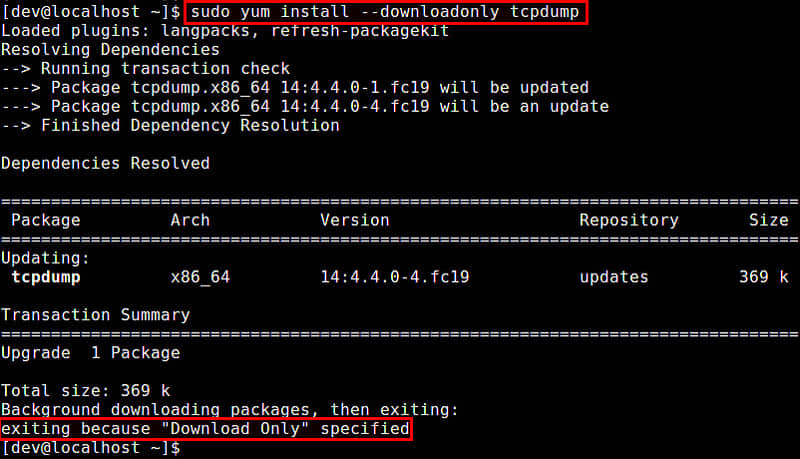
72 tcpdump 0 1
74 sshd 0 1 Privilege-separated SSH
81 dbus 0 1 System message bus
89 postfix 0 1
99 nobody 0 1 Nobody
173 abrt 0 1
497 vnstat 0 1 vnStat user
498 nginx 0 1 nginx user
499 saslauth 0 1 "Saslauthd user"
我如何删除意外在当前文件夹下解压的文件?
我意外在/var/www/html/而不是/home/projects/www/current下解压了一个tarball。它搞乱了/var/www/html下的文件,你甚至不知道哪些是误解压出来的。最简单修复这个问题的方法是:
cd /var/www/html/
/bin/rm -f "$(tar ztf /path/to/file.tar.gz)"
对top命令的输出感到疑惑?
正经地说,你应该试一下用htop代替top:
sudo htop
想要再次运行相同的命令
只需要输入!!。比如:
/myhome/dir/script/name arg1 arg2
# 要再次运行相同的命令
!!
## 以root用户运行最后运行的命令
sudo !!
!!会运行最近使用的命令。要运行最近运行的以“foo”开头命令:
!foo
# 以root用户运行上一次以“service”开头的命令
sudo !service
!$用于运行带上最后一个参数的命令:
# 编辑 nginx.conf
sudo vi /etc/nginx/nginx.conf
# 测试 nginx.conf
/sbin/nginx -t -c /etc/nginx/nginx.conf
# 测试完 "/sbin/nginx -t -c /etc/nginx/nginx.conf"你可以用vi再次编辑这个文件了
sudo vi !$
在终端上提醒你必须得走了
如果你需要提醒离开你的终端,输入下面的命令:
leave +hhmm
这里:
- hhmm - 时间是以hhmm的形式,hh表示小时(12时制或者24小时制),mm代表分钟。所有的时间都转化成12时制,并且假定发生在接下来的12小时。
甜蜜的家
想要进入刚才进入的地方?运行:
cd -
需要快速地回到你的家目录?输入:
cd
变量CDPATH定义了目录的搜索路径:
export CDPATH=/var/www:/nas10
现在,不用输入cd */var/www/html/ 这样长了,我可以直接输入下面的命令进入 /var/www/html:
cd html
在less浏览时编辑文件
要编辑一个正在用less浏览的文件,可以按下v。你就可以用变量$EDITOR所指定的编辑器来编辑了:
less *.c
less foo.html
## 按下v键来编辑文件 ##
## 退出编辑器后,你可以继续用less浏览了 ##
列出你系统中的所有文件和目录
要看到你系统中的所有目录,运行:
find / -type d | less
# 列出$HOME 所有目录
find $HOME -type d -ls | less
要看到所有的文件,运行:
find / -type f | less
# 列出 $HOME 中所有的文件
find $HOME -type f -ls | less
用一条命令构造目录树
你可以用mkdir加上-p选项一次创建一颗目录树:
mkdir -p /jail/{dev,bin,sbin,etc,usr,lib,lib64}
ls -l /jail/
将文件复制到多个目录中
不必运行:
cp /path/to/file /usr/dir1
cp /path/to/file /var/dir2
cp /path/to/file /nas/dir3
运行下面的命令来复制文件到多个目录中:
echo /usr/dir1 /var/dir2 /nas/dir3 | xargs -n 1 cp -v /path/to/file
留下创建一个shell函数作为读者的练习。
快速找出两个目录的不同
diff命令会按行比较文件。但是它也可以比较两个目录:
ls -l /tmp/r
ls -l /tmp/s
# 使用 diff 比较两个文件夹
diff /tmp/r/ /tmp/s/

图片: 找出目录之间的不同
文本格式化
你可以用fmt命令重新格式化每个段落。在本例中,我要用分割超长的行并且填充短行:
fmt file.txt
你也可以分割长的行,但是不重新填充,也就是说分割长行,但是不填充短行:
fmt -s file.txt
可以看见输出并将其写入到一个文件中
如下使用tee命令在屏幕上看见输出并同样写入到日志文件my.log中:
mycoolapp arg1 arg2 input.file | tee my.log
tee可以保证你同时在屏幕上看到mycoolapp的输出并写入文件 my.log。
via: http://www.cyberciti.biz/open-source/command-line-hacks/20-unix-command-line-tricks-part-i/
作者:nixCraft 译者:geekpi 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出