使用Nemiver调试器来调试 C/C++ 程序
如果你读过我写的使用GDB命令行调试器调试C/C++程序,你就会明白一个调试器对一段C/C++程序来说有多么的重要和有用。然而,如果一个像GDB这样的命令行对你而言听起来更像一个问题而不是一个解决方案的话,那么你也许会对Nemiver更感兴趣。Nemiver 是一款基于 GTK+ 的用于C/C++程序的图形化的独立调试器,它以GDB作为其后端。最令人赞赏的是其速度和稳定性,Nemiver是一个非常可靠,具备许多优点的调试工具。
Nemiver的安装
基于Debian发行版,它的安装时非常直接简单,如下:
$ sudo apt-get install nemiver
在Arch Linux中安装如下:
$ sudo pacman -S nemiver
在Fedora中安装如下:
$ sudo yum install nemiver
如果你选择自己编译,GNOME 网站上有最新源码包。
最令人欣慰的是,它能够很好地与GNOME环境像结合。
Nemiver的基本用法
启动Nemiver的命令:
$ nemiver
你也可以通过执行一下命令来启动:
$ nemiver [需要调试的可执行程序的路径]
注意,如果在调试模式下编译程序(在 GCC 中使用 -g 选项)将会对 nemiver 更有帮助。
还有一个优点是Nemiver的加载很快,所以你马上就可以看到主屏幕的默认布局。
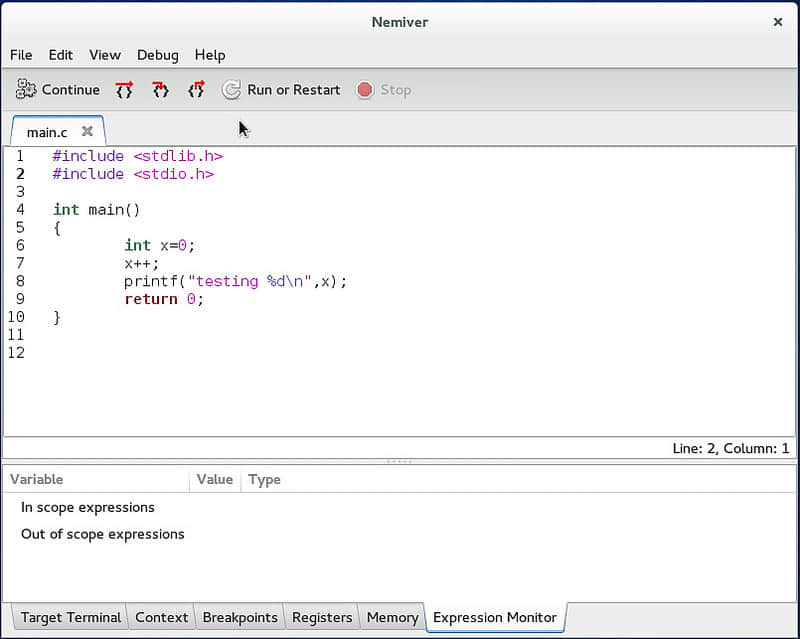
默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:

- 执行到下一行 (按键是F6)
- 执行到函数内部即停止(F7)
- 执行到函数外部即停止(Shift+F7)
不过我个人喜欢“Run to cursor(运行至光标所在行)”,该选项使你的程序准确的运行至你光标所在行,它的默认按键是F11。
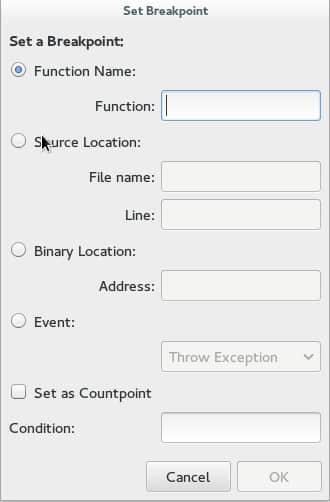
断点是很容易使用的。最快捷的方式是在一行代码上按下F8来设置一个断点。但是Nemiver在“Debug”菜单下也有一个更复杂的菜单,它允许你在一个特定的函数,某一行,二进制文件中的位置,或者类似异常、分支或者exec的事件上设置断点。
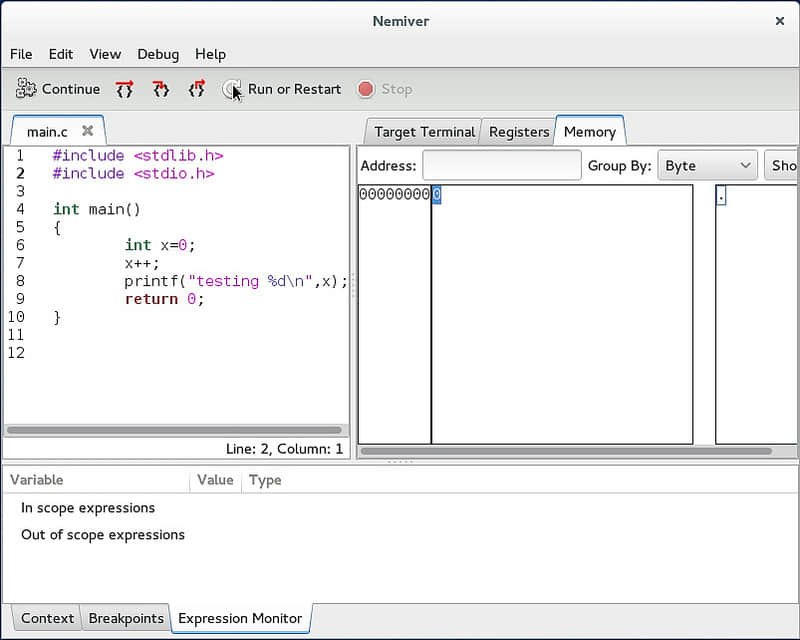
你也可以通过追踪来查看一个变量。在“Debug”中,你可以用一个表达式的名字来检查它的值,然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能,虽然我从未有兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,虽然鼠标悬停可以取到值,如果想要让它更好地工作,Nemiver是可以看到结构并给出所有成员的变量的赋值。

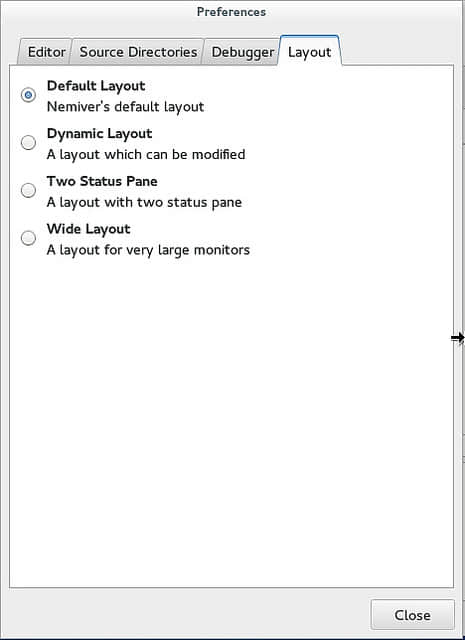
谈到方便地访问信息,我也非常欣赏这个程序的布局。默认情况下,代码在上半部分,功能区标签在下半部分。这可以让你访问终端的输出、上下文追踪器、断点列表、注册器地址、内存映射和变量控制。但是请注意在“Edit”-“Preferences”-“Layout”下你可以选择不同的布局,包括一个可以修改的动态布局。
自然,当你设置了全部断点,观察点和布局,您可以在“File”菜单下很方便地保存该会话,以便你下次打开时恢复。
Nemiver的高级用法
到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始调试一个简单的程序需要了解什么。如果你有更高的需求,特别是对于一些更加复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
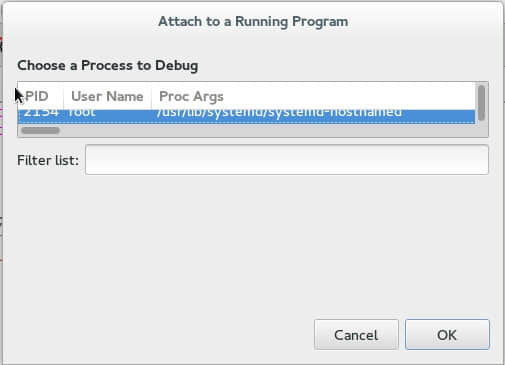
调试一个正在运行的进程
Nemiver允许你驳接到一个正在运行的进程进行调试。在“File”菜单,你可以筛选出正在运行的进程,并驳接到某个进程。
通过TCP连接远程调试一个程序
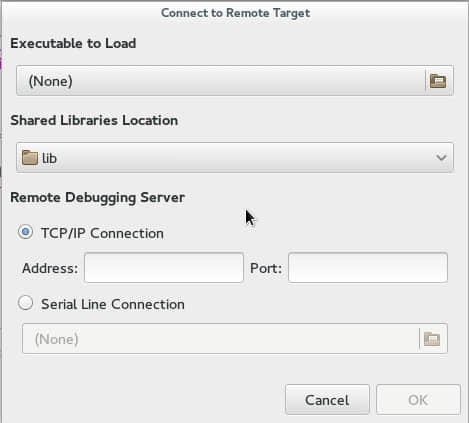
Nemiver支持远程调试,你可以在一台远程机器上设置一个轻量级调试服务器,然后你在另外一台机器上启动 nemiver 去调试运行在调试服务器上的程序。如果出于某些原因,你不能在远程机器上很好地驾驭 Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库位置、远程地址和端口。
使用你的GDB二进制程序进行调试
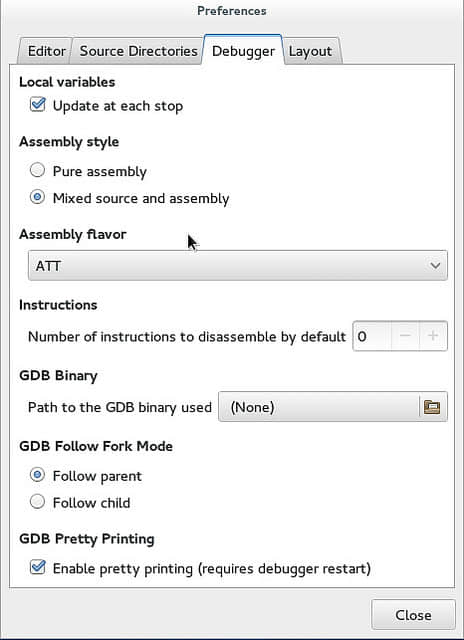
如果你的Nemiver是自行编译的,你可以在“Edit(编辑)”-“Preferences(首选项)”-“Debug(调试)”下给GDB指定一个新的位置。如果你想在Nemiver下使用定制版本的GDB,那么这个选项对你来说是非常实用的。
跟随一个子进程或者父进程
当你的程序分支时,Nemiver是可以设置为跟随子进程或者父进程的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
总而言之,Nemiver大概是我最喜欢的不在IDE里面的调试程序。在我看来,它甚至可以击败GDB,它和命令行程序一样深深吸引了我。所以,如果你从未使用过的话,我会强烈推荐你使用。我十分感谢它背后的开发团队给了我这么一个可靠、稳定的程序。
你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
via: http://xmodulo.com/debug-program-nemiver-debugger.html
作者:Adrien Brochard 译者:disylee 校对:wxy