
旅行中备份图片 - 组件
介绍
我在很长的时间内一直在寻找一个旅行中备份图片的理想方法,把 SD 卡放进你的相机包会让你暴露在太多的风险之中:SD 卡可能丢失或者被盗,数据可能损坏或者在传输过程中失败。比较好的一个选择是复制到另外一个介质中,即使它也是个 SD 卡,并且将它放到一个比较安全的地方去,备份到远端也是一个可行的办法,但是如果去了一个没有网络的地方就不太可行了。
我理想的备份步骤需要下面的工具:
- 用一台 iPad pro 而不是一台笔记本。我喜欢轻装旅行,我的大部分旅程都是商务相关的(而不是拍摄休闲的),我痛恨带着个人笔记本的时候还得带着商务本。而我的 iPad 却一直带着,这就是我为什么选择它的原因。
- 用尽可能少的硬件设备。
- 设备之间的连接需要很安全。我需要在旅馆和机场使用这套设备,所以设备之间的连接需要是封闭而加密的。
- 整个过程应该是可靠稳定的,我还用过其他的路由器/组合设备,但是效果不太理想。
设备
我配置了一套满足上面条件并且在未来可以扩充的设备,它包含下面这些部件的使用:
- 9.7 英寸的 iPad Pro,这是本文写作时最强大、轻薄的 iOS 设备,苹果笔不是必需的,但是作为零件之一,当我在路上可以做一些编辑工作,所有的重活由树莓派做 ,其他设备只能通过 SSH 连接就行。
- 安装了 Raspbian 操作系统树莓派 3(LCTT 译注:Raspbian 是基于 Debian 的树莓派操作系统)。
- 树莓派的 Mini SD卡 和 盒子/外壳。
- 128G 的优盘,对于我是够用了,你可以买个更大的。你也可以买个像这样的移动硬盘,但是树莓派没法通过 USB 给移动硬盘提供足够的电量,这意味你需要额外准备一个供电的 USB hub 以及电缆,这就破坏了我们让设备轻薄的初衷。
- SD 读卡器
- 另外的 SD 卡,我会使用几个 SD 卡,在用满之前就会立即换一个,这样就会让我在一次旅途当中的照片散布在不同的 SD 卡上。
下图展示了这些设备之间如何相互连接。
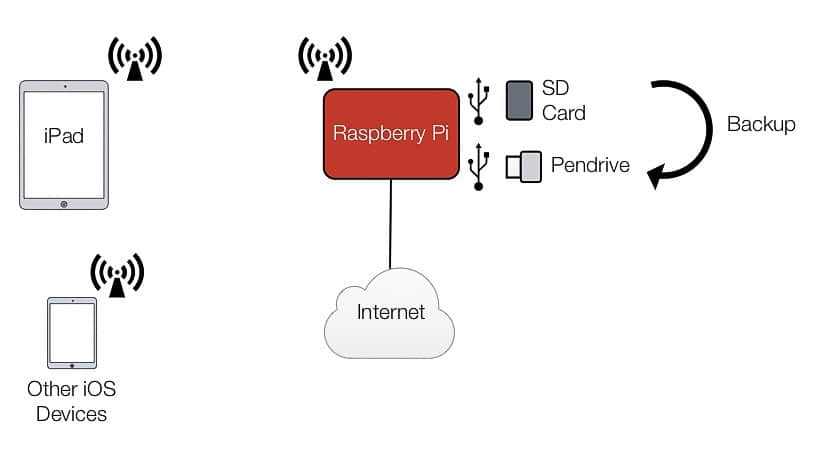
旅行时照片的备份-流程图
树莓派会作为一个安全的热点。它会创建一个自己的 WPA2 加密的 WIFI 网络,iPad Pro 会连入其中。虽然有很多在线教程教你如何创建 Ad Hoc 网络(计算机到计算机的单对单网络),还更简单一些,但是它的连接是不加密的,而且附件的设备很容易就能连接进去。因此我选择创建 WIFI 网络。
相机的 SD 卡通过 SD 读卡器插到树莓派 USB 端口之一,128G 的大容量优盘一直插在树莓派的另外一个 USB 端口上,我选择了一款闪迪的,因为体积比较小。主要的思路就是通过 Python 脚本把 SD 卡的照片备份到优盘上,备份过程是增量备份,每次脚本运行时都只有变化的(比如新拍摄的照片)部分会添加到备份文件夹中,所以这个过程特别快。如果你有很多的照片或者拍摄了很多 RAW 格式的照片,在就是个巨大的优势。iPad 将用来运行 Python 脚本,而且用来浏览 SD 卡和优盘的文件。
作为额外的好处,如果给树莓派连上一根能上网的网线(比如通过以太网口),那么它就可以共享互联网连接给那些通过 WIFI 连入的设备。
1. 树莓派的设置
这部分需要你卷起袖子亲自动手了,我们要用到 Raspbian 的命令行模式,我会尽可能详细的介绍,方便大家进行下去。
安装和配置 Raspbian
给树莓派连接鼠标、键盘和 LCD 显示器,将 SD 卡插到树莓派上,按照树莓派官网的步骤安装 Raspbian。
安装完后,打开 Raspbian 的终端,执行下面的命令:
sudo apt-get update
sudo apt-get upgrade
这将升级机器上所有的软件到最新,我将树莓派连接到本地网络,而且为了安全更改了默认的密码。
Raspbian 默认开启了 SSH,这样所有的设置可以在一个远程的设备上完成。我也设置了 RSA 验证,但这是可选的功能,可以在这里查看更多信息。
这是一个在 Mac 上在 iTerm 里建立 SSH 连接到树莓派上的截图14。(LCTT 译注:原文图丢失。)
建立 WPA2 加密的 WIFI AP
安装过程基于这篇文章,根据我的情况进行了调整。
1. 安装软件包
我们需要安装下面的软件包:
sudo apt-get install hostapd
sudo apt-get install dnsmasq
hostapd 用来使用内置的 WiFi 来创建 AP,dnsmasp 是一个组合的 DHCP 和 DNS 服务其,很容易设置。
2. 编辑 dhcpcd.conf
通过以太网连接树莓派,树莓派上的网络接口配置由 dhcpd 控制,因此我们首先忽略这一点,将 wlan0 设置为一个静态的 IP。
用 sudo nano /etc/dhcpcd.conf 命令打开 dhcpcd 的配置文件,在最后一行添加上如下内容:
denyinterfaces wlan0
注意:它必须放在如果已经有的其它接口行之上。
3. 编辑接口
现在设置静态 IP,使用 sudo nano /etc/network/interfaces 打开接口配置文件,按照如下信息编辑wlan0部分:
allow-hotplug wlan0
iface wlan0 inet static
address 192.168.1.1
netmask 255.255.255.0
network 192.168.1.0
broadcast 192.168.1.255
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
同样,然后 wlan1 编辑如下:
#allow-hotplug wlan1
#iface wlan1 inet manual
# wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
重要: 使用 sudo service dhcpcd restart 命令重启 dhcpd服务,然后用 sudo ifdown eth0; sudo ifup wlan0 命令来重载wlan0的配置。
4. 配置 Hostapd
接下来,我们需要配置 hostapd,使用 sudo nano /etc/hostapd/hostapd.conf 命令创建一个新的配置文件,内容如下:
interface=wlan0
# Use the nl80211 driver with the brcmfmac driver
driver=nl80211
# This is the name of the network
ssid=YOUR_NETWORK_NAME_HERE
# Use the 2.4GHz band
hw_mode=g
# Use channel 6
channel=6
# Enable 802.11n
ieee80211n=1
# Enable QoS Support
wmm_enabled=1
# Enable 40MHz channels with 20ns guard interval
ht_capab=[HT40][SHORT-GI-20][DSSS_CCK-40]
# Accept all MAC addresses
macaddr_acl=0
# Use WPA authentication
auth_algs=1
# Require clients to know the network name
ignore_broadcast_ssid=0
# Use WPA2
wpa=2
# Use a pre-shared key
wpa_key_mgmt=WPA-PSK
# The network passphrase
wpa_passphrase=YOUR_NEW_WIFI_PASSWORD_HERE
# Use AES, instead of TKIP
rsn_pairwise=CCMP
配置完成后,我们需要告诉dhcpcd 在系统启动运行时到哪里寻找配置文件。 使用 sudo nano /etc/default/hostapd 命令打开默认配置文件,然后找到#DAEMON_CONF="" 替换成DAEMON_CONF="/etc/hostapd/hostapd.conf"。
5. 配置 Dnsmasq
自带的 dnsmasp 配置文件包含很多信息方便你使用它,但是我们不需要那么多选项,我建议把它移动到别的地方(而不要删除它),然后自己创建一个新文件:
sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.orig
sudo nano /etc/dnsmasq.conf
粘贴下面的信息到新文件中:
interface=wlan0 # Use interface wlan0
listen-address=192.168.1.1 # Explicitly specify the address to listen on
bind-interfaces # Bind to the interface to make sure we aren't sending things elsewhere
server=8.8.8.8 # Forward DNS requests to Google DNS
domain-needed # Don't forward short names
bogus-priv # Never forward addresses in the non-routed address spaces.
dhcp-range=192.168.1.50,192.168.1.100,12h # Assign IP addresses in that range with a 12 hour lease time
6. 设置 IPv4 转发
最后我们需要做的事就是配置包转发,用 sudo nano /etc/sysctl.conf 命令打开 sysctl.conf 文件,将包含 net.ipv4.ip_forward=1的那一行之前的#号删除,它将在下次重启时生效。
我们还需要给连接到树莓派的设备通过 WIFI 分享互联网连接,做一个 wlan0和 eth0 之间的 NAT。我们可以参照下面的脚本来实现。
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
sudo iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
sudo iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
我命名这个脚本名为 hotspot-boot.sh,然后让它可以执行:
sudo chmod 755 hotspot-boot.sh
该脚本应该在树莓派启动的时候运行。有很多方法实现,下面是我实现的方式:
- 把文件放到
/home/pi/scripts目录下。 - 输入
sudo nano /etc/rc.local命令编辑 rc.local 文件,将运行该脚本的命令放到 exit 0之前。(更多信息参照这里)。
编辑后rc.local看起来像这样:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
# Print the IP address
_IP=$(hostname -I) || true
if [ "$_IP" ]; then
printf "My IP address is %s\n" "$_IP"
fi
sudo /home/pi/scripts/hotspot-boot.sh &
exit 0
安装 Samba 服务和 NTFS 兼容驱动
我们要安装下面几个软件来启用 samba 协议,使文件浏览器能够访问树莓派分享的文件夹,ntfs-3g 可以使我们能够访问移动硬盘中 ntfs 文件系统的文件。
sudo apt-get install ntfs-3g
sudo apt-get install samba samba-common-bin
你可以参照这些文档来配置 Samba。
重要提示:参考的文档介绍的是挂载外置硬盘到树莓派上,我们不这样做,是因为在这篇文章写作的时候,树莓派在启动时的 auto-mounts 功能同时将 SD 卡和优盘挂载到/media/pi/上,该文章有一些多余的功能我们也不会采用。
2. Python 脚本
树莓派配置好后,我们需要开发脚本来实际拷贝和备份照片。注意,这个脚本只是提供了特定的自动化备份进程,如果你有基本的 Linux/树莓派命令行操作的技能,你可以 ssh 进树莓派,然后创建需要的文件夹,使用cp或rsync命令拷贝你自己的照片从一个设备到另外一个设备上。在脚本里我们用rsync命令,这个命令比较可靠而且支持增量备份。
这个过程依赖两个文件,脚本文件自身和backup_photos.conf这个配置文件,后者只有几行包含被挂载的目的驱动器(优盘)和应该挂载到哪个目录,它看起来是这样的:
mount folder=/media/pi/
destination folder=PDRIVE128GB
重要提示:在这个符号=前后不要添加多余的空格,否则脚本会失效。
下面是这个 Python 脚本,我把它命名为backup_photos.py,把它放到了/home/pi/scripts/目录下,我在每行都做了注释可以方便的查看各行的功能。
#!/usr/bin/python3
import os
import sys
from sh import rsync
'''
脚本将挂载到 /media/pi 的 SD 卡上的内容复制到目的磁盘的同名目录下,目的磁盘的名字在 .conf文件里定义好了。
Argument: label/name of the mounted SD Card.
'''
CONFIG_FILE = '/home/pi/scripts/backup_photos.conf'
ORIGIN_DEV = sys.argv[1]
def create_folder(path):
print ('attempting to create destination folder: ',path)
if not os.path.exists(path):
try:
os.mkdir(path)
print ('Folder created.')
except:
print ('Folder could not be created. Stopping.')
return
else:
print ('Folder already in path. Using that instead.')
confFile = open(CONFIG_FILE,'rU')
#重要:: rU 选项将以统一换行模式打开文件,
#所以 \n 和/或 \r 都被识别为一个新行。
confList = confFile.readlines()
confFile.close()
for line in confList:
line = line.strip('\n')
try:
name , value = line.split('=')
if name == 'mount folder':
mountFolder = value
elif name == 'destination folder':
destDevice = value
except ValueError:
print ('Incorrect line format. Passing.')
pass
destFolder = mountFolder+destDevice+'/'+ORIGIN_DEV
create_folder(destFolder)
print ('Copying files...')
# 取消这行备注将删除不在源处的文件
# rsync("-av", "--delete", mountFolder+ORIGIN_DEV, destFolder)
rsync("-av", mountFolder+ORIGIN_DEV+'/', destFolder)
print ('Done.')
3. iPad Pro 的配置
因为重活都由树莓派干了,文件不通过 iPad Pro 传输,这比我之前尝试的一种方案有巨大的优势。我们在 iPad 上只需要安装上 Prompt2 来通过 SSH 连接树莓派就行了,这样你既可以运行 Python 脚本也可以手动复制文件了。
iPad 用 Prompt2 通过 SSH 连接树莓派
因为我们安装了 Samba,我们可以以更图形化的方式访问连接到树莓派的 USB 设备,你可以看视频,在不同的设备之间复制和移动文件,文件浏览器对于这种用途非常完美。(LCTT 译注:原文视频丢失。)
4. 将它们结合在一起
我们假设SD32GB-03是连接到树莓派 USB 端口之一的 SD 卡的卷标,PDRIVE128GB是那个优盘的卷标,也连接到设备上,并在上面指出的配置文件中定义好。如果我们想要备份 SD 卡上的图片,我们需要这么做:
- 给树莓派加电打开,将驱动器自动挂载好。
- 连接树莓派配置好的 WIFI 网络。
- 用 Prompt2 这个 app 通过 SSH 连接到树莓派。
- 连接好后输入下面的命令:
python3 backup_photos.py SD32GB-03
首次备份需要一些时间,这依赖于你的 SD 卡使用了多少容量。这意味着你需要一直保持树莓派和 iPad 设备连接不断,你可以在脚本运行之前通过 nohup 命令解决:
nohup python3 backup_photos.py SD32GB-03 &
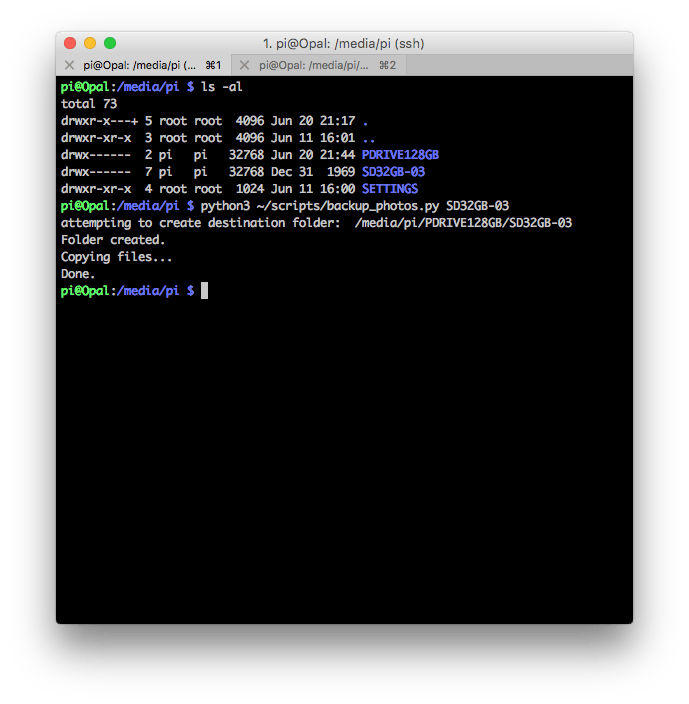
运行完成的脚本如图所示
未来的定制
我在树莓派上安装了 vnc 服务,这样我可以通过其它计算机或在 iPad 上用 Remoter App连接树莓派的图形界面,我安装了 BitTorrent Sync 用来远端备份我的图片,当然需要先设置好。当我有了可以运行的解决方案之后,我会补充我的文章。
你可以在下面发表你的评论和问题,我会在此页下面回复。
via: http://www.movingelectrons.net/blog/2016/06/26/backup-photos-while-traveling-with-a-raspberry-pi.html
作者:Lenin 译者:jiajia9linuxer 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出









{kind=link}