一文了解 Kubernetes 是什么?

这是一篇 Kubernetes 的概览。
Kubernetes 是一个自动化部署、伸缩和操作应用程序容器的开源平台。
使用 Kubernetes,你可以快速、高效地满足用户以下的需求:
- 快速精准地部署应用程序
- 即时伸缩你的应用程序
- 无缝展现新特征
- 限制硬件用量仅为所需资源
我们的目标是培育一个工具和组件的生态系统,以减缓在公有云或私有云中运行的程序的压力。
Kubernetes 的优势
- 可移动: 公有云、私有云、混合云、多态云
- 可扩展: 模块化、插件化、可挂载、可组合
- 自修复: 自动部署、自动重启、自动复制、自动伸缩
Google 公司于 2014 年启动了 Kubernetes 项目。Kubernetes 是在 Google 的长达 15 年的成规模的产品级任务的经验下构建的,结合了来自社区的最佳创意和实践经验。
为什么选择容器?
想要知道你为什么要选择使用 容器?
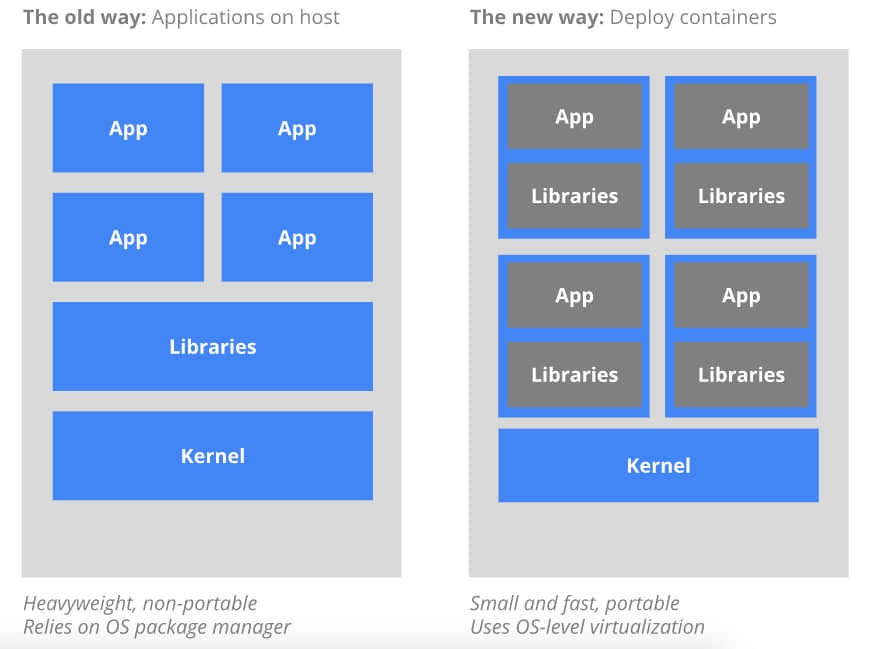
程序部署的传统方法是指通过操作系统包管理器在主机上安装程序。这样做的缺点是,容易混淆程序之间以及程序和主机系统之间的可执行文件、配置文件、库、生命周期。为了达到精准展现和精准回撤,你可以搭建一台不可变的虚拟机镜像。但是虚拟机体量往往过于庞大而且不可转移。
容器部署的新的方式是基于操作系统级别的虚拟化,而非硬件虚拟化。容器彼此是隔离的,与宿主机也是隔离的:它们有自己的文件系统,彼此之间不能看到对方的进程,分配到的计算资源都是有限制的。它们比虚拟机更容易搭建。并且由于和基础架构、宿主机文件系统是解耦的,它们可以在不同类型的云上或操作系统上转移。
正因为容器又小又快,每一个容器镜像都可以打包装载一个程序。这种一对一的“程序 - 镜像”联系带给了容器诸多便捷。有了容器,静态容器镜像可以在编译/发布时期创建,而非部署时期。因此,每个应用不必再等待和整个应用栈其它部分进行整合,也不必和产品基础架构环境之间进行妥协。在编译/发布时期生成容器镜像建立了一个持续地把开发转化为产品的环境。相似地,容器远比虚拟机更加透明,尤其在设备监控和管理上。这一点,在容器的进程生命周期被基础架构管理而非被容器内的进程监督器隐藏掉时,尤为显著。最终,随着每个容器内都装载了单一的程序,管理容器就等于管理或部署整个应用。
容器优势总结:
- 敏捷的应用创建与部署:相比虚拟机镜像,容器镜像的创建更简便、更高效。
- 持续的开发、集成,以及部署:在快速回滚下提供可靠、高频的容器镜像编译和部署(基于镜像的不可变性)。
- 开发与运营的关注点分离:由于容器镜像是在编译/发布期创建的,因此整个过程与基础架构解耦。
- 跨开发、测试、产品阶段的环境稳定性:在笔记本电脑上的运行结果和在云上完全一致。
- 在云平台与 OS 上分发的可转移性:可以在 Ubuntu、RHEL、CoreOS、预置系统、Google 容器引擎,乃至其它各类平台上运行。
- 以应用为核心的管理: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
- 松散耦联、分布式、弹性、无拘束的微服务:整个应用被分散为更小、更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型的单用途机器上的臃肿的单一应用栈。
- 资源隔离:增加程序表现的可预见性。
- 资源利用率:高效且密集。
为什么我需要 Kubernetes,它能做什么?
至少,Kubernetes 能在实体机或虚拟机集群上调度和运行程序容器。而且,Kubernetes 也能让开发者斩断联系着实体机或虚拟机的“锁链”,从以主机为中心的架构跃至以容器为中心的架构。该架构最终提供给开发者诸多内在的优势和便利。Kubernetes 提供给基础架构以真正的以容器为中心的开发环境。
Kubernetes 满足了一系列产品内运行程序的普通需求,诸如:
- 协调辅助进程,协助应用程序整合,维护一对一“程序 - 镜像”模型。
- 挂载存储系统
- 分布式机密信息
- 检查程序状态
- 复制应用实例
- 使用横向荚式自动缩放
- 命名与发现
- 负载均衡
- 滚动更新
- 资源监控
- 访问并读取日志
- 程序调试
- 提供验证与授权
以上兼具平台即服务(PaaS)的简化和基础架构即服务(IaaS)的灵活,并促进了在平台服务提供商之间的迁移。
Kubernetes 是一个什么样的平台?
虽然 Kubernetes 提供了非常多的功能,总会有更多受益于新特性的新场景出现。针对特定应用的工作流程,能被流水线化以加速开发速度。特别的编排起初是可接受的,这往往需要拥有健壮的大规模自动化机制。这也是为什么 Kubernetes 也被设计为一个构建组件和工具的生态系统的平台,使其更容易地部署、缩放、管理应用程序。
标签 可以让用户按照自己的喜好组织资源。 注释 让用户在资源里添加客户信息,以优化工作流程,为管理工具提供一个标示调试状态的简单方法。
此外,Kubernetes 控制面板是由开发者和用户均可使用的同样的 API 构建的。用户可以编写自己的控制器,比如 调度器 ,使用可以被通用的命令行工具识别的他们自己的 API。
这种设计让大量的其它系统也能构建于 Kubernetes 之上。
Kubernetes 不是什么?
Kubernetes 不是传统的、全包容的平台即服务(Paas)系统。它尊重用户的选择,这很重要。
Kubernetes:
- 并不限制支持的程序类型。它并不检测程序的框架 (例如,Wildfly),也不限制运行时支持的语言集合 (比如, Java、Python、Ruby),也不仅仅迎合 12 因子应用程序,也不区分 应用 与 服务 。Kubernetes 旨在支持尽可能多种类的工作负载,包括无状态的、有状态的和处理数据的工作负载。如果某程序在容器内运行良好,它在 Kubernetes 上只可能运行地更好。
- 不提供中间件(例如消息总线)、数据处理框架(例如 Spark)、数据库(例如 mysql),也不把集群存储系统(例如 Ceph)作为内置服务。但是以上程序都可以在 Kubernetes 上运行。
- 没有“点击即部署”这类的服务市场存在。
- 不部署源代码,也不编译程序。持续集成 (CI) 工作流程是不同的用户和项目拥有其各自不同的需求和表现的地方。所以,Kubernetes 支持分层 CI 工作流程,却并不监听每层的工作状态。
- 允许用户自行选择日志、监控、预警系统。( Kubernetes 提供一些集成工具以保证这一概念得到执行)
- 不提供也不管理一套完整的应用程序配置语言/系统(例如 jsonnet)。
- 不提供也不配合任何完整的机器配置、维护、管理、自我修复系统。
另一方面,大量的 PaaS 系统运行在 Kubernetes 上,诸如 Openshift、Deis,以及 Eldarion。你也可以开发你的自定义 PaaS,整合上你自选的 CI 系统,或者只在 Kubernetes 上部署容器镜像。
因为 Kubernetes 运营在应用程序层面而不是在硬件层面,它提供了一些 PaaS 所通常提供的常见的适用功能,比如部署、伸缩、负载平衡、日志和监控。然而,Kubernetes 并非铁板一块,这些默认的解决方案是可供选择,可自行增加或删除的。
而且, Kubernetes 不只是一个编排系统 。事实上,它满足了编排的需求。 编排 的技术定义是,一个定义好的工作流程的执行:先做 A,再做 B,最后做 C。相反地, Kubernetes 囊括了一系列独立、可组合的控制流程,它们持续驱动当前状态向需求的状态发展。从 A 到 C 的具体过程并不唯一。集中化控制也并不是必须的;这种方式更像是编舞。这将使系统更易用、更高效、更健壮、复用性、扩展性更强。
Kubernetes 这个单词的含义?k8s?
Kubernetes 这个单词来自于希腊语,含义是 舵手 或 领航员 。其词根是 governor 和 cybernetic。 K8s 是它的缩写,用 8 字替代了“ubernete”。
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
作者:kubernetes.io 译者:songshuang00 校对:wxy