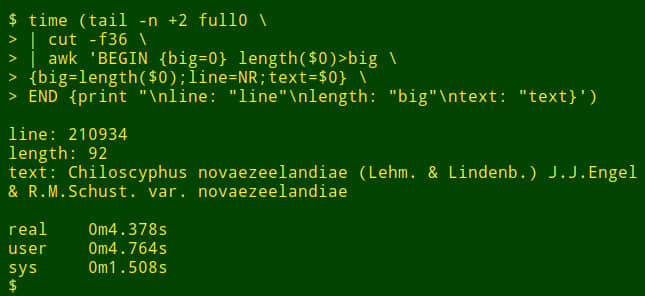
按照这些简单的步骤在你的 Linux、Mac 或 Windows 桌面上安装 Docker CE。

在上一篇文章中,我们学习了容器世界的一些基本术语。当我们运行命令并在后续文章中使用其中一些术语时,这些背景信息将会派上用场,包括这篇文章。本文将介绍在桌面 Linux、 macOS 和 Windows 上安装 Docker,它适用于想要开始使用 Docker 容器的初学者。唯一的先决条件是你对命令行界面满意。
为什么我在本地机器上需要 Docker CE?
作为一个新用户,你很可能想知道为什么你在本地系统上需要容器。难道它们不是作为微服务在云和服务器中运行吗?尽管容器长期以来一直是 Linux 世界的一部分,但 Docker 才真正使容器的工具和技术步入使用。
Docker 容器最大的优点是可以使用本地机器进行开发和测试。你在本地系统上创建的容器映像可以在“任何位置”运行。开发人员和操作人员之间不再会为应用程序在开发系统上运行良好但生产环境中出现问题而产生纷争。
而这个关键是,要创建容器化的应用程序,你必须能够在本地系统上运行和创建容器。
你可以使用以下三个平台中的任何一个 —— 桌面 Linux、 Windows 或 macOS 作为容器的开发平台。一旦 Docker 在这些系统上成功运行,你将可以在不同的平台上使用相同的命令。因此,接下来你运行的操作系统无关紧要。
这就是 Docker 之美。
让我们开始吧
现在有两个版本的 Docker:Docker 企业版(EE)和 Docker 社区版(CE)。我们将使用 Docker 社区版,这是一个免费的 Docker 版本,面向想要开始使用 Docker 的开发人员和爱好者。
Docker CE 有两个版本:stable 和 edge。顾名思义,stable(稳定)版本会为你提供经过充分测试的季度更新,而 edge 版本每个月都会提供新的更新。经过进一步的测试之后,这些边缘特征将被添加到稳定版本中。我建议新用户使用 stable 版本。
Docker CE 支持 macOS、 Windows 10、 Ubuntu 14.04/16.04/17.04/17.10、 Debian 7.7/8/9/10、 Fedora 25/26/27 和 CentOS。虽然你可以下载 Docker CE 二进制文件并安装到桌面 Linux 上,但我建议添加仓库源以便继续获得修补程序和更新。
在桌面 Linux 上安装 Docker CE
你不需要一个完整的桌面 Linux 来运行 Docker,你也可以将它安装在最小的 Linux 服务器上,即你可以在一个虚拟机中运行。在本教程中,我将在我的主系统的 Fedora 27 和 Ubuntu 17.04 上运行它。
在 Ubuntu 上安装
首先,运行系统更新,以便你的 Ubuntu 软件包完全更新:
$ sudo apt-get update
现在运行系统升级:
$ sudo apt-get dist-upgrade
然后安装 Docker PGP 密钥:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
Update the repository info again:
$ sudo apt-get update
现在安装 Docker CE:
$ sudo apt-get install docker-ce
一旦安装完成,Docker CE 就会在基于 Ubuntu 的系统上自动运行,让我们来检查它是否在运行:
$ sudo systemctl status docker
你应该得到以下输出:
docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2017-12-28 15:06:35 EST; 19min ago
Docs: https://docs.docker.com
Main PID: 30539 (dockerd)
由于 Docker 安装在你的系统上,你现在可以使用 Docker CLI(命令行界面)运行 Docker 命令。像往常一样,我们运行 ‘Hello World’ 命令:
$ sudo docker run hello-world
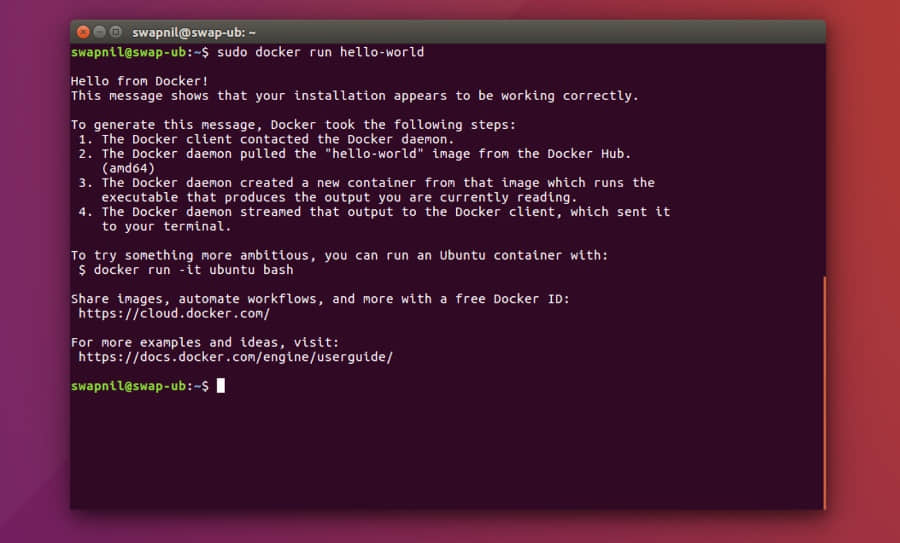
恭喜!在你的 Ubuntu 系统上正在运行着 Docker。
在 Fedora 上安装 Docker CE
Fedora 27 上的情况有些不同。在 Fedora 上,你首先需要安装 def-plugins-core 包,这将允许你从 CLI 管理你的 DNF 包。
$ sudo dnf -y install dnf-plugins-core
现在在你的系统上安装 Docker 仓库:
$ sudo dnf config-manager \
--add-repo \
https://download.docker.com/linux/fedora/docker-ce.repo
It’s time to install Docker CE:
$ sudo dnf install docker-ce
与 Ubuntu 不同,Docker 不会在 Fedora 上自动启动。那么让我们启动它:
$ sudo systemctl start docker
你必须在每次重新启动后手动启动 Docker,因此让我们将其配置为在重新启动后自动启动。$ systemctl enable docker 就行。现在该运行 Hello World 命令了:
$ sudo docker run hello-world
恭喜,在你的 Fedora 27 系统上正在运行着 Docker。
解除 root
你可能已经注意到你必须使用 sudo 来运行 docker 命令。这是因为 Docker 守护进程与 UNIX 套接字绑定,而不是 TCP 端口,套接字由 root 用户拥有。所以,你需要 sudo 权限才能运行 docker 命令。你可以将系统用户添加到 docker 组,这样它就不需要 sudo 了:
$ sudo groupadd docker
在大多数情况下,在安装 Docker CE 时会自动创建 Docker 用户组,因此你只需将用户添加到该组中即可:
$ sudo usermod -aG docker $USER
为了测试该组是否已经成功添加,根据用户名运行 groups 命令:
$ groups swapnil
(这里,swapnil 是用户名。)
这是在我系统上的输出:
swapnil : swapnil adm cdrom sudo dip plugdev lpadmin sambashare docker
你可以看到该用户也属于 docker 组。注销系统,这样组就会生效。一旦你再次登录,在不使用 sudo 的情况下试试 Hello World 命令:
$ docker run hello-world
你可以通过运行以下命令来查看关于 Docker 的安装版本以及更多系统信息:
$ docker info
在 macOS 和 Windows 上安装 Docker CE
你可以在 macOS 和 Windows 上很轻松地安装 Docker CE(和 EE)。下载官方为 macOS 提供的 Docker 安装包,在 macOS 上安装应用程序的方式是只需将它们拖到 Applications 目录即可。一旦文件被复制,从 spotlight(LCTT 译注:mac 下的搜索功能)下打开 Docker 开始安装。一旦安装,Docker 将自动启动,你可以在 macOS 的顶部看到它。
macOS 是类 UNIX 系统,所以你可以简单地打开终端应用程序,并开始使用 Docker 命令。测试 hello world 应用:
$ docker run hello-world
恭喜,你已经在你的 macOS 上运行了 Docker。
在 Windows 10 上安装 Docker
你需要最新版本的 Windows 10 Pro 或 Server 才能在它上面安装或运行 Docker。如果你没有完全更新,Windows 将不会安装 Docker。我在 Windows 10 系统上遇到了错误,必须运行系统更新。我的版本还很落后,我出现了这个 bug。所以,如果你无法在 Windows 上安装 Docker,只要知道并不是只有你一个。仔细检查该 bug 以找到解决方案。
一旦你在 Windows 上安装 Docker 后,你可以通过 WSL 使用 bash shell,或者使用 PowerShell 来运行 Docker 命令。让我们在 PowerShell 中测试 “Hello World” 命令:
PS C:\Users\swapnil> docker run hello-world
恭喜,你已经在 Windows 上运行了 Docker。
在下一篇文章中,我们将讨论如何从 DockerHub 中拉取镜像并在我们的系统上运行容器。我们还会讨论推送我们自己的容器到 Docker Hub。
via: https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
作者:SWAPNIL BHARTIYA 选题:lujun9972 译者:MjSeven 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出