这篇教程将帮你快速了解 Linux 文件系统。

早在 1996 年,在真正理解文件系统的结构之前,我就学会了如何在我崭新的 Linux 上安装软件。这是一个问题,但对程序来说不是大问题,因为即使我不知道实际的可执行文件在哪里,它们也会神奇地工作。问题在于文档。
你知道,那时候,Linux 不是像今天这样直观、用户友好的系统。你必须读很多东西。你必须知道你的 CRT 显示器的扫描频率以及拨号调制解调器的噪音来龙去脉,以及其他数以百计的事情。 我很快就意识到我需要花一些时间来掌握目录的组织方式以及 /etc(不是用于“其它”文件),/usr(不是用于“用户”文件)和 /bin (不是“垃圾桶”)的意思。
本教程将帮助你比我当时更快地了解这些。
结构
从终端窗口探索 Linux 文件系统是有道理的,这并不是因为作者是一个脾气暴躁的老人,并且对新孩子和他们漂亮的图形工具不以为然(尽管某些事实如此),而是因为终端,尽管只是文本界面,才是更好地显示 Linux 目录树结构的工具。
事实上,帮助你了解这一切的、应该首先安装的第一个工具的名为:tree。如果你正在使用 Ubuntu 或 Debian ,你可以:
sudo apt install tree
在 Red Hat 或 Fedora :
sudo dnf install tree
对于 SUSE/openSUSE 可以使用 zypper:
sudo zypper install tree
对于使用 Arch (Manjaro,Antergos,等等)使用:
sudo pacman -S tree
……等等。
一旦安装好,在终端窗口运行 tree 命令:
tree /
上述指令中的 / 指的是根目录。系统中的其他目录都是从根目录分支而出,当你运行 tree 命令,并且告诉它从根目录开始,那么你就可以看到整个目录树,系统中的所有目录及其子目录,还有它们的文件。
如果你已经使用你的系统有一段时间了,这可能需要一段时间,因为即使你自己还没有生成很多文件,Linux 系统及其应用程序总是在记录、缓存和存储各种临时文件。文件系统中的条目数量会快速增长。
不过,不要感到不知所措。 相反,试试这个:
tree -L 1 /
你应该看到如图 1 所示。
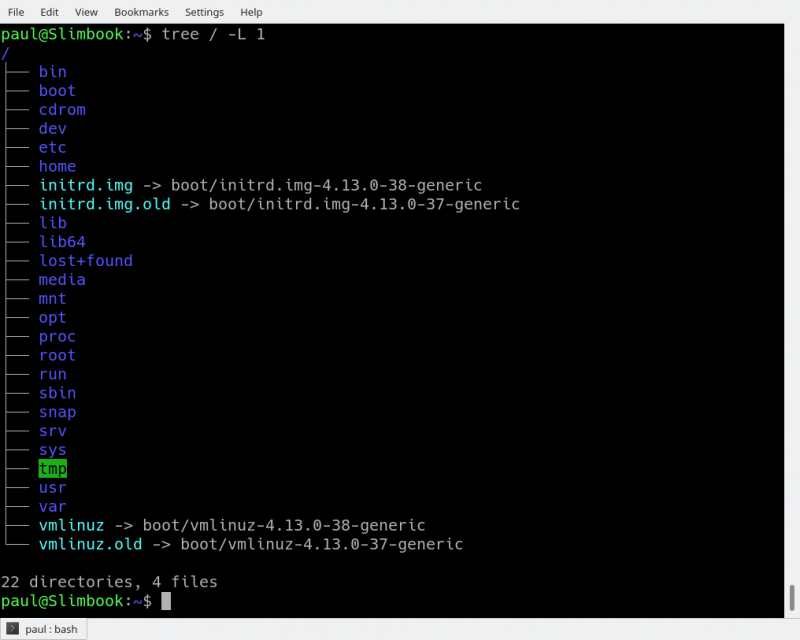
tree
上面的指令可以翻译为“只显示以 /(根目录) 开头的目录树的第一级”。 -L 选项告诉树你想看到多少层目录。
大多数 Linux 发行版都会向你显示与你在上图中看到的相同或非常类似的结构。 这意味着,即使你现在感到困惑,掌握这一点,你将掌握大部分(如果不是全部的话)全世界的 Linux 文件系统。
为了让你开始走上掌控之路,让我们看看每个目录的用途。 当我们查看每一个目录的时候,你可以使用 ls 来查看他们的内容。
目录
从上到下,你所看到的目录如下
/bin
/bin 目录是包含一些二进制文件的目录,即可以运行的一些应用程序。 你会在这个目录中找到上面提到的 ls 程序,以及用于新建和删除文件和目录、移动它们基本工具。还有其它一些程序,等等。文件系统树的其他部分有更多的 bin 目录,但我们将在一会儿讨论这些目录。
/boot
/boot 目录包含启动系统所需的文件。我必须要说吗? 好吧,我会说:不要动它! 如果你在这里弄乱了其中一个文件,你可能无法运行你的 Linux,修复被破坏的系统是非常痛苦的一件事。 另一方面,不要太担心无意中破坏系统:你必须拥有超级用户权限才能执行此操作。
/dev
/dev 目录包含设备文件。 其中许多是在启动时或甚至在运行时生成的。 例如,如果你将新的网络摄像头或 USB 随身碟连接到你的机器中,则会自动弹出一个新的设备条目。
/etc
/etc 的目录名称会让人变得非常的困惑。/etc 得名于最早的 Unix 系统们,它的字面意思是 “etcetera”(诸如此类) ,因为它是系统文件管理员不确定在哪里放置的文件的垃圾场。
现在,说 /etc 是“ 要配置的所有内容 ”更为恰当,因为它包含大部分(如果不是全部的话)的系统配置文件。 例如,包含系统名称、用户及其密码、网络上计算机名称以及硬盘上分区的安装位置和时间的文件都在这里。 再说一遍,如果你是 Linux 的新手,最好是不要在这里接触太多,直到你对系统的工作有更好的理解。
/home
/home 是你可以找到用户个人目录的地方。在我的情况下,/home 下有两个目录:/home/paul,其中包含我所有的东西;另外一个目录是 /home/guest 目录,以防有客人需要使用我的电脑。
/lib
/lib 是库文件所在的地方。库是包含应用程序可以使用的代码文件。它们包含应用程序用于在桌面上绘制窗口、控制外围设备或将文件发送到硬盘的代码片段。
在文件系统周围散布着更多的 lib 目录,但是这个直接挂载在 / 的 /lib 目录是特殊的,除此之外,它包含了所有重要的内核模块。 内核模块是使你的显卡、声卡、WiFi、打印机等工作的驱动程序。
/media
在 /media 目录中,当你插入外部存储器试图访问它时,将自动挂载它。与此列表中的大多数其他项目不同,/media 并不追溯到 1970 年代,主要是因为当计算机正在运行而动态地插入和检测存储(U 盘、USB 硬盘、SD 卡、外部 SSD 等),这是近些年才发生的事。
/mnt
然而,/mnt 目录是一些过去的残余。这是你手动挂载存储设备或分区的地方。现在不常用了。
/opt
/opt 目录通常是你编译软件(即,你从源代码构建,并不是从你的系统的软件库中安装软件)的地方。应用程序最终会出现在 /opt/bin 目录,库会在 /opt/lib 目录中出现。
稍微的题外话:应用程序和库的另一个地方是 /usr/local,在这里安装软件时,也会有 /usr/local/bin 和 /usr/local/lib 目录。开发人员如何配置文件来控制编译和安装过程,这就决定了软件安装到哪个地方。
/proc
/proc,就像 /dev 是一个虚拟目录。它包含有关你的计算机的信息,例如关于你的 CPU 和你的 Linux 系统正在运行的内核的信息。与 /dev 一样,文件和目录是在计算机启动或运行时生成的,因为你的系统正在运行且会发生变化。
/root
/root 是系统的超级用户(也称为“管理员”)的主目录。 它与其他用户的主目录是分开的,因为你不应该动它。 所以把自己的东西放在你自己的目录中,伙计们。
/run
/run 是另一个新出现的目录。系统进程出于自己不可告人的原因使用它来存储临时数据。这是另一个不要动它的文件夹。
/sbin
/sbin 与 /bin 类似,但它包含的应用程序只有超级用户(即首字母的 s )才需要。你可以使用 sudo 命令使用这些应用程序,该命令暂时允许你在许多 Linux 发行版上拥有超级用户权限。/sbin 目录通常包含可以安装、删除和格式化各种东西的工具。你可以想象,如果你使用不当,这些指令中有一些是致命的,所以要小心处理。
/usr
/usr 目录是在 UNIX 早期用户的主目录所处的地方。然而,正如我们上面看到的,现在 /home 是用户保存他们的东西的地方。如今,/usr 包含了大量目录,而这些目录又包含了应用程序、库、文档、壁纸、图标和许多其他需要应用程序和服务共享的内容。
你还可以在 /usr 目录下找到 bin,sbin,lib 目录,它们与挂载到根目录下的那些有什么区别呢?现在的区别不是很大。在早期,/bin 目录(挂载在根目录下的)只会包含一些基本的命令,例如 ls、mv 和 rm ;这是一些在安装系统的时候就会预装的一些命令,用于维护系统的一个基本的命令。 而 /usr/bin 目录则包含了用户自己安装和用于工作的软件,例如文字处理器,浏览器和一些其他的软件。
但是许多现代的 Linux 发行版只是把所有的东西都放到 /usr/bin 中,并让 /bin 指向 /usr/bin,以防彻底删除它会破坏某些东西。因此,Debian、Ubuntu 和 Mint 仍然保持 /bin 和 /usr/bin (和 /sbin 和 /usr/sbin )分离;其他的,比如 Arch 和它衍生版,只是有一个“真实”存储二进制程序的目录,/usr/bin,其余的任何 bin 目录是指向 /usr/bin` 的“假”目录。
/srv
/srv 目录包含服务器的数据。如果你正在 Linux 机器上运行 Web 服务器,你网站的 HTML文件将放到 /srv/http(或 /srv/www)。 如果你正在运行 FTP 服务器,则你的文件将放到 /srv/ftp。
/sys
/sys 是另一个类似 /proc 和 /dev 的虚拟目录,它还包含连接到计算机的设备的信息。
在某些情况下,你还可以操纵这些设备。 例如,我可以通过修改存储在 /sys/devices/pci0000:00/0000:00:02.0/drm/card1/card1-eDP-1/intel_backlight/brightness 中的值来更改笔记本电脑屏幕的亮度(在你的机器上你可能会有不同的文件)。但要做到这一点,你必须成为超级用户。原因是,与许多其它虚拟目录一样,在 /sys 中打乱内容和文件可能是危险的,你可能会破坏系统。直到你确信你知道你在做什么。否则不要动它。
/tmp
/tmp 包含临时文件,通常由正在运行的应用程序放置。文件和目录通常(并非总是)包含应用程序现在不需要但以后可能需要的数据。
你还可以使用 /tmp 来存储你自己的临时文件 —— /tmp 是少数挂载到根目录下而你可以在不成为超级用户的情况下与它进行实际交互的目录之一。
/var
/var 最初被如此命名是因为它的内容被认为是 可变的 ,因为它经常变化。今天,它有点用词不当,因为还有许多其他目录也包含频繁更改的数据,特别是我们上面看到的虚拟目录。
不管怎样,/var 目录包含了放在 /var/log 子目录的日志文件之类。日志是记录系统中发生的事件的文件。如果内核中出现了什么问题,它将被记录到 /var/log 下的文件中;如果有人试图从外部侵入你的计算机,你的防火墙也将记录尝试。它还包含用于任务的假脱机程序。这些“任务”可以是你发送给共享打印机必须等待执行的任务,因为另一个用户正在打印一个长文档,或者是等待递交给系统上的用户的邮件。
你的系统可能还有一些我们上面没有提到的目录。例如,在屏幕截图中,有一个 /snap 目录。这是因为这张截图是在 Ubuntu 系统上截取的。Ubuntu 最近将 snap 包作为一种分发软件的方式。/snap 目录包含所有文件和从 snaps 安装的软件。
更深入的研究
这里仅仅谈了根目录,但是许多子目录都指向它们自己的一组文件和子目录。图 2 给出了基本文件系统的总体概念(图片是在 Paul Gardner 的 CC BY-SA 许可下提供的),Wikipedia 对每个目录的用途进行了总结。

图 2:标准 Unix 文件系统
要自行探索文件系统,请使用 cd 命令:cd将带你到你所选择的目录( cd 代表更改目录)。
如果你不知道你在哪儿,pwd会告诉你,你到底在哪里,( pwd 代表打印工作目录 ),同时 cd命令在没有任何选项或者参数的时候,将会直接带你到你自己的主目录,这是一个安全舒适的地方。
最后,cd ..将会带你到上一层目录,会使你更加接近根目录,如果你在 /usr/share/wallpapers 目录,然后你执行 cd .. 命令,你将会跳转到 /usr/share 目录
要查看目录里有什么内容,使用 ls 或这简单的使用 l 列出你所在目录的内容。
当然,你总是可以使用 tree 来获得目录中内容的概述。在 /usr/share 上试试——里面有很多有趣的东西。
总结
尽管 Linux 发行版之间存在细微差别,但它们的文件系统的布局非常相似。 你可以这么说:一旦你了解一个,你就会都了解了。 了解文件系统的最好方法就是探索它。 因此,伴随 tree ,ls 和 cd 进入未知的领域吧。
你不会只是因为查看文件系统就破坏了文件系统,因此请从一个目录移动到另一个目录并进行浏览。 很快你就会发现 Linux 文件系统及其布局的确很有意义,并且你会直观地知道在哪里可以找到应用程序,文档和其他资源。
通过 Linux 基金会和 edX 免费的 “Linux入门” 课程了解更多有关 Linux 的信息。
via: https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained
作者:PAUL BROWN 选题:lujun9972 译者:amwps290 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出





{kind=link}
{kind=link}