
在一个美好的夜晚,你的肚子拒绝消化你在晚餐吃的大块披萨,所以你不得不在睡梦中冲进洗手间。
在浴室里,当你在思考为什么会发生这种情况时,你听到一个来自通风口的低沉声音:“嘿,我是蝙蝠侠。”
这时,你会怎么做呢?
在你恐慌并处于关键时刻之前,蝙蝠侠说:“我需要你的帮助。我是一个超级极客,但我不懂 HTML。我需要用 HTML 写一封情书,你愿意帮助我吗?”
谁会拒绝蝙蝠侠的请求呢,对吧?所以让我们用 HTML 来写一封蝙蝠侠的情书。
你的第一个 HTML 文件
HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS Word 打开,.jpg 文件在图像查看器中打开一样,一个 .html 文件在浏览器中打开。
那么,让我们来创建一个 .html 文件。你可以在 Notepad 或其它任何编辑器中完成此任务,但我建议使用 VS Code。在这里下载并安装 VS Code。它是免费的,也是我唯一喜欢的微软产品。
在系统中创建一个目录,将其命名为 “HTML Practice”(不带引号)。在这个目录中,再创建一个名为 “Batman’s Love Letter”(不带引号)的目录,这将是我们的项目根目录。这意味着我们所有与这个项目相关的文件都会在这里。
打开 VS Code,按下 ctrl+n 创建一个新文件,按下 ctrl+s 保存文件。切换到 “Batman’s Love Letter” 文件夹并将其命名为 “loveletter.html”,然后单击保存。
现在,如果你在文件资源管理器中双击它,它将在你的默认浏览器中打开。我建议使用 Firefox 来进行 web 开发,但 Chrome 也可以。
让我们将这个过程与我们已经熟悉的东西联系起来。还记得你第一次拿到电脑吗?我做的第一件事是打开 MS Paint 并绘制一些东西。你在 Paint 中绘制一些东西并将其另存为图像,然后你可以在图像查看器中查看该图像。之后,如果要再次编辑该图像,你在 Paint 中重新打开它,编辑并保存它。
我们目前的流程非常相似。正如我们使用 Paint 创建和编辑图像一样,我们使用 VS Code 来创建和编辑 HTML 文件。就像我们使用图像查看器查看图像一样,我们使用浏览器来查看我们的 HTML 页面。
HTML 中的段落
我们有一个空的 HTML 文件,以下是蝙蝠侠想在他的情书中写的第一段。
“After all the battles we fought together, after all the difficult times we saw together, and after all the good and bad moments we’ve been through, I think it’s time I let you know how I feel about you.”
复制这些到 VS Code 中的 loveletter.html。单击 “View -> Toggle Word Wrap (alt+z)” 自动换行。
保存并在浏览器中打开它。如果它已经打开,单击浏览器中的刷新按钮。
瞧!那是你的第一个网页!
我们的第一段已准备就绪,但这不是在 HTML 中编写段落的推荐方法。我们有一种特定的方法让浏览器知道一个文本是一个段落。
如果你用 <p> 和 </p> 来包裹文本,那么浏览器将识别 <p> 和 </p> 中的文本是一个段落。我们这样做:
<p>After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.</p>
通过在 <p> 和 </p>中编写段落,你创建了一个 HTML 元素。一个网页就是 HTML 元素的集合。
让我们首先来认识一些术语:<p> 是开始标签,</p> 是结束标签,“p” 是标签名称。元素开始和结束标签之间的文本是元素的内容。
“style” 属性
在上面,你将看到文本覆盖屏幕的整个宽度。
我们不希望这样。没有人想要阅读这么长的行。让我们设定段落宽度为 550px。
我们可以通过使用元素的 style 属性来实现。你可以在其 style 属性中定义元素的样式(例如,在我们的示例中为宽度)。以下行将在 p 元素上创建一个空样式属性:
<p style="">...</p>
你看到那个空的 "" 了吗?这就是我们定义元素外观的地方。现在我们要将宽度设置为 550px。我们这样做:
<p style="width:550px;">
After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
我们将 width 属性设置为 550px,用冒号 : 分隔,以分号 ; 结束。
另外,注意我们如何将 <p> 和 </p> 放在单独的行中,文本内容用一个制表符缩进。像这样设置代码使其更具可读性。
HTML 中的列表
接下来,蝙蝠侠希望列出他所钦佩的人的一些优点,例如:
You complete my darkness with your light. I love:
- the way you see good in the worst things
- the way you handle emotionally difficult situations
- the way you look at Justice
I have learned a lot from you. You have occupied a special place in my heart over time.
这看起来很简单。
让我们继续,在 </p> 下面复制所需的文本:
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love:
- the way you see good in the worse
- the way you handle emotionally difficult situations
- the way you look at Justice
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
保存并刷新浏览器。

哇!这里发生了什么,我们的列表在哪里?
如果你仔细观察,你会发现没有显示换行符。在代码中我们在新的一行中编写列表项,但这些项在浏览器中显示在一行中。
如果你想在 HTML(新行)中插入换行符,你必须使用 <br>。让我们来使用 <br>,看看它长什么样:
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love: <br>
- the way you see good in the worse <br>
- the way you handle emotionally difficult situations <br>
- the way you look at Justice <br>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
保存并刷新:

好的,现在它看起来就像我们想要的那样!
另外,注意我们没有写一个 </br>。有些标签不需要结束标签(它们被称为自闭合标签)。
还有一件事:我们没有在两个段落之间使用 <br>,但第二个段落仍然是从一个新行开始,这是因为 <p> 元素会自动插入换行符。
我们使用纯文本编写列表,但是有两个标签可以供我们使用来达到相同的目的:<ul> and <li>。
让我们解释一下名字的意思:ul 代表 无序列表 ,li 代表 列表项目 。让我们使用它们来展示我们的列表:
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love:
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
在复制代码之前,注意差异部分:
- 我们删除了所有的
<br>,因为每个 <li> 会自动显示在新行中 - 我们将每个列表项包含在
<li> 和 </li> 之间 - 我们将所有列表项的集合包裹在
<ul> 和 </ul> 之间 - 我们没有像
<p> 元素那样定义 <ul> 元素的宽度。这是因为 <ul> 是 <p> 的子节点,<p> 已经被约束到 550px,所以 <ul> 不会超出这个范围。
让我们保存文件并刷新浏览器以查看结果:
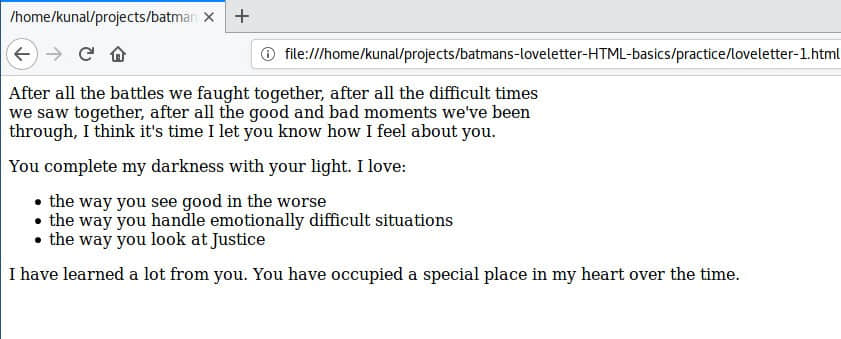
你会立即注意到在每个列表项之前显示了重点标志。我们现在不需要在每个列表项之前写 “-”。
经过仔细检查,你会注意到最后一行超出 550px 宽度。这是为什么?因为 HTML 不允许 <ul> 元素出现在 <p> 元素中。让我们将第一行和最后一行放在单独的 <p> 元素中:
<p style="width:550px;">
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p style="width:550px;">
You complete my darkness with your light. I love:
</p>
<ul style="width:550px;">
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p style="width:550px;">
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
保存并刷新。
注意,这次我们还定义了 <ul> 元素的宽度。那是因为我们现在已经将 <ul> 元素放在了 <p> 元素之外。
定义情书中所有元素的宽度会变得很麻烦。我们有一个特定的元素用于此目的:<div> 元素。一个 <div> 元素就是一个通用容器,用于对内容进行分组,以便轻松设置样式。
让我们用 <div> 元素包装整个情书,并为其赋予宽度:550px 。
<div style="width:550px;">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
棒极了,我们的代码现在看起来简洁多了。
HTML 中的标题
到目前为止,蝙蝠侠对结果很高兴,他希望在情书上标题。他想写一个标题: “Bat Letter”。当然,你已经看到这个名字了,不是吗?:D
你可以使用 <h1>、<h2>、<h3>、<h4>、<h5> 和 <h6> 标签来添加标题,<h1> 是最大的标题和最主要的标题,<h6> 是最小的标题。

让我们在第二段之前使用 <h1> 做主标题和一个副标题:
<div style="width:550px;">
<h1>Bat Letter</h1>
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
保存,刷新。
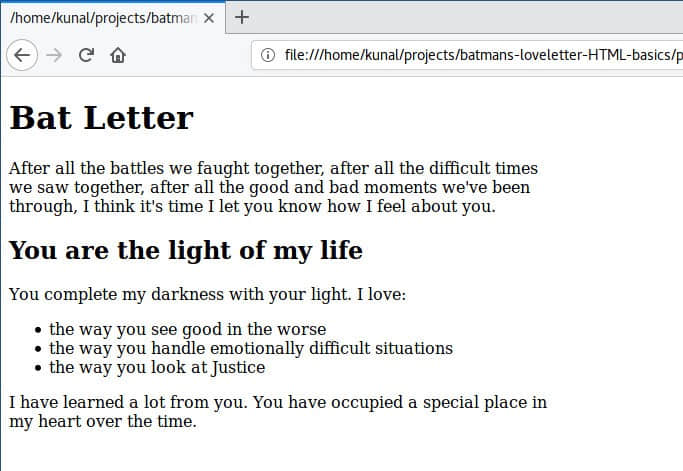
HTML 中的图像
我们的情书尚未完成,但在继续之前,缺少一件大事:蝙蝠侠标志。你见过是蝙蝠侠的东西但没有蝙蝠侠的标志吗?
并没有。
所以,让我们在情书中添加一个蝙蝠侠标志。
在 HTML 中包含图像就像在一个 Word 文件中包含图像一样。在 MS Word 中,你到 “菜单 -> 插入 -> 图像 -> 然后导航到图像位置为止 -> 选择图像 -> 单击插入”。
在 HTML 中,我们使用 <img> 标签让浏览器知道我们需要加载的图像,而不是单击菜单。我们在 src 属性中写入文件的位置和名称。如果图像在项目根目录中,我们可以简单地在 src 属性中写入图像文件的名称。
在我们深入编码之前,从这里下载蝙蝠侠标志。你可能希望裁剪图像中的额外空白区域。复制项目根目录中的图像并将其重命名为 “bat-logo.jpeg”。
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
我们在第 3 行包含了 <img> 标签。这个标签也是一个自闭合的标签,所以我们不需要写 </img>。在 src 属性中,我们给出了图像文件的名称。这个名称应与图像名称完全相同,包括扩展名(.jpeg)及其大小写。
保存并刷新,查看结果。
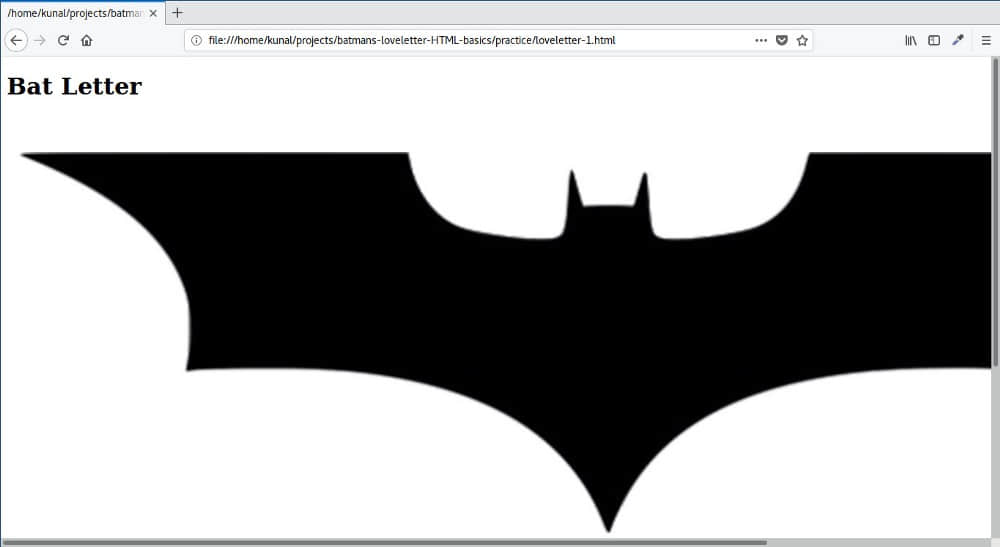
该死的!刚刚发生了什么?
当使用 <img> 标签包含图像时,默认情况下,图像将以其原始分辨率显示。在我们的例子中,图像比 550px 宽得多。让我们使用 style 属性定义它的宽度:
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
</div>
你会注意到,这次我们定义宽度使用了 “%” 而不是 “px”。当我们在 “%” 中定义宽度时,它将占据父元素宽度的百分比。因此,100% 的 550px 将为我们提供 550px。
保存并刷新,查看结果。
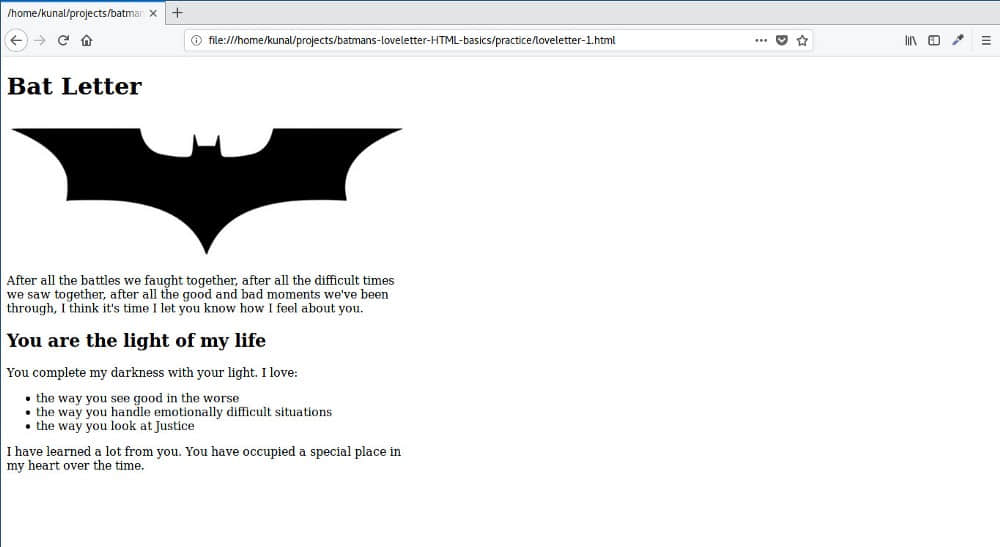
太棒了!这让蝙蝠侠的脸露出了羞涩的微笑 :)。
HTML 中的粗体和斜体
现在蝙蝠侠想在最后几段中承认他的爱。他有以下文本供你用 HTML 编写:
“I have a confession to make
It feels like my chest does have a heart. You make my heart beat. Your smile brings a smile to my face, your pain brings pain to my heart.
I don’t show my emotions, but I think this man behind the mask is falling for you.”
当阅读到这里时,你会问蝙蝠侠:“等等,这是给谁的?”蝙蝠侠说:
“这是给超人的。”

你说:哦!我还以为是给神奇女侠的呢。
蝙蝠侠说:不,这是给超人的,请在最后写上 “I love you Superman.”。
好的,我们来写:
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest does have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p>I love you Superman.</p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
这封信差不多完成了,蝙蝠侠另外想再做两次改变。蝙蝠侠希望在最后段落的第一句中的 “does” 一词是斜体,而 “I love you Superman” 这句话是粗体的。
我们使用 <em> 和 <strong> 以斜体和粗体显示文本。让我们来更新这些更改:
<div style="width:550px;">
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg" style="width:100%">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
HTML 中的样式
你可以通过三种方式设置样式或定义 HTML 元素的外观:
- 内联样式:我们使用元素的
style 属性来编写样式。这是我们迄今为止使用的,但这不是一个好的实践。 - 嵌入式样式:我们在由
<style> 和 </style> 包裹的 “style” 元素中编写所有样式。 - 链接样式表:我们在具有 .css 扩展名的单独文件中编写所有元素的样式。此文件称为样式表。
让我们来看看如何定义 <div> 的内联样式:
<div style="width:550px;">
我们可以在 <style> 和 </style> 里面写同样的样式:
div{
width:550px;
}
在嵌入式样式中,我们编写的样式是与元素分开的。所以我们需要一种方法来关联元素及其样式。第一个单词 “div” 就做了这样的活。它让浏览器知道花括号 {...} 里面的所有样式都属于 “div” 元素。由于这种语法确定要应用样式的元素,因此它称为一个选择器。
我们编写样式的方式保持不变:属性(width)和值(550px)用冒号(:)分隔,以分号(;)结束。
让我们从 <div> 和 <img> 元素中删除内联样式,将其写入 <style> 元素:
<style>
div{
width:550px;
}
img{
width:100%;
}
</style>
<div>
<h1>Bat Letter</h1>
<img src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
保存并刷新,结果应保持不变。
但是有一个大问题,如果我们的 HTML 文件中有多个 <div> 和 <img> 元素该怎么办?这样我们在 <style> 元素中为 div 和 img 定义的样式就会应用于页面上的每个 div 和 img。
如果你在以后的代码中添加另一个 div,那么该 div 也将变为 550px 宽。我们并不希望这样。
我们想要将我们的样式应用于现在正在使用的特定 div 和 img。为此,我们需要为 div 和 img 元素提供唯一的 id。以下是使用 id 属性为元素赋予 id 的方法:
<div id="letter-container">
以下是如何在嵌入式样式中将此 id 用作选择器:
#letter-container{
...
}
注意 # 符号。它表示它是一个 id,{...} 中的样式应该只应用于具有该特定 id 的元素。
让我们来应用它:
<style>
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
</style>
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
HTML 已经准备好了嵌入式样式。
但是,你可以看到,随着我们包含越来越多的样式,<style></style> 将变得很大。这可能很快会混乱我们的主 HTML 文件。
因此,让我们更进一步,通过将 <style> 标签内的内容复制到一个新文件来使用链接样式。
在项目根目录中创建一个新文件,将其另存为 “style.css”:
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
我们不需要在 CSS 文件中写 <style> 和 </style>。
我们需要使用 HTML 文件中的 <link> 标签来将新创建的 CSS 文件链接到 HTML 文件。以下是我们如何做到这一点:
<link rel="stylesheet" type="text/css" href="style.css">
我们使用 <link> 元素在 HTML 文档中包含外部资源,它主要用于链接样式表。我们使用的三个属性是:
rel:关系。链接文件与文档的关系。具有 .css 扩展名的文件称为样式表,因此我们保留 rel=“stylesheet”。type:链接文件的类型;对于一个 CSS 文件来说它是 “text/css”。href:超文本参考。链接文件的位置。
link 元素的结尾没有 </link>。因此,<link> 也是一个自闭合的标签。
<link rel="gf" type="cute" href="girl.next.door">
如果只是得到一个女朋友,那么很容易:D
可惜没有那么简单,让我们继续前进。
这是我们 “loveletter.html” 的内容:
<link rel="stylesheet" type="text/css" href="style.css">
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
“style.css” 内容:
#letter-container{
width:550px;
}
#header-bat-logo{
width:100%;
}
保存文件并刷新,浏览器中的输出应保持不变。
一些手续
我们的情书已经准备好给蝙蝠侠,但还有一些正式的片段。
与其他任何编程语言一样,HTML 自出生以来(1990 年)经历过许多版本,当前版本是 HTML5。
那么,浏览器如何知道你使用哪个版本的 HTML 来编写页面呢?要告诉浏览器你正在使用 HTML5,你需要在页面顶部包含 <!DOCTYPE html>。对于旧版本的 HTML,这行不同,但你不需要了解它们,因为我们不再使用它们了。
此外,在之前的 HTML 版本中,我们曾经将整个文档封装在 <html></html> 标签内。整个文件分为两个主要部分:头部在 <head></head> 里面,主体在 <body></body> 里面。这在 HTML5 中不是必须的,但由于兼容性原因,我们仍然这样做。让我们用 <Doctype>, <html>、 <head> 和 <body> 更新我们的代码:
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
</body>
</html>
主要内容在 <body> 里面,元信息在 <head> 里面。所以我们把 <div> 保存在 <body> 里面并加载 <head> 里面的样式表。
保存并刷新,你的 HTML 页面应显示与之前相同的内容。
HTML 的标题
我发誓,这是最后一次改变。
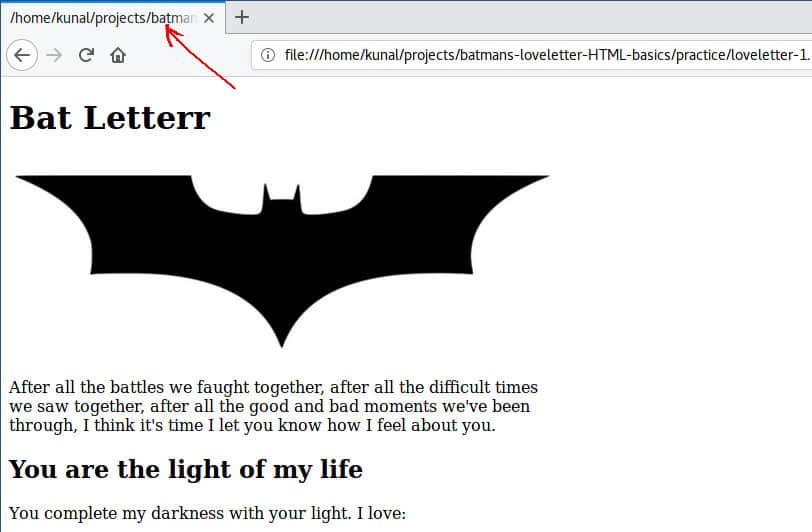
你可能已经注意到选项卡的标题正在显示 HTML 文件的路径:
我们可以使用 <title> 标签来定义 HTML 文件的标题。标题标签也像链接标签一样在 <head> 内部。让我们我们在标题中加上 “Bat Letter”:
<!DOCTYPE html>
<html>
<head>
<title>Bat Letter</title>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<div id="letter-container">
<h1>Bat Letter</h1>
<img id="header-bat-logo" src="bat-logo.jpeg">
<p>
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
</p>
<h2>You are the light of my life</h2>
<p>
You complete my darkness with your light. I love:
</p>
<ul>
<li>the way you see good in the worse</li>
<li>the way you handle emotionally difficult situations</li>
<li>the way you look at Justice</li>
</ul>
<p>
I have learned a lot from you. You have occupied a special place in my heart over the time.
</p>
<h2>I have a confession to make</h2>
<p>
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
</p>
<p>
I don't show my emotions, but I think this man behind the mask is falling for you.
</p>
<p><strong>I love you Superman.</strong></p>
<p>
Your not-so-secret-lover, <br>
Batman
</p>
</div>
</body>
</html>
保存并刷新,你将看到在选项卡上显示的是 “Bat Letter” 而不是文件路径。
蝙蝠侠的情书现在已经完成。
恭喜!你用 HTML 制作了蝙蝠侠的情书。

我们学到了什么
我们学习了以下新概念:
- 一个 HTML 文档的结构
- 在 HTML 中如何写元素(
<p></p>) - 如何使用 style 属性在元素内编写样式(这称为内联样式,尽可能避免这种情况)
- 如何在
<style>...</style> 中编写元素的样式(这称为嵌入式样式) - 在 HTML 中如何使用
<link> 在单独的文件中编写样式并链接它(这称为链接样式表) - 什么是标签名称,属性,开始标签和结束标签
- 如何使用 id 属性为一个元素赋予 id
- CSS 中的标签选择器和 id 选择器
我们学习了以下 HTML 标签:
<p>:用于段落<br>:用于换行<ul>、<li>:显示列表<div>:用于分组我们信件的元素<h1>、<h2>:用于标题和子标题<img>:用于插入图像<strong>、<em>:用于粗体和斜体文字样式<style>:用于嵌入式样式<link>:用于包含外部样式表<html>:用于包裹整个 HTML 文档<!DOCTYPE html>:让浏览器知道我们正在使用 HTML5<head>:包裹元信息,如 <link> 和 <title><body>:用于实际显示的 HTML 页面的主体<title>:用于 HTML 页面的标题
我们学习了以下 CSS 属性:
- width:用于定义元素的宽度
- CSS 单位:“px” 和 “%”
朋友们,这就是今天的全部了,下一个教程中见。
作者简介:开发者 + 作者 | supersarkar.com | twitter.com/supersarkar
via: https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b
作者:Kunal Sarkar 译者:MjSeven 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出











