Git 前时代:使用 CVS 进行版本控制
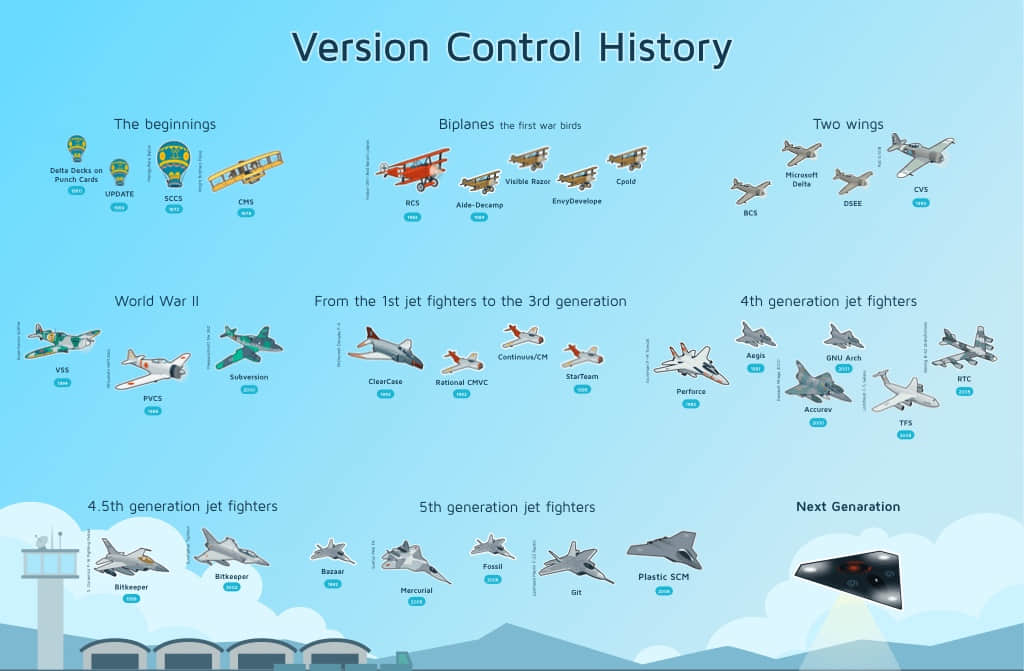
GitHub 网站发布于 2008 年。如果你的软件工程师职业生涯跟我一样,也是晚于此时间的话,Git 可能是你用过的唯一版本控制软件。虽然其陡峭的学习曲线和不直观地用户界面时常会遭人抱怨,但不可否认的是,Git 已经成为学习版本控制的每个人的选择。Stack Overflow 2015 年进行的开发者调查显示,69.3% 的被调查者在使用 Git,几乎是排名第二的 Subversion 版本控制系统使用者数量的两倍。 1 2015 年之后,也许是因为 Git 太受欢迎了,大家对此话题不再感兴趣,所以 Stack Overflow 停止了关于开发人员使用的版本控制系统的问卷调查。
GitHub 的发布时间距离 Git 自身发布时间很近。2005 年,Linus Torvalds 发布了 Git 的首个版本。现在的年经一代开发者可能很难想象“版本控制软件”一词所代表的世界并不仅仅只有 Git,虽然这样的世界诞生的时间并不长。除了 Git 外,还有很多可供选择。那时,开源开发者较喜欢 Subversion,企业和视频游戏公司使用 Perforce (到如今有些仍在用),而 Linux 内核项目依赖于名为 BitKeeper 的版本控制系统。
其中一些系统,特别是 BitKeeper,会让年经一代的 Git 用户感觉很熟悉,上手也很快,但大多数相差很大。除了 BitKeeper,Git 之前的版本控制系统都是以不同的架构模型为基础运行的。《Version Control By Example》一书的作者 Eric Sink 在他的书中对版本控制进行了分类,按其说法,Git 属于第三代版本控制系统,而大多数 Git 的前身,即流行于二十世纪九零年代和二十一世纪早期的系统,都属于第二代版本控制系统。 2 第三代版本控制系统是分布式的,第二代是集中式。你们以前大概都听过 Git 被描述为一款“分布式”版本控制系统。我一直都不明白分布式/集中式之间的区别,随后自己亲自安装了一款第二代的集中式版本控件系统,并做了相关实验,至少明白了一些。
我安装的版本系统是 CVS。CVS,即 “ 并发版本系统 ” 的缩写,是最初的第二代版本控制系统。大约十年间,它是最为流行的版本控制系统,直到 2000 年被 Subversion 所取代。即便如此,Subversion 被认为是 “更好的 CVS”,这更进一步突出了 CVS 在二十世纪九零年代的主导地位。
CVS 最早是由一位名叫 Dick Grune 的荷兰科学家在 1986 年开发的,当时有一个编译器项目,他正在寻找一种能与其学生合作的方法。 3 CVS 最初仅仅只是一个包装了 RCS( 修订控制系统 ) 的 Shell 脚本集合,Grune 想改进这个第一代的版本控制系统。 RCS 是按悲观锁模式工作的,这意味着两个程序员不可以同时处理同一个文件。需要编辑一个文件话,首先得向 RCS 系统请求一个排它锁,锁定此文件直到完成编辑,如果你想编辑的文件有人正在编辑,你就必须等待。CVS 在 RCS 基础上改进,并把悲观锁模型替换成乐观锁模型,迎来了第二代版本控制系统的时代。现在,程序员可以同时编辑同一个文件、合并编辑部分,随后解决合并冲突问题。(后来接管 CVS 项目的工程师 Brian Berliner 于 1990 年撰写了一篇非常易读的关于 CVS 创新的 论文。)
从这个意义上来讲,CVS 与 Git 并无差异,因为 Git 也是运行于乐观锁模式的,但也仅仅只有此点相似。实际上,Linus Torvalds 开发 Git 时,他的一个指导原则是 WWCVSND,即 “ CVS 不能做的 ”。每当他做决策时,他都会力争选择那些在 CVS 设计里没有使用的功能选项。 4 所以即使 CVS 要早于 Git 十多年,但它对 Git 的影响是反面的。
我非常喜欢折腾 CVS。我认为要弄明白为什么 Git 的分布式特性是对以前的版本控制系统的极大改善的话,除了折腾 CVS 外,没有更好的办法。因此,我邀请你跟我一起来一段激动人心的旅程,并在接下来的十分钟内了解下这个近十年来无人使用的软件。(可以看看文末“修正”部分)
CVS 入门
CVS 的安装教程可以在其 项目主页 上找到。MacOS 系统的话,可以使用 Homebrew 安装。
由于 CVS 是集中式的,所以它有客户端和服务端之区分,这种模式 Git 是没有的。两端分别有不同的可执行文件,其区别不太明显。但要开始使用 CVS 的话,即使只在你的本地机器上使用,也必须设置 CVS 的服务后端。
CVS 的后端,即所有代码的中央存储区,被叫做 存储库 。在 Git 中每一个项目都有一个存储库,而 CVS 中一个存储库就包含所有的项目。尽管有办法保证一次只能访问一个项目,但一个中央存储库包含所有东西是改变不了的。
要在本地创建存储库的话,请运行 init 命令。你可以像如下所示在家目录创建,也可以在你本地的任何地方创建。
$ cvs -d ~/sandbox initCVS 允许你将选项传递给 cvs 命令本身或 init 子命令。出现在 cvs 命令之后的选项默认是全局的,而出现在子命令之后的是子命令特有选项。上面所示例子中,-d 标志是全局选项。在这儿是告诉 CVS 我们想要创建存储库路径在哪里,但一般 -d 标志指的是我们想要使用的且已经存在的存储库位置。一直使用 -d 标志很单调乏味,所以可以设置 CVSROOT 环境变量来代替。
因为我们只是在本地操作,所以仅仅使用 -d 参考来传递路径就可以,但也可以包含个主机名。
此命令在你的家目录创建了一个名叫 sandbox 的目录。 如果你列出 sandbox 内容,会发现下面包含有名为 CVSROOT 的目录。请不要把此目录与我们的环境变量混淆,它保存存储库的管理文件。
恭喜! 你刚刚创建了第一个 CVS 存储库。
检入代码
假设你决定留存下自己喜欢的颜色清单。因为你是一个有艺术倾向但很健忘的人,所以你键入颜色列表清单,并保存到一个叫 favorites.txt 的文件中:
blue
orange
green
definitely not yellow我们也假设你把文件保存到一个叫 colors 的目录中。现在你想要把喜欢的颜色列表清单置于版本控制之下,因为从现在起的五十年间你会回顾下,随着时间的推移自己的品味怎么变化,这件事很有意思。
为此,你必须将你的目录导入为新的 CVS 项目。可以使用 import 命令:
$ cvs -d ~/sandbox import -m "" colors colors initial
N colors/favorites.txt
No conflicts created by this import这里我们再次使用 -d 标志来指定存储库的位置,其余的参数是传输给 import 子命令的。必须要提供一条消息,但这儿没必要,所以留空。下一个参数 colors,指定了存储库中新目录的名字,这儿给的名字跟检入的目录名称一致。最后的两个参数分别指定了 “vendor” 标签和 “release” 标签。我们稍后就会谈论标签。
我们刚将 colors 项目拉入 CVS 存储库。将代码引入 CVS 有很多种不同的方法,但这是 《Pragmatic Version Control Using CVS》 一书所推荐方法,这是一本关于 CVS 的程序员实用指导书籍。使用这种方法有点尴尬的就是你得重新 检出 工作项目,即使已经存在有 colors 此项目了。不要使用该目录,首先删除它,然后从 CVS 中检出刚才的版本,如下示:
$ cvs -d ~/sandbox co colors
cvs checkout: Updating colors
U colors/favorites.txt这个过程会创建一个新的目录,也叫做 colors。此目录里会发现你的源文件 favorites.txt,还有一个叫 CVS 的目录。这个 CVS 目录基本上与每个 Git 存储库的 .git 目录等价。
做出改动
准备旅行。
和 Git 一样,CVS 也有 status 命令:
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: fD7GYxt035GNg8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)到这儿事情开始陌生起来了。CVS 没有提交对象这一概念。如上示,有一个叫 “ 提交标识符 ” 的东西,但这可能是一个较新版本的标识,在 2003 年出版的《Pragmatic Version Control Using CVS》一书中并没有提到 “提交标识符” 这个概念。 (CVS 的最新版本于 2008 年发布的。 5 )
在 Git 中,我们所谈论某文件版本其实是在谈论如 commit 45de392 相关的东西,而 CVS 中文件是独立版本化的。文件的第一个版本为 1.1 版本,下一个是 1.2 版本,依此类推。涉及分支时,会在后面添加扩展数字。因此你会看到如上所示的 1.1.1.1 的内容,这就是示例的版本号,即使我们没有创建分支,似乎默认的会给加上。
一个项目中会有很多的文件和很多次的提交,如果你运行 cvs log 命令(等同于 git log),会看到每个文件提交历史信息。同一个项目中,有可能一个文件处于 1.2 版本,一个文件处于 1.14 版本。
继续,我们对 1.1 版本的 favorites.txt 文件做些修改(LCTT 译注:原文此处示例有误):
blue
orange
green
cyan
definitely not yellow修改完成,就可以运行 cvs diff 来看看 CVS 发生了什么:
$ cvs diff
cvs diff: Diffing .
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.1.1.1
diff -r1.1.1.1 favorites.txt
3a4
> cyanCVS 识别出我们我在文件中添加了一个包含颜色 “cyan” 的新行。(实际上,它说我们已经对 “RCS” 文件进行了更改;你可以看到,CVS 底层使用的还是 RCS。) 此差异指的是当前工作目录中的 favorites.txt 副本与存储库中 1.1.1.1 版本的文件之间的差异。
为了更新存储库中的版本,我们必须提交更改。Git 中,这个操作要好几个步骤。首先,暂存此修改,使其在索引中出现,然后提交此修改,最后,为了使此修改让其他人可见,我们必须把此提交推送到源存储库中。
而 CVS 中,只需要运行 cvs commit 命令就搞定一切。CVS 会汇集它所找到的变化,然后把它们放到存储库中:
$ cvs commit -m "Add cyan to favorites."
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.2; previous revision: 1.1我已经习惯了 Git,所以这种操作会让我感到十分恐惧。因为没有变更暂存区的机制,工作目录下任何你动过的东西都会一股脑给提交到公共存储库中。你有过因为不爽,私下里重写了某个同事不佳的函数实现,但仅仅只是自我宣泄一下并不想让他知道的时候吗?如果不小心提交上去了,就太糟糕了,他会认为你是个混蛋。在推送它们之前,你也不能对提交进行编辑,因为提交就是推送。还是你愿意花费 40 分钟的时间来反复运行 git rebase -i 命令,以使得本地提交历史记录跟数学证明一样清晰严谨?很遗憾,CVS 里不支持,结果就是,大家都会看到你没有先写测试用例。
不过,到现在我终于理解了为什么那么多人都觉得 Git 没必要搞那么复杂。对那些早已经习惯直接 cvs commit 的人来说,进行暂存变更和推送变更操作确实是毫无意义的差事。
人们常谈论 Git 是一个 “分布式” 系统,其中分布式与非分布式的主要区别为:在 CVS 中,无法进行本地提交。提交操作就是向中央存储库提交代码,所以没有网络连接,就无法执行操作,你本地的那些只是你的工作目录而已;在 Git 中,会有一个完完全全的本地存储库,所以即使断网了也可以无间断执行提交操作。你还可以编辑那些提交、回退、分支,并选择你所要的东西,没有任何人会知道他们必须知道的之外的东西。
因为提交是个大事,所以 CVS 用户很少做提交。提交会包含很多的内容修改,就像如今我们能在一个含有十次提交的拉取请求中看到的一样多。特别是在提交触发了 CI 构建和自动测试程序时如此。
现在我们运行 cvs status,会看到产生了文件的新版本:
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Up-to-date
Working revision: 1.2 2018-07-06 21:18:59 -0400
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: pQx5ooyNk90wW8JA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)合并
如上所述,在 CVS 中,你可以同时编辑其他人正在编辑的文件。这是 CVS 对 RCS 的重大改进。当需要将更改的部分重新组合在一起时会发生什么?
假设你邀请了一些朋友来将他们喜欢的颜色添加到你的列表中。在他们添加的时候,你确定了不再喜欢绿色,然后把它从列表中删除。
当你提交更新的时候,会发现 CVS 报出了个问题:
$ cvs commit -m "Remove green"
cvs commit: Examining .
cvs commit: Up-to-date check failed for `favorites.txt'
cvs [commit aborted]: correct above errors first!这看起来像是朋友们首先提交了他们的变化。所以你的 favorites.txt 文件版本没有更新到存储库中的最新版本。此时运行 cvs status 就可以看到,本地的 favorites.txt 文件副本有一些本地变更且是 1.2 版本的,而存储库上的版本号是 1.3,如下示:
$ cvs status
cvs status: Examining .
===================================================================
File: favorites.txt Status: Needs Merge
Working revision: 1.2 2018-07-07 10:42:43 -0400
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
Commit Identifier: 2oZ6n0G13bDaldJA
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)你可以运行 cvs diff 来了解 1.2 版本与 1.3 版本的确切差异:
$ cvs diff -r HEAD favorites.txt
Index: favorites.txt
===================================================================
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.3
diff -r1.3 favorites.txt
3d2
< green
7,10d5
<
< pink
< hot pink
< bubblegum pink看来我们的朋友是真的喜欢粉红色,但好在他们编辑的是此文件的不同部分,所以很容易地合并此修改。跟 git pull 类似,只要运行 cvs update 命令,CVS 就可以为我们做合并操作,如下示:
$ cvs update
cvs update: Updating .
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
retrieving revision 1.2
retrieving revision 1.3
Merging differences between 1.2 and 1.3 into favorites.txt
M favorites.txt此时查看 favorites.txt 文件内容的话,你会发现你的朋友对文件所做的更改已经包含进去了,你的修改也在里面。现在你可以自由的提交文件了,如下示:
$ cvs commit
cvs commit: Examining .
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
new revision: 1.4; previous revision: 1.3最终的结果就跟在 Git 中运行 git pull --rebase 一样。你的修改是添加在你朋友的修改之后的,所以没有 “合并提交” 这操作。
某些时候,对同一文件的修改可能导致冲突。例如,如果你的朋友把 “green” 修改成 “olive”,同时你完全删除 “green”,就会出现冲突。CVS 早期的时候,正是这种情况导致人们担心 CVS 不安全,而 RCS 的悲观锁机制可以确保此情况永不会发生。但 CVS 提供了一个安全保障机制,可以确保不会自动的覆盖任何人的修改。因此,当运行 cvs update 的时候,你必须告诉 CVS 想要保留哪些修改才能继续下一步操作。CVS 会标记文件的所有变更,这跟 Git 检测到合并冲突时所做的方式一样,然后,你必须手工编辑文件,选择需要保留的变更进行合并。
这儿需要注意的有趣事情就是在进行提交之前必须修复并合并冲突。这是 CVS 集中式特性的另一个结果。而在 Git 里,在推送本地的提交内容之前,你都不用担心合并冲突问题。
标记与分支
由于 CVS 没有易于寻址的提交对象,因此对变更集合进行分组的唯一方法就是对于特定的工作目录状态打个标记。
创建一个标记是很容易的:
$ cvs tag VERSION_1_0
cvs tag: Tagging .
T favorites.txt稍后,运行 cvs update 命令并把标签传输给 -r 标志就可以把文件恢复到此状态,如下示:
$ cvs update -r VERSION_1_0
cvs update: Updating .
U favorites.txt因为你需要一个标记来回退到早期的工作目录状态,所以 CVS 鼓励创建大量的抢先标记。例如,在重大的重构之前,你可以创建一个 BEFORE_REFACTOR_01 标记,如果重构出错,就可以使用此标记回退。你如果想生成整个项目的差异文件的话,也可以使用标记。基本上,如今我们惯常使用提交的哈希值完成的事情都必须在 CVS 中提前计划,因为你必须首先有个标签才行。
可以在 CVS 中创建分支。分支只是一种特殊的标记,如下示:
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
cvs rtag: Tagging colors这命令仅仅只是创建了分支(每个人都这样觉得吧),所以还需要使用 cvs update 命令来切换分支,如下示:
$ cvs update -r TRY_EXPERIMENTAL_THING上面的命令就会把你的当前工作目录切换到新的分支,但《Pragmatic Version Control Using CVS》一书实际上是建议创建一个新的目录来房子你的新分支。估计,其作者发现在 CVS 里切换目录要比切换分支来得更简单吧。
此书也建议不要从现有分支创建分支,而只在主线分支(Git 中被叫做 master)上创建分支。一般来说,分支在 CVS 中主认为是 “高级” 技能。而在 Git 中,你几乎可以任性创建新分支,但 CVS 中要在真正需要的时候才能创建,比如发布项目。
稍后可以使用 cvs update 和 -j 标志将分支合并回主线:
$ cvs update -j TRY_EXPERIMENTAL_THING感谢历史上的贡献者
2007 年,Linus Torvalds 在 Google 进行了一场关于 Git 的 演讲。当时 Git 是很新的东西,整场演讲基本上都是在说服满屋子都持有怀疑态度的程序员们:尽管 Git 是如此的与众不同,也应该使用 Git。如果没有看过这个视频的话,我强烈建议你去看看。Linus 是个有趣的演讲者,即使他有些傲慢。他非常出色地解释了为什么分布式的版本控制系统要比集中式的优秀。他的很多评论是直接针对 CVS 的。
Git 是一个 相当复杂的工具。学习起来是一个令人沮丧的经历,但也不断的给我惊喜:Git 还能做这样的事情。相比之下,CVS 简单明了,但是,许多我们认为理所当然的操作都做不了。想要对 Git 的强大功能和灵活性有全新的认识的话,就回过头来用用 CVS 吧,这是种很好的学习方式。这很好的诠释了为什么理解软件的开发历史可以让人受益匪浅。重拾过期淘汰的工具可以让我们理解今天所使用的工具后面所隐藏的哲理。
如果你喜欢此博文的话,每两周会有一次更新!请在 Twitter 上关注 @TwoBitHistory 或都通过 RSS feed 订阅,新博文出来会有通知。
修正
有人告诉我,有很多组织企业,特别是像做医疗设备软件等这种规避风险类的企业,仍在使用 CVS。这些企业中的程序员通过使用一些小技巧来解决 CVS 的限制,例如为几乎每个更改创建一个新分支以避免直接提交给 HEAD。 (感谢 Michael Kohne 指出这一点。)
(题图:plasticscm)
via: https://twobithistory.org/2018/07/07/cvs.html
作者:Two-Bit History 选题:lujun9972 译者:runningwater 校对:wxy
- “2015 Developer Survey,” Stack Overflow, accessed July 7, 2018, https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol. ↩
- Eric Sink, “A History of Version Control,” Version Control By Example, 2011, accessed July 7, 2018, https://ericsink.com/vcbe/html/history_of_version_control.html. ↩
- Dick Grune, “Concurrent Versions System CVS,” dickgrune.com, accessed July 7, 2018, https://dickgrune.com/Programs/CVS.orig/#History. ↩
- “Tech Talk: Linus Torvalds on Git,” YouTube, May 14, 2007, accessed July 7, 2018, https://www.youtube.com/watch?v=4XpnKHJAok8. ↩
- “Concurrent Versions System - News,” Savannah, accessed July 7, 2018, http://savannah.nongnu.org/news/?group=cvs. ↩

































{kind=link}