30 个 Openstack 经典面试问题和解答
现在,大多数公司都试图将它们的 IT 基础设施和电信设施迁移到私有云, 如 OpenStack。如果你打算面试 OpenStack 管理员这个岗位,那么下面列出的这些面试问题可能会帮助你通过面试。

Q:1 说一下 OpenStack 及其主要组件?
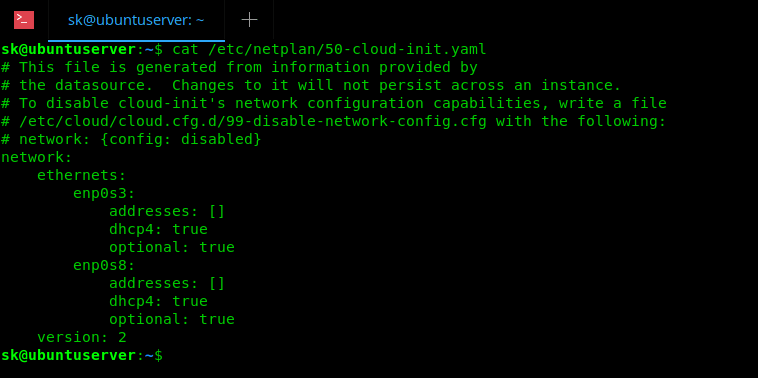
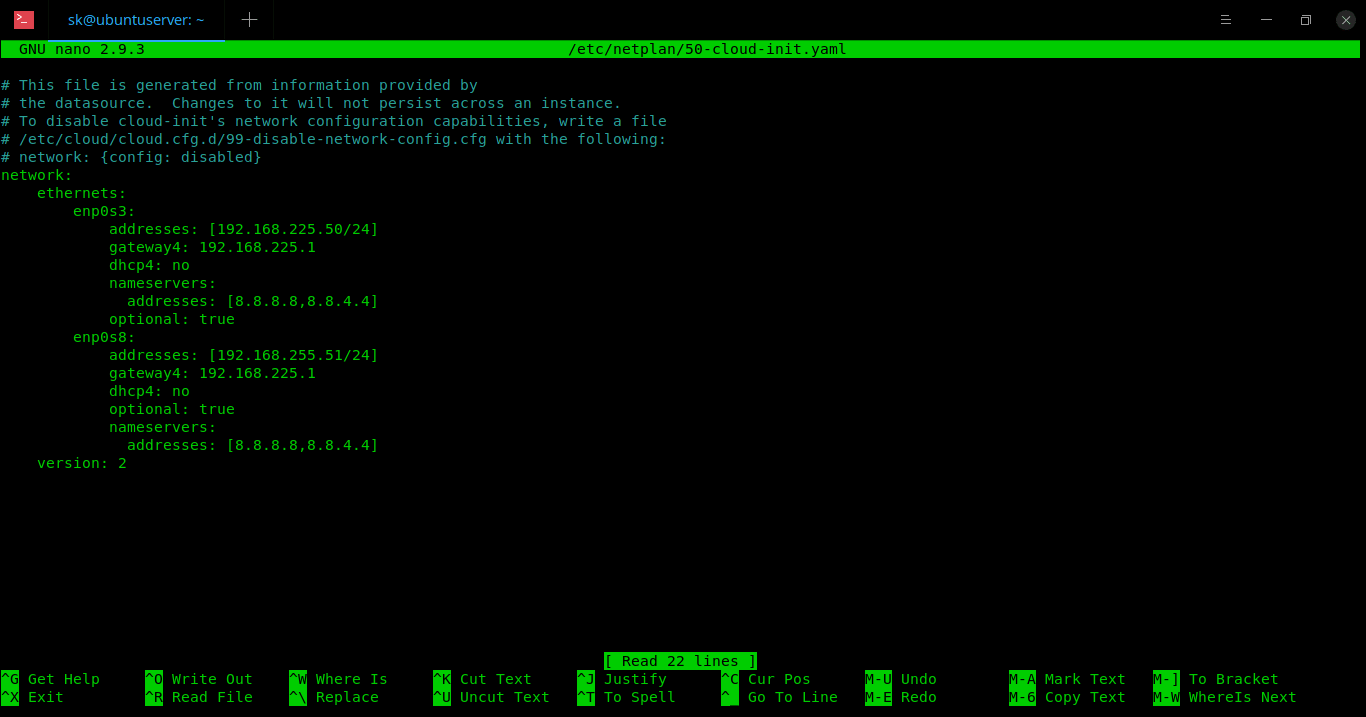
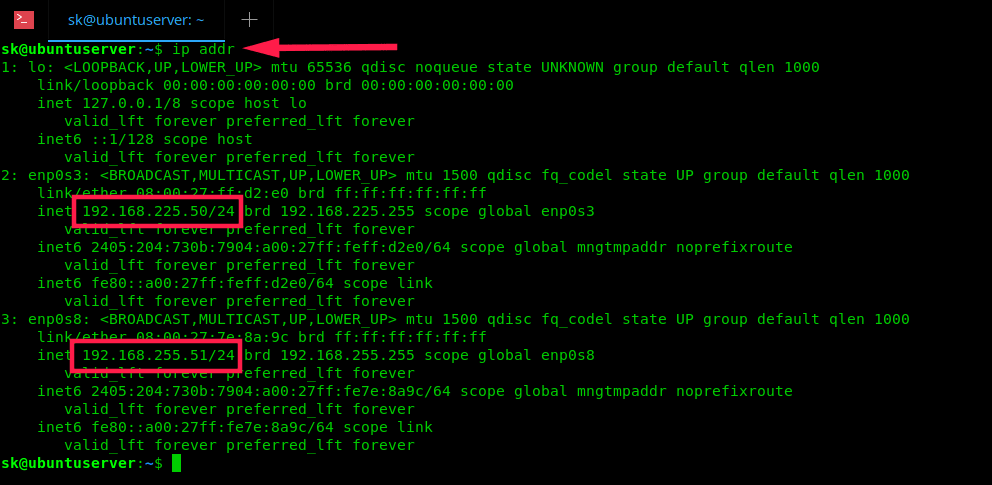
答: OpenStack 是一系列开源软件,这些软件组成了一个云供给软件,也就是 OpenStack,意即开源软件或项目栈。
下面是 OpenStack 的主要关键组件:
- Nova – 用于在计算级别管理虚拟机,并在计算或管理程序级别执行其他计算任务。
- Neutron – 为虚拟机、计算和控制节点提供网络功能。
- Keystone – 为所有云用户和 OpenStack 云服务提供身份认证服务。换句话说,我们可以说 Keystone 是一个提供给云用户和云服务访问权限的方法。
- Horizon – 用于提供图形用户界面。使用图形化管理界面可以很轻松地完成各种日常操作任务。
- Cinder – 用于提供块存储功能。通常来说 OpenStack 的 Cinder 中集成了 Chef 和 ScaleIO 来共同为计算和控制节点提供块存储服务。
- Swift – 用于提供对象存储功能。通常来说,Glance 管理的镜像是存储在对象存储空间的。像 ScaleIO 这样的外部存储也可以提供对象存储,可以很容易的集成 Glance 服务。
- Glance – 用于提供镜像服务。使用 Glance 的管理平台来上传和下载云镜像。
- Heat – 用于提供编排服务或功能。使用 Heat 管理平台可以轻松地将虚拟机作为堆栈,并且根据需要可以将虚拟机扩展或收缩。
- Ceilometer – 用于提供计量与监控功能。
Q:2 什么服务通常在控制节点上运行?
答: 以下服务通常在控制节点上运行:
- 认证服务(KeyStone)
- 镜像服务(Glance)
- Nova 服务比如 Nova API、Nova Scheduler 和 Nova DB
- 块存储和对象存储服务
- Ceilometer 服务
- MariaDB / MySQL 和 RabbitMQ 服务
- 网络(Neutron)和网络代理的管理服务
- 编排服务(Heat)
Q:3 什么服务通常在计算节点上运行?
答: 以下服务通常在计算节点运行:
- Nova 计算
- 网络服务,比如 OVS
Q:4 计算节点上虚拟机的默认地址是什么?
答: 虚拟机存储在计算节点的 /var/lib/nova/instances。
Q:5 Glance 镜像的默认地址是什么?
答: 因为 Glance 服务运行在控制节点上,所以 Glance 镜像都被存储在控制节点的 /var/lib/glance/images 文件夹下。
想了解更多请访问:在 OpenStack 中如何使用命令行创建和删除虚拟机
Q:6 说一下如何使用命令行启动一个虚拟机?
答: 我们可以使用如下 OpenStack 命令来启动一个新的虚拟机:
# openstack server create --flavor {flavor-name} --image {Image-Name-Or-Image-ID} --nic net-id={Network-ID} --security-group {Security_Group_ID} –key-name {Keypair-Name} <VM_Name>Q:7 如何在 OpenStack 中显示用户的网络命名空间列表?
答: 可以使用 ip net ns 命令来列出用户的网络命名空间。
~# ip netns list
qdhcp-a51635b1-d023-419a-93b5-39de47755d2d
haproxy
vrouterQ:8 如何在 OpenStack 中执行网络命名空间内的命令?
答: 假设我们想在 qdhcp-a51635b1-d023-419a-93b5-39de47755d2d 网络命名空间中执行 ifconfig 命令,我们可以执行如下命令。
命令格式 : ip netns exec {network-space} <command>:
~# ip netns exec qdhcp-a51635b1-d023-419a-93b5-39de47755d2d "ifconfig"Q:9 在 Glance 服务中如何使用命令行上传和下载镜像?
答: Glance 服务中云镜像上传可以使用如下 OpenStack 命令:
~# openstack image create --disk-format qcow2 --container-format bare --public --file {Name-Cloud-Image}.qcow2 <Cloud-Image-Name>下载云镜像则使用如下命令:
~# glance image-download --file <Cloud-Image-Name> --progress <Image-ID>Q:10 OpenStack 如何将虚拟机从错误状态转换为活动状态?
答: 在某些情况下虚拟机可能会进入错误状态,可以使用如下命令将错误状态转换为活动状态:
~# nova reset-state --active {Instance_id}Q:11 如何使用命令行来获取可使用的浮动 IP 列表?
答: 可使用如下命令来显示可用浮动 IP 列表:
~]# openstack ip floating list | grep None | head -10Q:12 如何在特定可用区域中或在计算主机上配置虚拟机?
答: 假设我们想在 compute-02 中的可用区 NonProduction 上配置虚拟机,可以使用如下命令:
~]# openstack server create --flavor m1.tiny --image cirros --nic net-id=e0be93b8-728b-4d4d-a272-7d672b2560a6 --security-group NonProd_SG --key-name linuxtec --availability-zone NonProduction:compute-02 nonprod_testvmQ:13 如何在特定计算节点上获取配置的虚拟机列表?
答: 假设我们想要获取在 compute-0-19 中配置的虚拟机列表,可以使用如下命令:
命令格式: openstack server list –all-projects –long -c Name -c Host | grep -i {Compute-Node-Name}:
~# openstack server list --all-projects --long -c Name -c Host | grep -i compute-0-19Q:14 如何使用命令行查看 OpenStack 实例的控制台日志?
答: 使用如下命令可查看实例的控制台日志。
首先获取实例的 ID,然后使用如下命令:
~# openstack console log show {Instance-id}Q:15 如何获取 OpenStack 实例的控制台的 URL 地址?
答: 可以使用以下 OpenStack 命令从命令行检索实例的控制台 URL 地址:
~# openstack console url show {Instance-id}Q:16 如何使用命令行创建可启动的 cinder / block 存储卷?
答: 假设创建一个 8GB 可启动存储卷,可参考如下步骤:
- 使用如下命令获取镜像列表
~# openstack image list | grep -i cirros
| 89254d46-a54b-4bc8-8e4d-658287c7ee92 | cirros | active |- 使用 cirros 镜像创建 8GB 的可启动存储卷
~# cinder create --image-id 89254d46-a54b-4bc8-8e4d-658287c7ee92 --display-name cirros-bootable-vol 8Q:17 如何列出所有在你的 OpenStack 中创建的项目或用户?
答: 可以使用如下命令来检索所有项目和用户:
~# openstack project list --longQ:18 如何显示 OpenStack 服务端点列表?
答: OpenStack 服务端点被分为 3 类:
- 公共端点
- 内部端点
- 管理端点
使用如下 OpenStack 命令来查看各种 OpenStack 服务端点:
~# openstack catalog list可通过以下命令来显示特定服务端点(比如说 keystone)列表:
~# openstack catalog show keystone想了解更多请访问:OpenStack 中的实例创建流程。
Q:19 在控制节点上你应该按照什么步骤来重启 nova 服务?
答: 应该按照如下步骤来重启 OpenStack 控制节点的 nova 服务:
service nova-api restartservice nova-cert restartservice nova-conductor restartservice nova-consoleauth restartservice nova-scheduler restart
Q:20 假如计算节点上为数据流量配置了一些 DPDK 端口,你如何检查 DPDK 端口的状态呢?
答: 因为我们使用 openvSwitch (OVS) 来配置 DPDK 端口,因此可以使用如下命令来检查端口的状态:
root@compute-0-15:~# ovs-appctl bond/show | grep dpdk
active slave mac: 90:38:09:ac:7a:99(dpdk0)
slave dpdk0: enabled
slave dpdk1: enabled
root@compute-0-15:~#
root@compute-0-15:~# dpdk-devbind.py --statusQ:21 如何使用命令行在 OpenStack 中向存在的安全组 SG(安全组)中添加新规则?
答: 可以使用 neutron 命令向 OpenStack 已存在的安全组中添加新规则:
~# neutron security-group-rule-create --protocol <tcp or udp> --port-range-min <port-number> --port-range-max <port-number> --direction <ingress or egress> --remote-ip-prefix <IP-address-or-range> Security-Group-NameQ:22 如何查看控制节点和计算节点的 OVS 桥配置?
答: 控制节点和计算节点的 OVS 桥配置可使用以下命令来查看:
~]# ovs-vsctl showQ:23 计算节点上的集成桥(br-int)的作用是什么?
答: 集成桥(br-int)对来自和运行在计算节点上的实例的流量执行 VLAN 标记和取消标记。
数据包从实例的 n/w 接口发出使用虚拟接口 qvo 通过 Linux 桥(qbr)。qvb 接口是用来连接 Linux 桥的,qvo 接口是用来连接集成桥的。集成桥上的 qvo 端口有一个内部 VLAN 标签,这个标签是用于当数据包到达集成桥的时候贴到数据包头部的。
Q:24 隧道桥(br-tun)在计算节点上的作用是什么?
答: 隧道桥(br-tun)根据 OpenFlow 规则将 VLAN 标记的流量从集成网桥转换为隧道 ID。
隧道桥允许不同网络的实例彼此进行通信。隧道有利于封装在非安全网络上传输的流量,它支持两层网络,即 GRE 和 VXLAN。
Q:25 外部 OVS 桥(br-ex)的作用是什么?
答: 顾名思义,此网桥转发来往网络的流量,以允许外部访问实例。br-ex 连接物理接口比如 eth2,这样用户网络的浮动 IP 数据从物理网络接收并路由到用户网络端口。
Q:26 OpenStack 网络中 OpenFlow 规则的作用是什么?
答: OpenFlow 规则是一种机制,这种机制定义了一个数据包如何从源到达目的地。OpenFlow 规则存储在 flow 表中。flow 表是 OpenFlow 交换机的一部分。
当一个数据包到达交换机就会被第一个 flow 表检查,如果不匹配 flow 表中的任何入口,那这个数据包就会被丢弃或者转发到其他 flow 表中。
Q:27 怎样查看 OpenFlow 交换机的信息(比如端口、表编号、缓存编号等)?
答: 假如我们要显示 OpenFlow 交换机的信息(br-int),需要执行如下命令:
root@compute-0-15# ovs-ofctl show br-int
OFPT_FEATURES_REPLY (xid=0x2): dpid:0000fe981785c443
n_tables:254, n_buffers:256
capabilities: FLOW_STATS TABLE_STATS PORT_STATS QUEUE_STATS ARP_MATCH_IP
actions: output enqueue set_vlan_vid set_vlan_pcp strip_vlan mod_dl_src mod_dl_dst mod_nw_src mod_nw_dst mod_nw_tos mod_tp_src mod_tp_dst
1(patch-tun): addr:3a:c6:4f:bd:3e:3b
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(qvob35d2d65-f3): addr:b2:83:c4:0b:42:3a
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
………………………………………Q:28 如何显示交换机中的所有 flow 的入口?
答: 可以使用命令 ovs-ofctl dump-flows 来查看交换机的 flow 入口。
假设我们想显示 OVS 集成桥(br-int)的所有 flow 入口,可以使用如下命令:
[root@compute01 ~]# ovs-ofctl dump-flows br-intQ:29 什么是 Neutron 代理?如何显示所有 Neutron 代理?
答: OpenStack Neutron 服务器充当中心控制器,实际网络配置是在计算节点或者网络节点上执行的。Neutron 代理是计算节点或者网络节点上进行配置更新的软件实体。Neutron 代理通过 Neuron 服务和消息队列来和中心 Neutron 服务通信。
可通过如下命令查看 Neutron 代理列表:
~# openstack network agent list -c ‘Agent type’ -c Host -c Alive -c StateQ:30 CPU Pinning 是什么?
答: CPU Pinning 是指为某个虚拟机保留物理核心。它也称为 CPU 隔离或处理器关联。有两个目的:
- 它确保虚拟机只能在专用核心上运行
- 它还确保公共主机进程不在这些核心上运行
我们也可以认为 Pinning 是物理核心到一个用户虚拟 CPU(vCPU)的一对一映射。
via: https://www.linuxtechi.com/openstack-interview-questions-answers/
作者:Pradeep Kumar 选题:lujun9972 译者:ScarboroughCoral 校对:wxy