用这些技巧释放 sudo 的力量 ?
你应该熟悉 sudo 吧?肯定有过使用的经验。
对多数 Linux 用户来说,sudo 就像一个神器,赋予了他们作为 root 用户执行任意命令或切换到 root 用户身份的能力。
其实这只掌握了一半的真相。sudo 绝非仅仅只是一条命令,sudo 是一款你可以根据需求和偏好去定制的工具。
Ubuntu、Debian 以及其他的发行版在默认的配置下,赋予了 sudo 以 root 用户的身份执行任意命令的权限。这让很多用户误以为 sudo 就像一个魔法开关,瞬间可以获取到 root 权限。
比如说,系统管理员可以设置成只有属于特定的 dev 组的部分用户才能用 sudo 来执行 nginx 命令。这些用户将无法用 sudo 执行任何其他命令或切换到 root 用户。
如果你对此感到惊讶,那很可能是你一直在使用 sudo,但对其底层的工作原理并没有太多了解。
在这个教程中,我并不会解释 sudo 是如何运作的,这个主题我会在另一天讲解。
在这篇文章中,你将看到 sudo 的不同特性可以如何被调试和改进。有些可能真的很有用,有些可能完全没什么帮助,但是挺有趣。
? 请不要随意去尝试所有提到的改进。如果处理不慎,你可能会遭遇无法运行 sudo 的混乱状态。在大多数情况下,平静阅读并知道这些就好。如果你决定尝试一些改进步骤,请先备份你的系统设置,这样在需要的时候能把事情恢复到正常。
1、编辑 sudo 配置时,请始终使用 visudo
sudo 命令是通过 /etc/sudoers 文件进行配置的。
虽然你可以用你最喜欢的 终端文本编辑器 编辑这个文件,比如 Micro、NeoVim 等,但你千万不要这么做。
为什么这么说呢?因为该文件中的任何语法错误都会让你的系统出问题,导致 sudo 无法工作。这可能会使得你的 Linux 系统无法正常使用。
你只需要这样使用即可:
sudo visudo
传统上,visudo 命令会在 Vi 编辑器中打开 /etc/sudoers 文件。如果你用的是 Ubuntu,那么会在 Nano 中打开。
这么做的好处在于,visudo 会在你试图保存更改时执行语法检查。这能确保你不会因为语法错误而误改 sudo 配置。

好了!现在你可以看看 sudo 配置的一些改变。
? 我建议你备份 /etc/sudoers 文件(sudo cp /etc/sudoers /etc/sudoers.bak)。这样,如果你不确定你做了哪些更改,或者你想恢复到默认的 sudo 配置,那你可以从备份文件中复制。
2、输入 sudo 密码时显示星号
我们的这种输入行为是从 UNIX 系统中继承下来的。当你在终端输入 sudo 密码时,屏幕上不会有任何显示。这种缺乏反馈的现象,往往让新的 Linux 用户怀疑自己的系统已经卡住了。
人们常说,这是一项安全功能。或许在上个世纪是这样,但我个人觉得我们没有必要继续这样下去。
不过,一些发行版,如 Linux Mint,已经对 sudo 进行了优化,当你输入密码时会显示星号。
这样的方式更符合我们的日常经验。
如果想让 sudo 输入密码时显示星号,运行 sudo visudo 并找到以下行:
Defaults env_reset
然后将其更改为:
Defaults env_reset,pwfeedback
? 在某些发行版中,比如 Arch,你可能找不到 Defaults env_reset 这一行。如果这样的话,只需新增一行 Defaults env_reset, pwfeedback 就可以了。
现在,当 sudo 需要你输入密码时,你会看到输入的密码变成了星号。
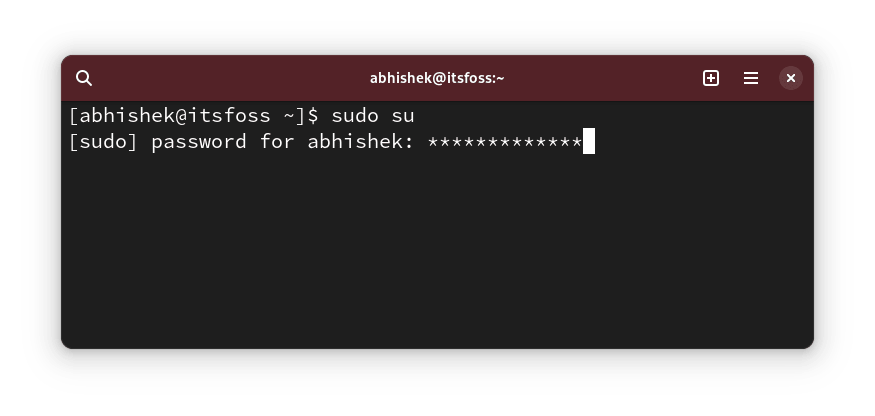
✋ 如果你注意到即使密码正确也无法通过一些图形化应用,如软件中心,那就该撤销这项更改。一些较旧的论坛帖子曾提到过此类问题,虽然我自己还未遇到过。
3、增加 sudo 密码超时时限
当你首次使用 sudo 时,它会要求输入密码。但在随后相当一段时间里,你使用 sudo 执行命令就无需再次输入密码。
我们将这个时间间隔称为 sudo 密码超时 (暂且称为 SPT,这是我刚刚编的说法,请不要真的这样称呼 ?)。
不同的发行版有不同的超时时间。可能是 5 分钟,也可能是 15 分钟。
你可以根据自己的喜好来改变这个设置,设定一个新的 sudo 密码超时时限。
像你之前看到的,编辑 sudoers 文件,找到含有 Defaults env_reset 的行,并在此行添加 timestamp_timeout=XX,使其变成如下形式:
Defaults env_reset, timestamp_timeout=XX
其中 XX 是以分钟为单位的超时时长。
如果你还有其他参数,例如你在上一节中看到的星号反馈,它们都可以在一行中组合起来:
Defaults env_reset, timestamp_timeout=XX, pwfeedback
? 同样地,你还可以控制密码重试的次数上限。使用 passwd_tries=N 来修改用户可以输入错误密码的次数。
4、在不输入密码的情况下使用 sudo
行!你已经增加了 sudo 密码超时时限(或者称之为 SPT。哇塞!你还在坚持这个叫法 ?)。
这样很好。我的意思是,毕竟没人愿意每几分钟就输入一次密码。
扩大超时时限是一方面,另一方面则是尽可能不去使用它。
是的,你没听错。你就是可以在无需输入密码的情况下使用 sudo。
从安全角度来看,这听起来似乎很冒险,对吧?的确如此,但在某些实际情况下,你确实会更青睐无密码的 sudo。
例如,如果你需要远程管理多台 Linux 服务器,并为了避免总是使用 root,你在这些服务器上创建了一些 sudo 用户。辛酸的是,你会有太多的密码。而你又不想对所有的服务器使用同一的 sudo 密码。
在这种情况下,你可以仅设置基于密钥的 SSH 访问方式,并允许使用无需密码的 sudo。这样,只有获得授权的用户才能访问远程服务器,也不用再记住 sudo 密码。
我在 DigitalOcean 上部署的测试服务器上就采用了这种方法,用来测试开源工具和服务。
好处是这可以按用户进行设置。使用以下命令打开 /etc/sudoers 文件进行编辑:
sudo visudo
然后添加如下行:
user_name ALL=(ALL) NOPASSWD:ALL
当然,你需要将上面行中的 user_name 替换为实际的用户名。
保存文件后,你就可以享受无密码的 sudo 生活了。
5、配置独立的 sudo 日志文件
查阅 syslog 或 journal 日志,我们可以找到关于 sudo 的所有条目,但若需要单独针对 sudo 的记录,可以专门创建一个自定义的日志文件。例如,选择 /var/sudo.log 文件来存储日志。这个新的日志文件无需手动创建,如果不存在,系统会自动生成。
编辑 /etc/sudoers 文件,采用 visudo 命令,并在其中添加以下内容:
Defaults logfile="/var/log/sudo.log"
保存该文件后,便可以在其中查看哪些命令在何时、由哪位用户通过 sudo 运行了。
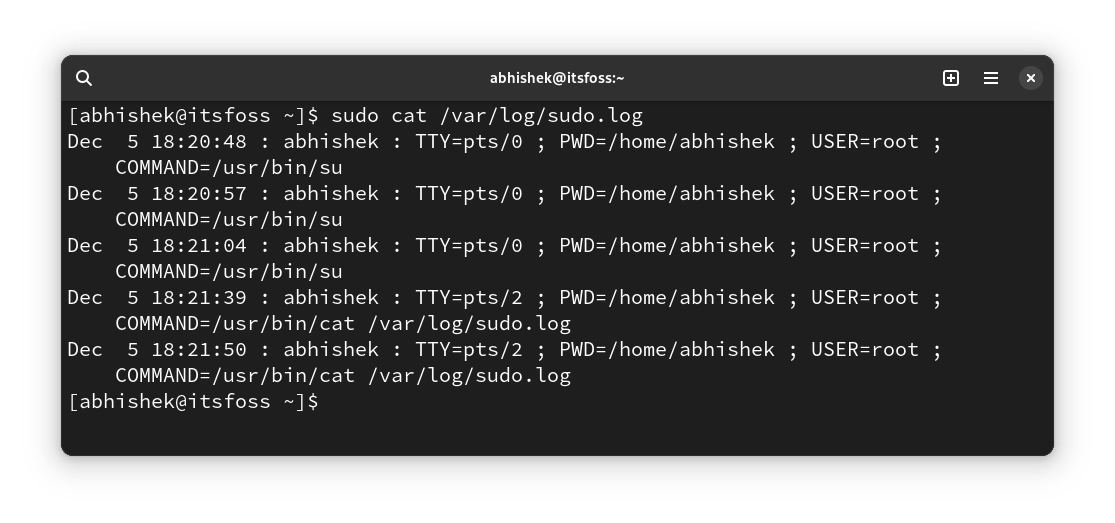
6、限制特定用户组使用 sudo 执行特定命令
这是一种高级解决方案,系统管理员在需要跨部门共享服务器的多用户环境中会使用。
开发者可能会需要以 root 权限运行 Web 服务器或其他程序,但全权给予他们 sudo 权限会带来安全风险。我建议在群组级别进行此项操作。例如,创建命名为 coders 的群组,并允许它们运行在 /var/www 和 /opt/bin/coders 目录下的命令(或可执行文件),以及 inxi 命令(路径是 /usr/bin/inxi 的二进制文件)。这是一个假想情景,实际操作请谨慎对待。
接下来,用 sudo visudo 编辑 sudoer 文件,再添加以下行:
%coders ALL=(ALL:ALL) /var/www,/opt/bin/coders,/usr/bin/inxi
如有需要,可以添加 NOPASSWD 参数,这样允许使用 sudo 运行的命令就不再需要密码了。
关于 ALL=(ALL:ALL) 的详细解读,我们将会在其他文章中进行讲解,毕竟这篇文章已经解释的内容足够多了。
7、检查用户的 sudo 权限
好吧,这是个小提示,而不是系统调优技巧。
如何确认一个用户是否具有 sudo 权限呢?可能有人会说,查看他们是否是 sudo 组的成员。但这并不一定准确,因为有些发行版用的是 wheel 代替 sudo 分组。
更佳的方法是利用 sudo 内建的功能,看看用户具有哪种 sudo 权限:
sudo -l -U user_name
这将显示出用户具有执行部分命令或所有命令的 sudo 权限。
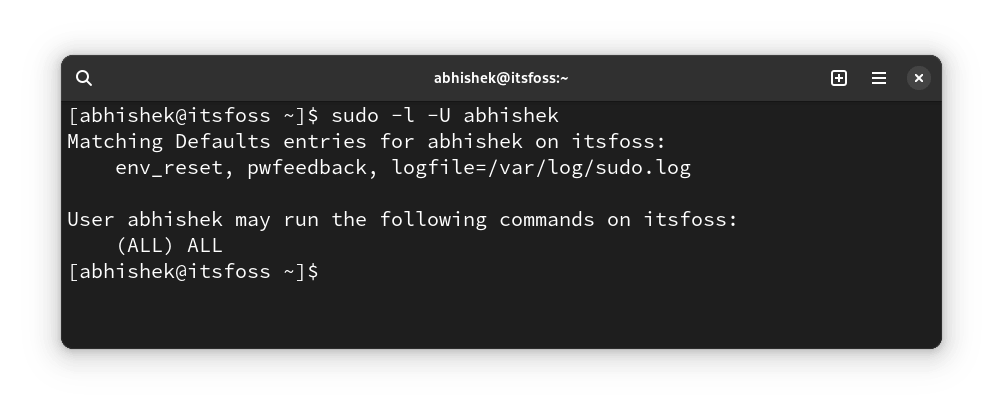
如你所见,我拥有自定义日志文件、密码反馈以及执行所有命令的 sudo 权限。
如果一个用户完全没有 sudo 权限,你将看到如下提示:
User prakash is not allowed to run sudo on this-that-server.
? 附加内容:输错 sudo 密码时,让系统“侮辱”你
这是个我在文章开头提到的“无用”小调整。
我想你在使用 sudo 时肯定曾误输过密码,对吧?
这个小技巧就是,在你每次输错密码时,让 sudo 抛出随机的“侮辱”。
用 sudo visudo 修改 sudo 配置文件,然后添加以下行:
Defaults insults
修改后,你可以故意输错密码,测试新的设置。
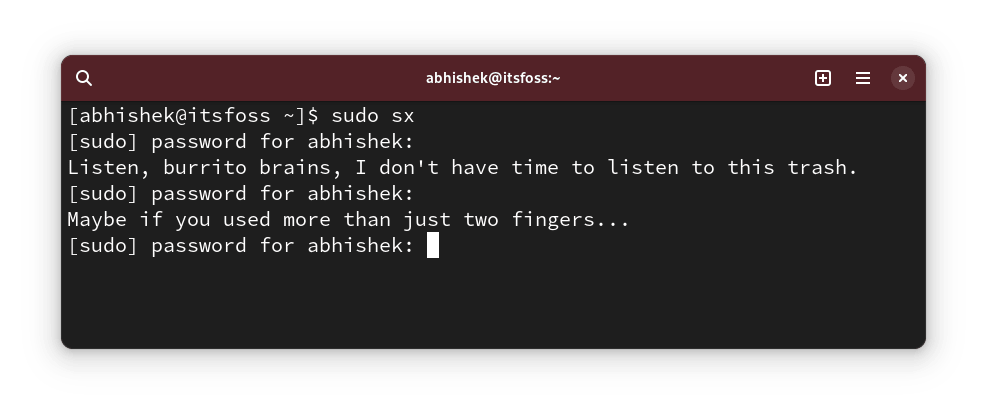
你可能在想,谁会喜欢被侮辱呢?只有粉丝可以以直白的方式告诉你 ?
你是如何运用 sudo 的?

我知道定制化的可能性无穷无尽,但其实,一般的 Linux 用户并不会去自定义 sudo。
尽管如此,我还是热衷于与你分享这些因为你可能会发现一些新奇且实用的东西。
? 那么,你有发现什么新的东西吗?请在评论区告诉我。你有一些秘密的 sudo 技巧欢迎和大家分享!
(题图:DA/a12900e5-e197-455e-adfc-0b52e4305b91)
via: https://itsfoss.com/sudo-tips/
作者:Abhishek Prakash 选题:lujun9972 译者:ChatGPT 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出





















")