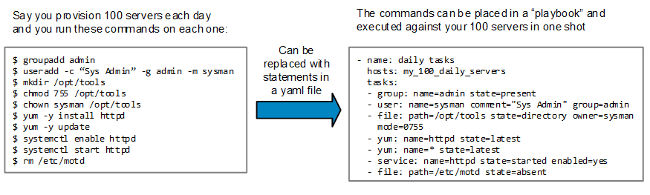
屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了课程 8:屏幕03 的操作系统代码,我们将以它为基础。
1、操作字符串
能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 sprintf 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
这个完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
函数通过读取格式化字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数的返回值是写入的字符数。如果方法失败,将返回一个负数。
表 1.1 sprintf 格式化规则
| 选项 | 含义 |
|---|
除了 % 之外的任何支付 | 复制字符到输出。 |
%% | 写一个 % 字符到输出。 |
%c | 将下一个参数写成字符格式。 |
%d 或 %i | 将下一个参数写成十进制的有符号整数。 |
%e | 将下一个参数写成科学记数法,使用 eN,意思是 ×10 N。 |
%E | 将下一个参数写成科学记数法,使用 EN,意思是 ×10 N。 |
%f | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
%g | 与 %e 和 %f 的指数表示形式相同。 |
%G | 与 %E 和 %f 的指数表示形式相同。 |
%o | 将下一个参数写成八进制的无符号整数。 |
%s | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
%u | 将下一个参数写成十进制无符号整数。 |
%x | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
%X | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
%p | 将下一个参数写成指针地址。 |
%n | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 sprintf - C++ 参考 上找到。
下面是调用方法和返回的结果的示例。
表 1.2 sprintf 调用示例
| 格式化字符串 | 参数 | 结果 |
|---|
"%d" | 13 | 13 |
"+%d degrees" | 12 | +12 degrees |
"+%x degrees" | 24 | +1c degrees |
"'%c' = 0%o" | 65, 65 | ‘A’ = 0101 |
"%d * %d%% = %d" | 200, 40, 80 | 200 * 40% = 80 |
"+%d degrees" | -5 | +-5 degrees |
"+%u degrees" | -5 | +4294967291 degrees |
希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
2、除法
虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
最简单的方法或许就是我在 课程 1:OK01 中提到的“除法余数法”。它的思路如下:
- 用当前值除以你使用的底。
- 保存余数。
- 如果得到的新值不为 0,转到第 1 步。
- 将余数反序连起来就是答案。
例如:
表 2.1 以 2 为底的例子
转换
| 值 | 新值 | 余数 |
|---|
| 137 | 68 | 1 |
| 68 | 34 | 0 |
| 34 | 17 | 0 |
| 17 | 8 | 1 |
| 8 | 4 | 0 |
| 4 | 2 | 0 |
| 2 | 1 | 0 |
| 1 | 0 | 1 |
因此答案是 10001001 2
这个过程的不幸之外在于使用了除法。所以,我们必须首先要考虑二进制中的除法。
我们复习一下长除法
假如我们想把 4135 除以 17。
0243 r 4
17)4135
0 0 × 17 = 0000
4135 4135 - 0 = 4135
34 200 × 17 = 3400
735 4135 - 3400 = 735
68 40 × 17 = 680
55 735 - 680 = 55
51 3 × 17 = 51
4 55 - 51 = 4
答案:243 余 4
首先我们来看被除数的最高位。我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
接下来我们看被除数的第三位和所有高位。我们看到小于或等于那个数的除数的最小倍数是 68。我们在结果中写一个 4,和减去 680。
最后,我们看一下所有的余位。我们看到小于余数的除数的最小倍数是 51。我们在结果中写一个 3,减去 51。减法的结果就是我们的余数。
在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
1011 r 1
1010)1101111
1010
11111
1010
1011
1010
1
这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 1101111 2 ÷ 1010 2 = 1011 2 余数为 1 2。用十进制表示就是,111 ÷ 10 = 11 余 1。
你自己尝试去实现这个长除法。你应该去写一个函数 DivideU32 ,其中 r0 是被除数,而 r1 是除数,在 r0 中返回结果,在 r1 中返回余数。下面,我们将完成一个有效的实现。
function DivideU32(r0 is dividend, r1 is divisor)
set shift to 31
set result to 0
while shift ≥ 0
if dividend ≥ (divisor << shift) then
set dividend to dividend - (divisor << shift)
set result to result + 1
end if
set result to result << 1
set shift to shift - 1
loop
return (result, dividend)
end function
这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 divisor << shift 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
幸运的是,有一个称为 clz( 计数前导零 )的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 divisor << shift 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
我们来看一下进一步优化之后的汇编代码。
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
lsl current,r1,shift
mov remainder,r0
mov result,#0
divideU32Loop$:
cmp shift,#0
blt divideU32Return$
cmp remainder,current
addge result,result,#1
subge remainder,current
sub shift,#1
lsr current,#1
lsl result,#1
b divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 clz 命令并从中减去它来改进。在 1 ÷ 1 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
clz dest,src 将第一个寄存器 dest 中二进制表示的值的前导零的数量,保存到第二个寄存器 src 中。
.globl DivideU32
DivideU32:
result .req r0
remainder .req r1
shift .req r2
current .req r3
clz shift,r1
clz r3,r0
subs shift,r3
lsl current,r1,shift
mov remainder,r0
mov result,#0
blt divideU32Return$
divideU32Loop$:
cmp remainder,current
blt divideU32LoopContinue$
add result,result,#1
subs remainder,current
lsleq result,shift
beq divideU32Return$
divideU32LoopContinue$:
subs shift,#1
lsrge current,#1
lslge result,#1
bge divideU32Loop$
divideU32Return$:
.unreq current
mov pc,lr
.unreq result
.unreq remainder
.unreq shift
复制上面的代码到一个名为 maths.s 的文件中。
3、数字字符串
现在,我们已经可以做除法了,我们来看一下另外的一个将数字转换为字符串的实现。下列的伪代码将寄存器中的一个数字转换成以 36 为底的字符串。根据惯例,a % b 表示 a 被 b 相除之后的余数。
function SignedString(r0 is value, r1 is dest, r2 is base)
if value ≥ 0
then return UnsignedString(value, dest, base)
otherwise
if dest > 0 then
setByte(dest, '-')
set dest to dest + 1
end if
return UnsignedString(-value, dest, base) + 1
end if
end function
function UnsignedString(r0 is value, r1 is dest, r2 is base)
set length to 0
do
set (value, rem) to DivideU32(value, base)
if rem > 10
then set rem to rem + '0'
otherwise set rem to rem - 10 + 'a'
if dest > 0
then setByte(dest + length, rem)
set length to length + 1
while value > 0
if dest > 0
then ReverseString(dest, length)
return length
end function
function ReverseString(r0 is string, r1 is length)
set end to string + length - 1
while end > start
set temp1 to readByte(start)
set temp2 to readByte(end)
setByte(start, temp2)
setByte(end, temp1)
set start to start + 1
set end to end - 1
end while
end function
上述代码实现在一个名为 text.s 的汇编文件中。记住,如果你遇到了困难,可以在下载页面找到完整的解决方案。
4、格式化字符串
我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 a % b 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 %s 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
- 设置 r0 = 5、r1 = 6、r2 = 7、r3 = 8
- 推入 {r0,r1,r2,r3}
- 设置 r0 = 1、r1 = 2、r2 = 3、r3 = 4
- 调用函数
- 将 sp 和 #4*4 加起来
现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 r0 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 r1 中,目标字符串地址放在寄存器 r2 中,紧接着是要求的参数列表,从寄存器 r3 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 r3 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
如果你希望尝试实现你自己的函数,现在就可以去做了。如果不去实现你自己的,下面我将首先构建方法的伪代码,然后给出实现的汇编代码。
function StringFormat(r0 is format, r1 is formatLength, r2 is dest, ...)
set index to 0
set length to 0
while index < formatLength
if readByte(format + index) = '%' then
set index to index + 1
if readByte(format + index) = '%' then
if dest > 0
then setByte(dest + length, '%')
set length to length + 1
otherwise if readByte(format + index) = 'c' then
if dest > 0
then setByte(dest + length, nextArg)
set length to length + 1
otherwise if readByte(format + index) = 'd' or 'i' then
set length to length + SignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'o' then
set length to length + UnsignedString(nextArg, dest, 8)
otherwise if readByte(format + index) = 'u' then
set length to length + UnsignedString(nextArg, dest, 10)
otherwise if readByte(format + index) = 'b' then
set length to length + UnsignedString(nextArg, dest, 2)
otherwise if readByte(format + index) = 'x' then
set length to length + UnsignedString(nextArg, dest, 16)
otherwise if readByte(format + index) = 's' then
set str to nextArg
while getByte(str) != '\0'
if dest > 0
then setByte(dest + length, getByte(str))
set length to length + 1
set str to str + 1
loop
otherwise if readByte(format + index) = 'n' then
setWord(nextArg, length)
end if
otherwise
if dest > 0
then setByte(dest + length, readByte(format + index))
set length to length + 1
end if
set index to index + 1
loop
return length
end function
虽然这个函数很大,但它还是很简单的。大多数的代码都是在检查所有各种条件,每个代码都是很简单的。此外,所有的无符号整数的大小写都是相同的(除了底以外)。因此在汇编中可以将它们汇总。下面是它的汇编代码。
.globl FormatString
FormatString:
format .req r4
formatLength .req r5
dest .req r6
nextArg .req r7
argList .req r8
length .req r9
push {r4,r5,r6,r7,r8,r9,lr}
mov format,r0
mov formatLength,r1
mov dest,r2
mov nextArg,r3
add argList,sp,#7*4
mov length,#0
formatLoop$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatArg$
formatChar$:
teq dest,#0
strneb r0,[dest]
addne dest,#1
add length,#1
b formatLoop$
formatArg$:
subs formatLength,#1
movlt r0,length
poplt {r4,r5,r6,r7,r8,r9,pc}
ldrb r0,[format]
add format,#1
teq r0,#'%'
beq formatChar$
teq r0,#'c'
moveq r0,nextArg
ldreq nextArg,[argList]
addeq argList,#4
beq formatChar$
teq r0,#'s'
beq formatString$
teq r0,#'d'
beq formatSigned$
teq r0,#'u'
teqne r0,#'x'
teqne r0,#'b'
teqne r0,#'o'
beq formatUnsigned$
b formatLoop$
formatString$:
ldrb r0,[nextArg]
teq r0,#0x0
ldreq nextArg,[argList]
addeq argList,#4
beq formatLoop$
add length,#1
teq dest,#0
strneb r0,[dest]
addne dest,#1
add nextArg,#1
b formatString$
formatSigned$:
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
mov r2,#10
bl SignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
formatUnsigned$:
teq r0,#'u'
moveq r2,#10
teq r0,#'x'
moveq r2,#16
teq r0,#'b'
moveq r2,#2
teq r0,#'o'
moveq r2,#8
mov r0,nextArg
ldr nextArg,[argList]
add argList,#4
mov r1,dest
bl UnsignedString
teq dest,#0
addne dest,r0
add length,r0
b formatLoop$
5、一个转换操作系统
你可以使用这个方法随意转换你希望的任何东西。比如,下面的代码将生成一个换算表,可以做从十进制到二进制到十六进制到八进制以及到 ASCII 的换算操作。
删除 main.s 文件中 bl SetGraphicsAddress 之后的所有代码,然后粘贴以下的代码进去。
mov r4,#0
loop$:
ldr r0,=format
mov r1,#formatEnd-format
ldr r2,=formatEnd
lsr r3,r4,#4
push {r3}
push {r3}
push {r3}
push {r3}
bl FormatString
add sp,#16
mov r1,r0
ldr r0,=formatEnd
mov r2,#0
mov r3,r4
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
cmp r3,#768-16
subhi r3,#768
addhi r2,#256
bl DrawString
add r4,#16
b loop$
.section .data
format:
.ascii "%d=0b%b=0x%x=0%o='%c'"
formatEnd:
你能在测试之前推算出将发生什么吗?特别是对于 r3 ≥ 128 会发生什么?尝试在树莓派上运行它,看看你是否猜对了。如果不能正常运行,请查看我们的排错页面。
如果一切顺利,恭喜你!你已经完成了屏幕04 教程,屏幕系列的课程结束了!我们学习了像素和帧缓冲的知识,以及如何将它们应用到树莓派上。我们学习了如何绘制简单的线条,也学习如何绘制字符,以及将数字格式化为文本的宝贵技能。我们现在已经拥有了在一个操作系统上进行图形输出的全部知识。你可以写出更多的绘制方法吗?三维绘图是什么?你能实现一个 24 位帧缓冲吗?能够从命令行上读取帧缓冲的大小吗?
接下来的课程是输入系列课程,它将教我们如何使用键盘和鼠标去实现一个传统的计算机控制台。
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
作者:Alex Chadwick 选题:lujun9972 译者:qhwdw 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出