给新手的 20 多个 FFmpeg 命令示例

在这个指南中,我将用示例来阐明如何使用 FFmpeg 媒体框架来做各种各样的音频、视频转码和转换的操作。我已经为初学者汇集了最常用的 20 多个 FFmpeg 命令,我将不时地添加更多的示例来保持更新这个指南。请给这个指南加书签,以后回来检查更新。让我们开始吧,如果你还没有在你的 Linux 系统中安装 FFmpeg,参考下面的指南。
针对初学者的 20 多个 FFmpeg 命令
FFmpeg 命令的典型语法是:
ffmpeg [全局选项] {[输入文件选项] -i 输入_url_地址} ...
{[输出文件选项] 输出_url_地址} ...现在我们将查看一些重要的和有用的 FFmpeg 命令。
1、获取音频/视频文件信息
为显示你的媒体文件细节,运行:
$ ffmpeg -i video.mp4样本输出:
ffmpeg version n4.1.3 Copyright (c) 2000-2019 the FFmpeg developers
built with gcc 8.2.1 (GCC) 20181127
configuration: --prefix=/usr --disable-debug --disable-static --disable-stripping --enable-fontconfig --enable-gmp --enable-gnutls --enable-gpl --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libdrm --enable-libfreetype --enable-libfribidi --enable-libgsm --enable-libiec61883 --enable-libjack --enable-libmodplug --enable-libmp3lame --enable-libopencore_amrnb --enable-libopencore_amrwb --enable-libopenjpeg --enable-libopus --enable-libpulse --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libv4l2 --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxcb --enable-libxml2 --enable-libxvid --enable-nvdec --enable-nvenc --enable-omx --enable-shared --enable-version3
libavutil 56. 22.100 / 56. 22.100
libavcodec 58. 35.100 / 58. 35.100
libavformat 58. 20.100 / 58. 20.100
libavdevice 58. 5.100 / 58. 5.100
libavfilter 7. 40.101 / 7. 40.101
libswscale 5. 3.100 / 5. 3.100
libswresample 3. 3.100 / 3. 3.100
libpostproc 55. 3.100 / 55. 3.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'video.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf58.20.100
Duration: 00:00:28.79, start: 0.000000, bitrate: 454 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p(tv, smpte170m/bt470bg/smpte170m), 1920x1080 [SAR 1:1 DAR 16:9], 318 kb/s, 30 fps, 30 tbr, 15360 tbn, 60 tbc (default)
Metadata:
handler_name : ISO Media file produced by Google Inc. Created on: 04/08/2019.
Stream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 128 kb/s (default)
Metadata:
handler_name : ISO Media file produced by Google Inc. Created on: 04/08/2019.
At least one output file must be specified如你在上面的输出中看到的,FFmpeg 显示该媒体文件信息,以及 FFmpeg 细节,例如版本、配置细节、版权标记、构建参数和库选项等等。
如果你不想看 FFmpeg 标语和其它细节,而仅仅想看媒体文件信息,使用 -hide_banner 标志,像下面。
$ ffmpeg -i video.mp4 -hide_banner样本输出:
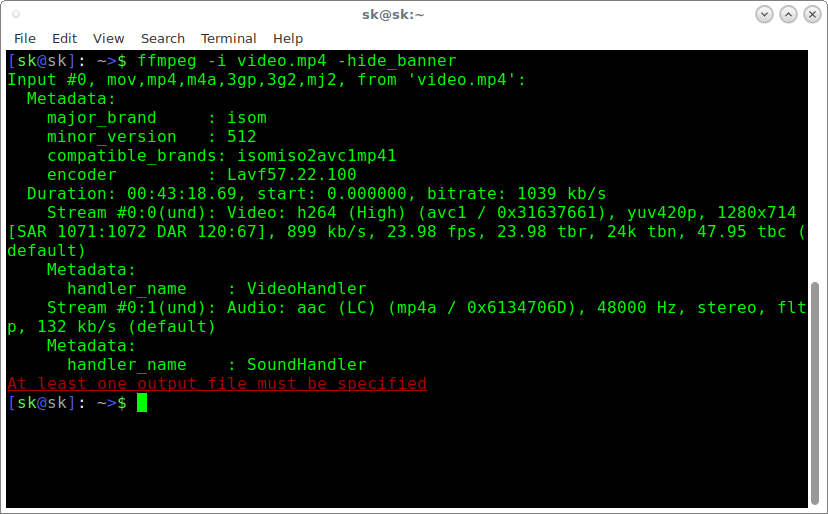
使用 FFMpeg 查看音频、视频文件信息。
看见了吗?现在,它仅显示媒体文件细节。
2、转换视频文件到不同的格式
FFmpeg 是强有力的音频和视频转换器,因此,它能在不同格式之间转换媒体文件。举个例子,要转换 mp4 文件到 avi 文件,运行:
$ ffmpeg -i video.mp4 video.avi类似地,你可以转换媒体文件到你选择的任何格式。
例如,为转换 YouTube flv 格式视频为 mpeg 格式,运行:
$ ffmpeg -i video.flv video.mpeg如果你想维持你的源视频文件的质量,使用 -qscale 0 参数:
$ ffmpeg -i input.webm -qscale 0 output.mp4为检查 FFmpeg 的支持格式的列表,运行:
$ ffmpeg -formats3、转换视频文件到音频文件
我转换一个视频文件到音频文件,只需具体指明输出格式,像 .mp3,或 .ogg,或其它任意音频格式。
上面的命令将转换 input.mp4 视频文件到 output.mp3 音频文件。
$ ffmpeg -i input.mp4 -vn output.mp3此外,你也可以对输出文件使用各种各样的音频转换编码选项,像下面演示。
$ ffmpeg -i input.mp4 -vn -ar 44100 -ac 2 -ab 320 -f mp3 output.mp3在这里,
-vn– 表明我们已经在输出文件中禁用视频录制。-ar– 设置输出文件的音频频率。通常使用的值是22050 Hz、44100 Hz、48000 Hz。-ac– 设置音频通道的数目。-ab– 表明音频比特率。-f– 输出文件格式。在我们的实例中,它是 mp3 格式。
4、更改视频文件的分辨率
如果你想设置一个视频文件为指定的分辨率,你可以使用下面的命令:
$ ffmpeg -i input.mp4 -filter:v scale=1280:720 -c:a copy output.mp4或,
$ ffmpeg -i input.mp4 -s 1280x720 -c:a copy output.mp4上面的命令将设置所给定视频文件的分辨率到 1280×720。
类似地,为转换上面的文件到 640×480 大小,运行:
$ ffmpeg -i input.mp4 -filter:v scale=640:480 -c:a copy output.mp4或者,
$ ffmpeg -i input.mp4 -s 640x480 -c:a copy output.mp4这个技巧将帮助你缩放你的视频文件到较小的显示设备上,例如平板电脑和手机。
5、压缩视频文件
减小媒体文件的大小到较小来节省硬件的空间总是一个好主意.
下面的命令将压缩并减少输出文件的大小。
$ ffmpeg -i input.mp4 -vf scale=1280:-1 -c:v libx264 -preset veryslow -crf 24 output.mp4请注意,如果你尝试减小视频文件的大小,你将损失视频质量。如果 24 太有侵略性,你可以降低 -crf 值到或更低值。
你也可以通过下面的选项来转换编码音频降低比特率,使其有立体声感,从而减小大小。
-ac 2 -c:a aac -strict -2 -b:a 128k6、压缩音频文件
正像压缩视频文件一样,为节省一些磁盘空间,你也可以使用 -ab 标志压缩音频文件。
例如,你有一个 320 kbps 比特率的音频文件。你想通过更改比特率到任意较低的值来压缩它,像下面。
$ ffmpeg -i input.mp3 -ab 128 output.mp3各种各样可用的音频比特率列表是:
- 96kbps
- 112kbps
- 128kbps
- 160kbps
- 192kbps
- 256kbps
- 320kbps
7、从一个视频文件移除音频流
如果你不想要一个视频文件中的音频,使用 -an 标志。
$ ffmpeg -i input.mp4 -an output.mp4在这里,-an 表示没有音频录制。
上面的命令会撤销所有音频相关的标志,因为我们不要来自 input.mp4 的音频。
8、从一个媒体文件移除视频流
类似地,如果你不想要视频流,你可以使用 -vn 标志从媒体文件中简单地移除它。-vn 代表没有视频录制。换句话说,这个命令转换所给定媒体文件为音频文件。
下面的命令将从所给定媒体文件中移除视频。
$ ffmpeg -i input.mp4 -vn output.mp3你也可以使用 -ab 标志来指出输出文件的比特率,如下面的示例所示。
$ ffmpeg -i input.mp4 -vn -ab 320 output.mp39、从视频中提取图像
FFmpeg 的另一个有用的特色是我们可以从一个视频文件中轻松地提取图像。如果你想从一个视频文件中创建一个相册,这可能是非常有用的。
为从一个视频文件中提取图像,使用下面的命令:
$ ffmpeg -i input.mp4 -r 1 -f image2 image-%2d.png在这里,
-r– 设置帧速度。即,每秒提取帧到图像的数字。默认值是 25。-f– 表示输出格式,即,在我们的实例中是图像。image-%2d.png– 表明我们如何想命名提取的图像。在这个实例中,命名应该像这样image-01.png、image-02.png、image-03.png 等等开始。如果你使用%3d,那么图像的命名像 image-001.png、image-002.png 等等开始。
10、裁剪视频
FFMpeg 允许以我们选择的任何范围裁剪一个给定的媒体文件。
裁剪一个视频文件的语法如下给定:
ffmpeg -i input.mp4 -filter:v "crop=w:h:x:y" output.mp4在这里,
input.mp4– 源视频文件。-filter:v– 表示视频过滤器。crop– 表示裁剪过滤器。w– 我们想自源视频中裁剪的矩形的宽度。h– 矩形的高度。x– 我们想自源视频中裁剪的矩形的 x 坐标 。y– 矩形的 y 坐标。
比如说你想要一个来自视频的位置 (200,150),且具有 640 像素宽度和 480 像素高度的视频,命令应该是:
$ ffmpeg -i input.mp4 -filter:v "crop=640:480:200:150" output.mp4请注意,剪切视频将影响质量。除非必要,请勿剪切。
11、转换一个视频的具体的部分
有时,你可能想仅转换视频文件的一个具体的部分到不同的格式。以示例说明,下面的命令将转换所给定视频input.mp4 文件的开始 10 秒到视频 .avi 格式。
$ ffmpeg -i input.mp4 -t 10 output.avi在这里,我们以秒具体说明时间。此外,以 hh.mm.ss 格式具体说明时间也是可以的。
12、设置视频的屏幕高宽比
你可以使用 -aspect 标志设置一个视频文件的屏幕高宽比,像下面。
$ ffmpeg -i input.mp4 -aspect 16:9 output.mp4通常使用的高宽比是:
- 16:9
- 4:3
- 16:10
- 5:4
- 2:21:1
- 2:35:1
- 2:39:1
13、添加海报图像到音频文件
你可以添加海报图像到你的文件,以便图像将在播放音频文件时显示。这对托管在视频托管主机或共享网站中的音频文件是有用的。
$ ffmpeg -loop 1 -i inputimage.jpg -i inputaudio.mp3 -c:v libx264 -c:a aac -strict experimental -b:a 192k -shortest output.mp414、使用开始和停止时间剪下一段媒体文件
可以使用开始和停止时间来剪下一段视频为小段剪辑,我们可以使用下面的命令。
$ ffmpeg -i input.mp4 -ss 00:00:50 -codec copy -t 50 output.mp4在这里,
–ss– 表示视频剪辑的开始时间。在我们的示例中,开始时间是第 50 秒。-t– 表示总的持续时间。
当你想使用开始和结束时间从一个音频或视频文件剪切一部分时,它是非常有用的。
类似地,我们可以像下面剪下音频。
$ ffmpeg -i audio.mp3 -ss 00:01:54 -to 00:06:53 -c copy output.mp315、切分视频文件为多个部分
一些网站将仅允许你上传具体指定大小的视频。在这样的情况下,你可以切分大的视频文件到多个较小的部分,像下面。
$ ffmpeg -i input.mp4 -t 00:00:30 -c copy part1.mp4 -ss 00:00:30 -codec copy part2.mp4在这里,
-t 00:00:30表示从视频的开始到视频的第 30 秒创建一部分视频。-ss 00:00:30为视频的下一部分显示开始时间戳。它意味着第 2 部分将从第 30 秒开始,并将持续到原始视频文件的结尾。
16、接合或合并多个视频部分到一个
FFmpeg 也可以接合多个视频部分,并创建一个单个视频文件。
创建包含你想接合文件的准确的路径的 join.txt。所有的文件都应该是相同的格式(相同的编码格式)。所有文件的路径应该逐个列出,像下面。
file /home/sk/myvideos/part1.mp4
file /home/sk/myvideos/part2.mp4
file /home/sk/myvideos/part3.mp4
file /home/sk/myvideos/part4.mp4现在,接合所有文件,使用命令:
$ ffmpeg -f concat -i join.txt -c copy output.mp4如果你得到一些像下面的错误;
[concat @ 0x555fed174cc0] Unsafe file name '/path/to/mp4'
join.txt: Operation not permitted添加 -safe 0 :
$ ffmpeg -f concat -safe 0 -i join.txt -c copy output.mp4上面的命令将接合 part1.mp4、part2.mp4、part3.mp4 和 part4.mp4 文件到一个称为 output.mp4 的单个文件中。
17、添加字幕到一个视频文件
我们可以使用 FFmpeg 来添加字幕到视频文件。为你的视频下载正确的字幕,并如下所示添加它到你的视频。
$ fmpeg -i input.mp4 -i subtitle.srt -map 0 -map 1 -c copy -c:v libx264 -crf 23 -preset veryfast output.mp418、预览或测试视频或音频文件
你可能希望通过预览来验证或测试输出的文件是否已经被恰当地转码编码。为完成预览,你可以从你的终端播放它,用命令:
$ ffplay video.mp4类似地,你可以测试音频文件,像下面所示。
$ ffplay audio.mp319、增加/减少视频播放速度
FFmpeg 允许你调整视频播放速度。
为增加视频播放速度,运行:
$ ffmpeg -i input.mp4 -vf "setpts=0.5*PTS" output.mp4该命令将双倍视频的速度。
为降低你的视频速度,你需要使用一个大于 1 的倍数。为减少播放速度,运行:
$ ffmpeg -i input.mp4 -vf "setpts=4.0*PTS" output.mp420、创建动画的 GIF
出于各种目的,我们在几乎所有的社交和专业网络上使用 GIF 图像。使用 FFmpeg,我们可以简单地和快速地创建动画的视频文件。下面的指南阐释了如何在类 Unix 系统中使用 FFmpeg 和 ImageMagick 创建一个动画的 GIF 文件。
21、从 PDF 文件中创建视频
我长年累月的收集了很多 PDF 文件,大多数是 Linux 教程,保存在我的平板电脑中。有时我懒得从平板电脑中阅读它们。因此,我决定从 PDF 文件中创建一个视频,在一个大屏幕设备(像一台电视机或一台电脑)中观看它们。如果你想知道如何从一批 PDF 文件中制作一个电影,下面的指南将帮助你。
22、获取帮助
在这个指南中,我已经覆盖大多数常常使用的 FFmpeg 命令。它有很多不同的选项来做各种各样的高级功能。要学习更多用法,请参考手册页。
$ man ffmpeg这就是全部了。我希望这个指南将帮助你入门 FFmpeg。如果你发现这个指南有用,请在你的社交和专业网络上分享它。更多好东西将要来。敬请期待!
谢谢!
via: https://www.ostechnix.com/20-ffmpeg-commands-beginners/