如何在 Linux 中创建和管理归档文件

简而言之,归档是一个包含一系列文件和(或)目录的单一文件。归档文件通常用于在本地或互联网上传输,或作为一个一系列文件和目录的备份副本,从而允许你使用一个文件来工作(如果压缩,则其大小会小于所有文件的总和)。同样的,归档也用于软件应用程序打包。为了方便传输,可以很容易地压缩这个单一文件,而存档中的文件会保留原始结构和权限。
我们可以使用 tar 工具来创建、列出和提取归档中的文件。用 tar 生成的归档通常称为“tar 文件”、“tar 归档”或者“压缩包”(因为所有已归档的文件被合成了一个文件)。
本教程会展示如何使用 tar 创建、列出和提取归档中的内容。这三个操作都会使用两个公共选项 -f 和 -v:使用 -f 指定归档文件的名称,使用 -v(“冗余”)选项使 tar 在处理文件时输出文件名。虽然 -v 选项不是必需的,但是它可以让你观察 tar 操作的过程。
在本教程的下面部分中,会涵盖 3 个主题:1、创建一个归档文件;2、列出归档文件内容;3、提取归档文件内容。另外我们会回答归档文件管理的 6 个实际问题来结束本教程。你从本教程学到的内容对于执行与网络安全和云技术相关的任务至关重要。
1、创建一个归档文件
要使用 tar 创建一个归档文件,使用 -c(“创建”)选项,然后用 -f 选项指定要创建的归档文件名。通常的做法是使用带有 .tar 扩展名的名称,例如 my-backup.tar。注意,除非另有特别说明,否则本文其余部分中使用的所有命令和参数都以小写形式使用。记住,在你的终端上输入本文的命令时,无需输入每个命令行开头的 $ 提示符。
输入要归档的文件名作为参数;如果要创建一个包含所有文件及其子目录的归档文件,提供目录名称作为参数。
要归档 project 目录内容,输入:
$ tar -cvf project.tar project
这个命令将创建一个名为 project.tar 的归档文件,包含 project 目录的所有内容,而原目录 project 将保持不变。
使用 -z 选项可以对归档文件进行压缩,这样产生的输出与创建未压缩的存档然后用 gzip 压缩是一样的,但它省去了额外的步骤。
要从 project 目录创建一个 project.tar.gz 的压缩包,输入:
$ tar -zcvf project.tar.gz project
这个命令将创建一个 project.tar.gz 的压缩包,包含 project 目录的所有内容,而原目录 project 将保持不变。
注意: 在使用 -z 选项时,你应该使用 .tar.gz 扩展名而不是 .tar 扩展名,这样表示已压缩。虽然不是必须的,但这是一个很好的实践。
gzip 不是唯一的压缩形式,还有 bzip2 和 xz。当我们看到扩展名为 .xz 的文件时,我们知道该文件是使用 xz 压缩的,扩展名为 .bz2 的文件是用 bzip2 压缩的。随着 bzip2 不再维护,我们将远离它而关注 xz。使用 xz 压缩时,需要花费更长的时间。然而,等待通常是值得的,因为压缩效果要好的多,这意味着压缩包通常比使用其它压缩形式要小。更好的是,不同压缩形式之间的解压缩或提取文件并没有太大区别。下面我们将看到一个使用 tar 压缩文件时如何使用 xz 的示例:
$ tar -Jcvf project.tar.xz project
我们只需将 gzip 的 -z 选项转换为 xz 的大写 -J 即可。以下是一些输出,显示压缩形式之间的差异:

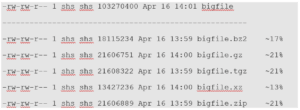
如你所见,xz 的压缩时间最长。但是,它在减小文件大小方面做的最好,所以值得等待。文件越大,压缩效果也越好。
2、列出归档文件的内容
要列出 tar 归档文件的内容但不提取,使用 -t 选项。
要列出 project.tar 的内容,输入:
$ tar -tvf project.tar
这个命令列出了 project.tar 归档的内容。-v 和 -t 选项一起使用会输出每个文件的权限和修改时间,以及文件名。这与 ls 命令使用 -l 选项时使用的格式相同。
要列出 project.tar.gz 压缩包的内容,输入:
$ tar -tzvf project.tar.gz
3、从归档中提取内容
要提取(解压)tar 归档文件中的内容,使用 -x(“提取”)选项。
要提取 project.tar 归档的内容,输入:
$ tar -xvf project.tar
这个命令会将 project.tar 归档的内容提取到当前目录。
如果一个归档文件被压缩,通常来说它的扩展名为 .tar.gz 或 .tgz,请包括 "-z" 选项。
要提取 project.tar.gz 压缩包的内容,输入:
$ tar -zxvf project.tar.gz
注意: 如果当前目录中有文件或子目录与归档文件中的内容同名,那么在提取归档文件时,这些文件或子目录将被覆盖。如果你不知道归档中包含哪些文件,请考虑先查看归档文件的内容。
在提取归档内容之前列出其内容的另一个原因是,确定归档中的内容是否包含在目录中。如果没有,而当前目录中包含许多不相关的文件,那么你可能将它们与归档中提取的文件混淆。
要将文件提取到它们自己的目录中,新建一个目录,将归档文件移到该目录,然后你就可以在新目录中提取文件。
FAQ
现在我们已经学习了如何创建归档文件并列出和提取其内容,接下来我们可以继续讨论 Linux 专业人员经常被问到的 9 个实用问题。
可以在不解压缩的情况下添加内容到压缩包中吗?
很不幸,一旦文件将被压缩,就无法向其添加内容。你需要解压缩或提取其内容,然后编辑或添加内容,最后再次压缩文件。如果文件很小,这个过程不会花费很长时间,否则请等待一会。
可以在不解压缩的情况下删除归档文件中的内容吗?
这取决压缩时使用的 tar 版本。较新版本的 tar 支持 -delete 选项。
例如,假设归档文件中有 file1 和 file2,可以使用以下命令将它们从 file.tar 中删除:
$ tar -vf file.tar –delete file1 file2
删除目录 dir1:
$ tar -f file.tar –delete dir1/*
压缩和归档之间有什么区别?
查看归档和压缩之间差异最简单的方法是查看其解压大小。归档文件时,会将多个文件合并为一个。所以,如果我们归档 10 个 100kb 文件,则最终会得到一个 100kb 大小的文件。而如果压缩这些文件,则最终可能得到一个只有几 kb 或接近 100kb 的文件。
如何压缩归档文件?
如上所说,你可以使用带有 cvf 选项的 tar 命令来创建和归档文件。要压缩归档文件,有两个选择:通过压缩程序(例如 gzip)运行归档文件,或在使用 tar 命令时使用压缩选项。最常见的压缩标志 -z 表示 gzip,-j 表示 bzip,-J 表示 xz。例如:
$ gzip file.tar
或者,我们可以在使用 tar 命令时使用压缩标志,以下命令使用 gzip 标志 z:
$ tar -cvzf file.tar /some/directory
如何一次创建多个目录和/或文件的归档?
一次要归档多个文件,这种情况并不少见。一次归档多个文件和目录并不像你想的那么难,你只需要提供多个文件或目录作为 tar 的参数即可:
$ tar -cvzf file.tar file1 file2 file3
或者
$ tar -cvzf file.tar /some/directory1 /some/directory2
创建归档时如何跳过目录和/或文件?
你可能会遇到这样的情况:要归档一个目录或文件,但不是所有文件,这种情况下可以使用 --exclude 选项:
$ tar –exclude ‘/some/directory’ -cvf file.tar /home/user
在示例中,/home/user 目录中除了 /some/directory 之外都将被归档。将 --exclude 选项放在源和目标之前,并用单引号将要排除的文件或目录引起来,这一点很重要。
总结
tar 命令对展示不需要的文件创建备份或压缩文件很有用。在更改文件之前备份它们是一个很好的做法。如果某些东西在更改后没有按预期正常工作,你始终可以还原到旧文件。压缩不再使用的文件有助于保持系统干净,并降低磁盘空间使用率。还有其它实用程序可以归档或压缩,但是 tar 因其多功能、易用性和受欢迎程度而独占鳌头。
资源
如果你想了解有关 Linux 的更多信息,强烈建议阅读以下文章和教程:
- Linux 文件系统架构和管理综述
- Linux 文件和目录系统工作原理的全面回顾
- 所有 Linux 系统发行版的综合列表
- 特殊用途 Linux 发行版的综合列表
- Linux 系统管理指南 - 制作和管理备份操作的最佳实践
- Linux 系统管理指南 - Linux 虚拟内存和磁盘缓冲区缓存概述
- Linux 系统管理指南 - 监控 Linux 的最佳实践
- Linux 系统管理指南 - Linux 启动和关闭的最佳实践
关于作者
Matt Zand 是一位创业者,也是 3 家科技创业公司的创始人: DC Web Makers、Coding Bootcamps 和 High School Technology Services。他也是 使用 Hyperledger Fabric 进行智能合约开发 一书的主要作者。他为 Hyperledger、以太坊和 Corda R3 平台编写了 100 多篇关于区块链开发的技术文章和教程。在 DC Web Makers,他领导了一个区块链专家团队,负责咨询和部署企业去中心化应用程序。作为首席架构师,他为编码训练营设计和开发了区块链课程和培训项目。他拥有马里兰大学工商管理硕士学位。在区块链开发和咨询之前,他曾担任一些初创公司的高级网页和移动应用程序开发和顾问、天使投资人和业务顾问。你可以通过以下这个网址和他取得联系: https://www.linkedin.com/in/matt-zand-64047871。
Kevin Downs 是 Red Hat 认证的系统管理员和 RHCSA。他目前在 IBM 担任系统管理员,负责管理数百台运行在不同 Linux 发行版上的服务器。他是编码训练营的首席 Linux 讲师,并且他会讲授 5 个自己的课程。
via: https://www.linux.com/news/how-to-create-and-manage-archive-files-in-linux-2/
作者:LF Training 选题:lujun9972 译者:MjSeven 校对:wxy