如何使用linux程序mdadm创建软件RAID1软阵列
磁盘冗余阵列(RAID)是将多个物理磁盘结合成一个逻辑磁盘的技术,该技术可以提高磁盘容错性能,提高磁盘的读写速度。根据数据存储的排列(如:条带存储,镜像存储,奇偶或者他们的组合),定义了几个不同级别的RAID(RAID-0,RAID-1,RAID-5 等等)。磁盘阵列可以使用软件或者硬件方式实现。现代Linux操作系统中,基本的软件RAID功能是默认安装的。
本文中,我们将介绍软件方式构建RAID-1阵列(镜像阵列),RAID-1将相同的数据写到不同的设备中。虽然可以使用同一个磁盘的两个分区实现RAID-1,但是如果磁盘坏了的话数据就都丢了,所以没什么意义。实际上,这也是为什么大多数RAID级别都使用多个物理磁盘提供冗余。当单盘失效后不影响整个阵列的运行,并且可以在线更换磁盘,最重要的是数据不会丢失。尽管如此,阵列不能取代外部存储的定期备份。
由于RAID-1阵列的大小是阵列中最小磁盘的大小,一般来说应该使用两个大小相同的磁盘来组建RAID-1。
安装mdadm
我们将使用mdadm(简称多盘管理)工具创建、组装、管理和监控软件RAID-1。在诸如Fedora、CentOS、RHEL或者Arch Linux 的发行版中,mdadm是默认安装的。在基于Debian的发行版中,可以使用aptitude 或者 apt-get 安装mdadm。
Fedora, CentOS 或 RHEL
由于adadm是预装的,所以我们只需要开启RAID守护服务,并将其配置成开机启动即可:
# systemctl start mdmonitor
# systemctl enable mdmonitor
对于CentOS/RHEL 6系统,使用以下命令:
# service mdmonitor start
# chkconfig mdmonitor on
Debian, Ubuntu 或 Linux Mint
在Debian或类Debian系统中,mdadm可以使用 aptitude 或者 apt-get 安装:
# aptitude install mdadm
Ubuntu系统中,会要求配置Postfix MTA 以发送电子邮件通知。你可以跳过去。
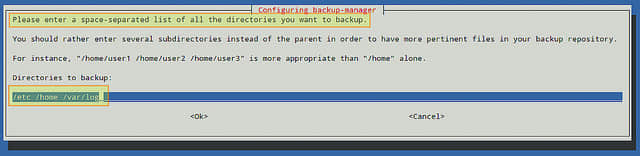
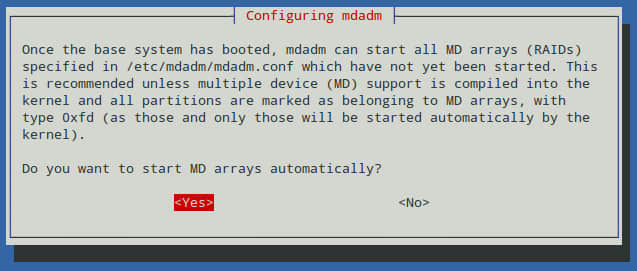
Debian系统中,安装程序会显示以下解释信息,用来帮助我们去判断是否将根目录安装到RAID阵列中。下面的所有操作都有赖于这一步,所以应该仔细阅读他。
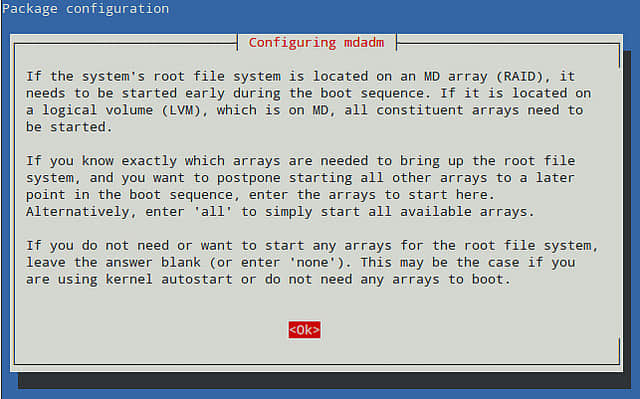
我们不在根目录使用RAID-1,所以留空。
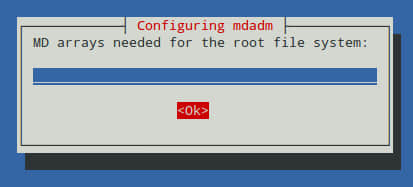
提示是否开机启动阵列的时候,选择“是”。注意,这里需要往/etc/fstab 文件中添加一个条目使得系统启动的时候正确挂载阵列。
硬盘分区
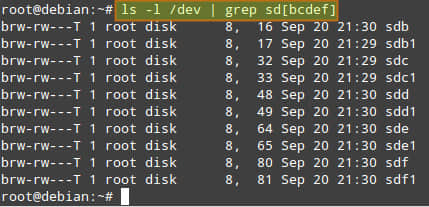
现在开始准备建立阵列需要的硬盘。这里插入两个8GB的usb磁盘,使用dmesg命令设备显示设备 /dev/sdb 和 /dev/sdc
# dmesg | less
[ 60.014863] sd 3:0:0:0: [sdb] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB) [ 75.066466] sd 4:0:0:0: [sdc] 15826944 512-byte logical blocks: (8.10 GB/7.54 GiB)
我们使用fdisk为每个磁盘建立一个大小为8G的主分区。以下步骤是如何在/dev/sdb上建立分区,假设次磁盘从未被分区(如果有其他分区的话,可以删掉):
# fdisk /dev/sdb
按p键输出现在的分区表:
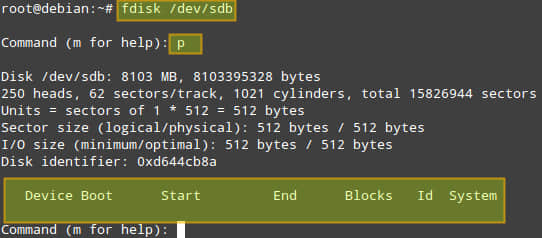
(如果有分区的话,可以使用 d 选项删除,w 选项应用更改)。
磁盘上没有分区,所以我们使用命令 ['n'] 创建一个主分区['p'], 分配分区号为['1'] 并且指定大小。你可以按回车使用默认值,或者输入一个你想设置的值。如下图:
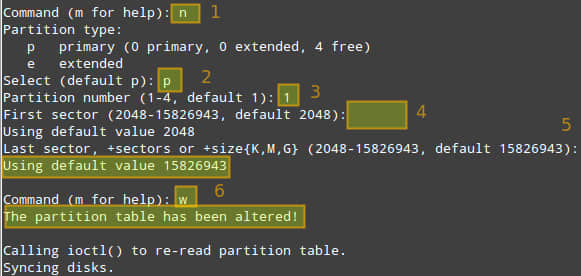
用同样的方法为/dev/sdc 分区。
如果我们有两个不同容量的硬盘,比如 750GB 和 1TB的话,我们需要在每个磁盘上分出一个750GB的主分区,大盘剩下的空间可以用作他用,不加入磁盘阵列。
创建 RAID-1 阵列
磁盘分区完成后,我们可以使用以下命令创建 RAID-1 阵列:
# mdadm -Cv /dev/md0 -l1 -n2 /dev/sdb1 /dev/sdc1
说明:
- -Cv: 创建一个阵列并打印出详细信息。
- /dev/md0: 阵列名称。
- -l1 (l as in "level"): 指定阵列类型为 RAID-1 。
- -n2: 指定我们将两个分区加入到阵列中去,分别为/dev/sdb1 和 /dev/sdc1
以上命令和下面的等价:
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1
如果你想在在磁盘失效时添加另外一个磁盘到阵列中,可以指定 '--spare-devices=1 /dev/sdd1' 到以上命令。
输入 “y” 继续创建阵列,回车:
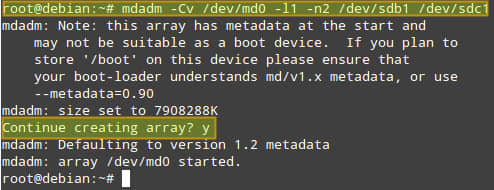
可以使用以下命令查看进度:
# cat /proc/mdstat

另外一个获取阵列信息的方法是:
# mdadm --query /dev/md0
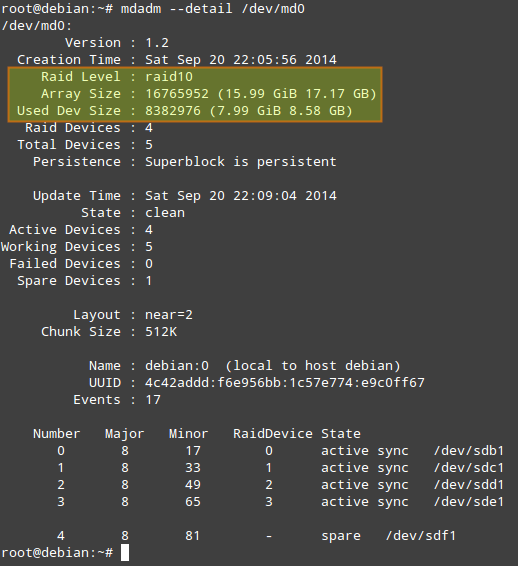
# mdadm --detail /dev/md0 (或 mdadm -D /dev/md0)
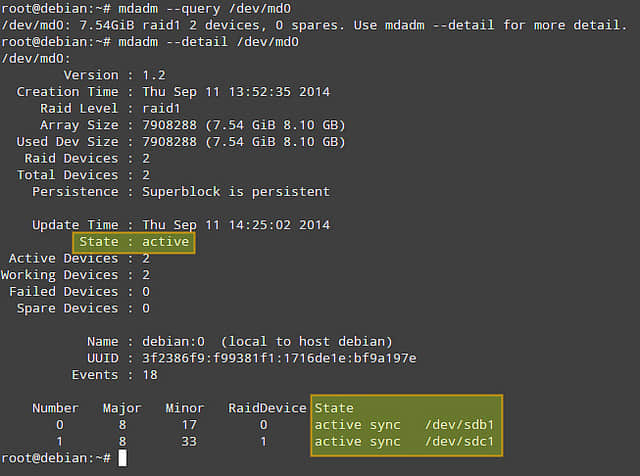
'mdadm -D'命令提供的信息中,最重要就是阵列状态类。激活状态说明阵列正在进行读写操作。其他几个状态分别为:完成(读写完成)、降级(有一块磁盘失效或丢失)或者恢复中(一张新盘已插入,系统正在写入数据)。这几个状态涵盖了大多数情况。
格式化或加载磁盘阵列
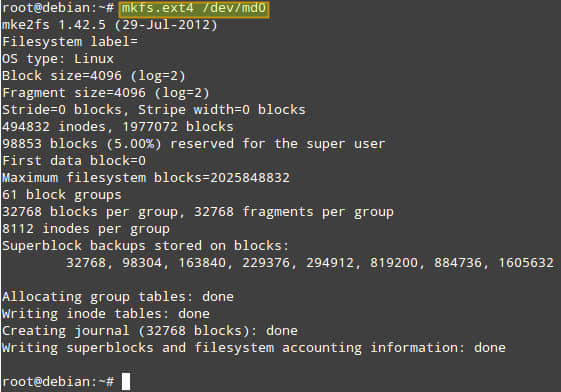
下一步就是格式化阵列了,本例中使用ext4格式:
# mkfs.ext4 /dev/md0
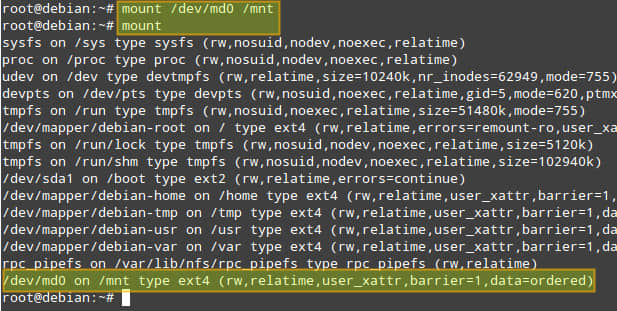
现在可以加载阵列并验证其正常加载:
# mount /dev/md0 /mnt
# mount
监控磁盘阵列
mdadm工具内置有磁盘阵列监控功能。当mdadm作为守护程序运行的时候(就像我们上文那样),会周期性的检测阵列运行状态,将检测到的信息通过电子邮件或者系统日志报告上来。当然,也可以配置其在发生致命性错误的时候调用紧急命令。
mdadm默认会记录所有已知分区和阵列的事件,并将他们记录到 /var/log/syslog中。或者你可以在配置文件中(debian系统:/etc/mdadm/mdadm.conf ,红帽子系统:/etc/mdadm.conf )用以下格式指定监控设备或者阵列。如果mdadm.conf文件不存在,你可以创建一个。
DEVICE /dev/sd[bcde]1 /dev/sd[ab]1
ARRAY /dev/md0 devices=/dev/sdb1,/dev/sdc1
ARRAY /dev/md1 devices=/dev/sdd1,/dev/sde1
.....
# optional email address to notify events
MAILADDR [email protected]
编辑完毕mdadm配置文件后,重启mdadm服务:
Debian系统,Ubuntu或者Linux Mint:
# service mdadm restart
Fedora, CentOS 或 RHEL 7:
# systemctl restart mdmonitor
CentOS或者RHEL 6:
# service mdmonitor restart
自动加载阵列
现在我们在/etc/fstab中加入条目使得系统启动的时候将阵列挂载到/mnt目录下:
# echo "/dev/md0 /mnt ext4 defaults 0 2" << /etc/fstab
为了验证挂载脚本工作正常,我们首先卸载阵列,重启mdadm,然后重新加载。可以看到/dev/md0已经安装我们添加到/etc/fstab中的条目加载了:
# umount /mnt
# service mdadm restart (on Debian, Ubuntu or Linux Mint)
or systemctl restart mdmonitor (on Fedora, CentOS/RHEL7)
or service mdmonitor restart (on CentOS/RHEL6)
# mount -a
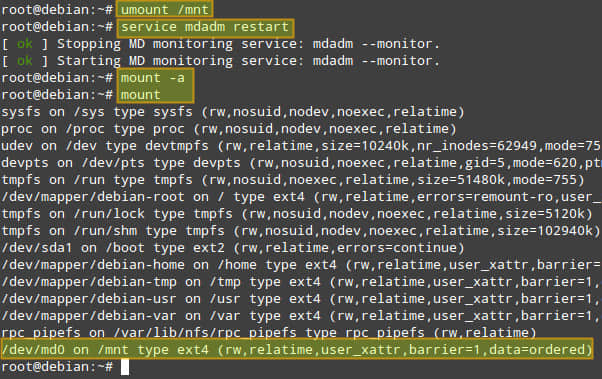
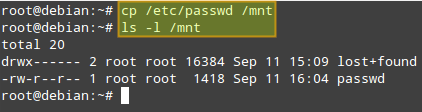
现在我们的阵列已经可以访问了,拷贝文件/etc/passwd到/mnt中测试一下:
Debian系统中,需要在/etc/default/mdadm 设置 AUTOSTART 变量为 true 才能使mdadm守护程序在开机时自动加载阵列:
AUTOSTART=true
模拟磁盘丢失故障
我们将使用以下命令卸载磁盘来模拟磁盘故障。注意,在实际应用中,磁盘如果已经是故障状态了,不需要卸载。
首先,卸载阵列:
# umount /mnt
现在注意每次执行命令后 'mdadm -D /dev/md0' 的输出。
# mdadm /dev/md0 --fail /dev/sdb1 # 标记 /dev/sdb1 为失效
# mdadm --remove /dev/md0 /dev/sdb1 # 从阵列中移走 /dev/sdb1
然后,如果你有个备用盘的话,重新添加一下:
# mdadm /dev/md0 --add /dev/sdb1
数据会被自动添加到备用盘 /dev/sdb1 上:

注意以上所述步骤只适合支持磁盘热拔插的系统,在不支持热拔插的系统中,还是得停止阵列并关机后更换备用盘:
# mdadm --stop /dev/md0
# shutdown -h now
最后将新驱动器重新添加到阵列中:
# mdadm /dev/md0 --add /dev/sdb1
# mdadm --assemble /dev/md0 /dev/sdb1 /dev/sdc1
希望本文对你有所帮助。
via: http://xmodulo.com/2014/09/create-software-raid1-array-mdadm-linux.html
作者:Gabriel Cánepa 译者:shipsw 校对:wxy