如何跨越 Kubernetes 学习曲线
Kubernetes 就像一辆翻斗车。它非常适合解决它所针对的问题,但你必须首先掌握其学习曲线。

在为什么说 Kubernetes 是一辆翻斗车中,我谈到了一个工具如何优雅地解决它所设计用来解决的问题 —— 只是你要学会如何使用它。在本系列的第 2 部分中,我将更深入地了解 Kubernetes 的学习曲线。
Kubernetes 的旅程通常从在一台主机上运行一个容器开始。你可以快速了解运行新版本软件的难易程度,与其他人分享该软件的难易程度,以及对于这些用户按照你预期方式运行它的难易程度。
但是你需要:
- 两个容器
- 两个主机
使用容器在端口 80 上启动一个 Web 服务器很容易,但是当你需要在端口 80 上启动第二个容器时会发生什么?当你构建生产环境时,需要容器化 Web 服务器在发生故障时转移到第二个主机时会发生什么?在任何一种情况下,这个答案简单来说就是你必须采用容器编排。
当你开始处理两个容器或两个主机问题时,你将不可避免地引入了复杂性,因此,这就是一个学习曲线。这个两个服务(容器的更通用说法)或两个主机的问题已经存在了很长时间,并且由此带来了复杂性。
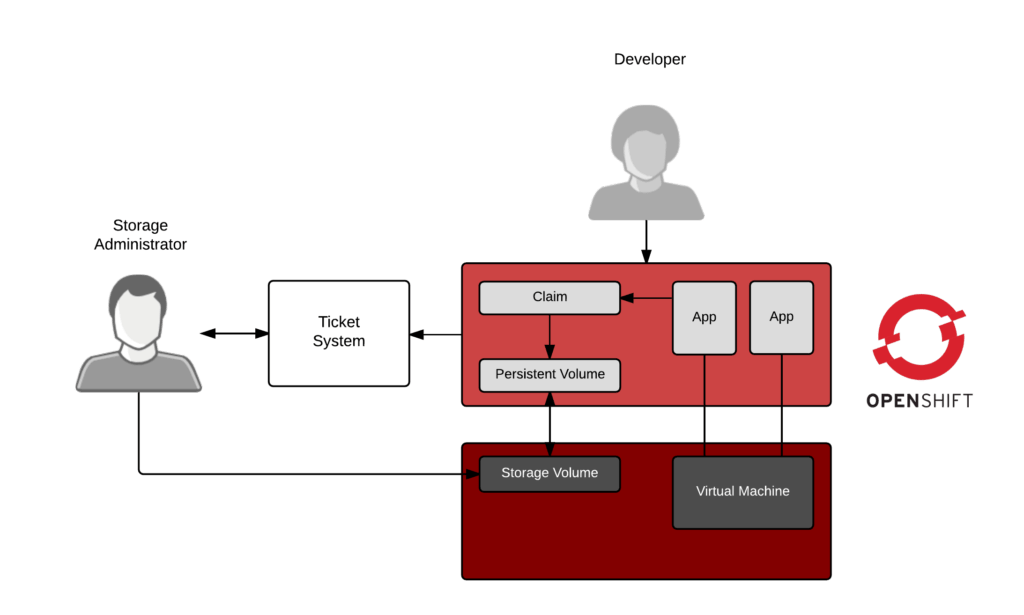
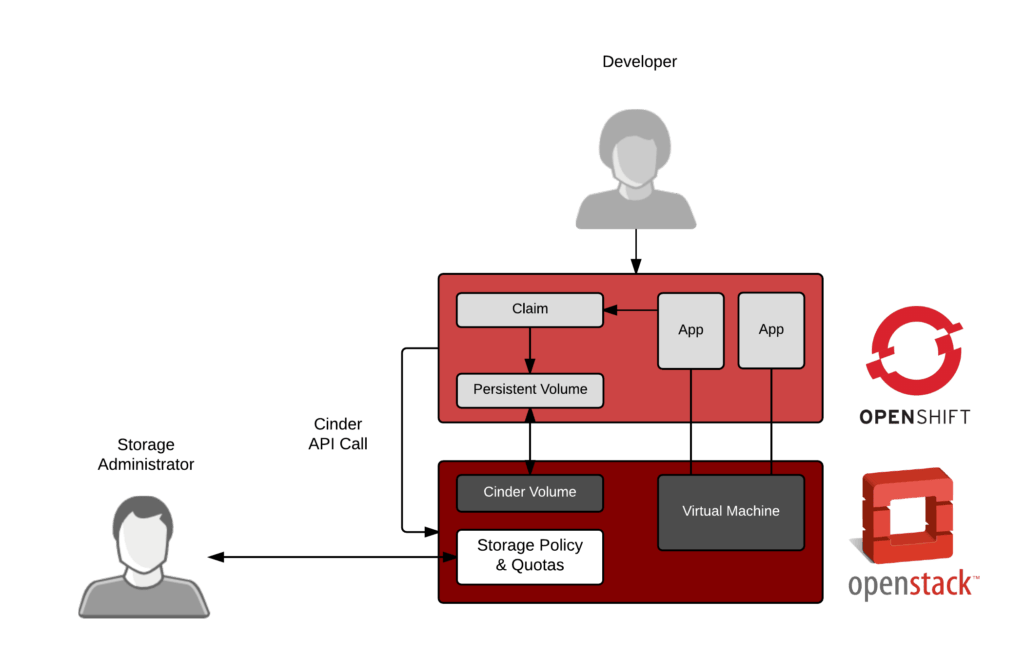
从历史上看,这将涉及负载均衡、集群软件甚至集群文件系统。每个服务的配置逻辑都嵌入在每个系统(负载均衡、集群软件和文件系统)中。在负载平衡器后运行 60 或 70 个集群的服务是复杂的。添加另一个新服务也很复杂。更糟糕的是,撤下服务简直是一场噩梦。回想起我对生产环境中的 MySQL 和 Apache 服务器进行故障排除的日子,这些服务器的逻辑嵌入在三、四个或五个不同的地方,所有这些都采用不同的格式,让我头疼不已。
Kubernetes 使用一个软件优雅地解决了所有这些问题:
- 两项服务(容器):✅
- 两台服务器(高可用性):✅
- 单一配置来源:✅
- 标准配置格式:✅
- 网络:✅
- 储存:✅
- 依赖关系(什么服务与哪些数据库对应):✅
- 易于配置:✅
- 轻松取消配置:✅(也许是 Kubernetes 最强大的部分)
等等,这样初看起来 Kubernetes 非常优雅、非常强大。 没错。你可以在 Kubernetes 中建模一整个微型 IT 世界。

所以,是的,就像开始使用巨型翻斗车(或任何专业设备)时,有一个学习曲线。使用 Kubernetes 还有一个学习曲线,但它值得,因为你可以用一个工具解决这么多问题。如果你对学习曲线感到担忧,请仔细考虑 IT 基础架构中的所有底层网络、存储和安全问题,并设想一下今天的解决方案 —— 这并不容易。特别是当你越来越快地引入越来越多的服务时。速度是当今的目标,因此要特别考虑配置和取消配置问题。
但是,不要混淆了建造或配置 Kubernetes 的学习曲线(为你的翻斗车挑选合适的挡泥板可能很难,LOL)和使用它的学习曲线。学习用如此多的不同层次(容器引擎、日志记录、监控、服务网格、存储、网络)的技术来建立自己的 Kubernetes 有很多不同的选择,还有每六个月维护每个组件的更新选择,这可能不值得投资 —— 但学会使用它绝对是值得的。
我每天都与 Kubernetes 和容器泡在一起,即使这样我都很难跟踪几乎每天都在宣布的所有重大新项目。 但是,每一天我都对使用单一工具来模拟整个 IT 多个方面的运营优势感到兴奋。此外,记住 Kubernetes 已经成熟了很多,并将继续发展下去。与之前的 Linux 和 OpenStack 一样,每一层的接口和事实上的项目都将成熟并变得更容易选择。
在本系列的第三篇文章中,我将深入挖掘你在驾驶 Kubernetes “卡车”之前需要了解的内容。
via: https://opensource.com/article/19/6/kubernetes-learning-curve
作者:Scott McCarty 选题:lujun9972 译者:wxy 校对:wxy