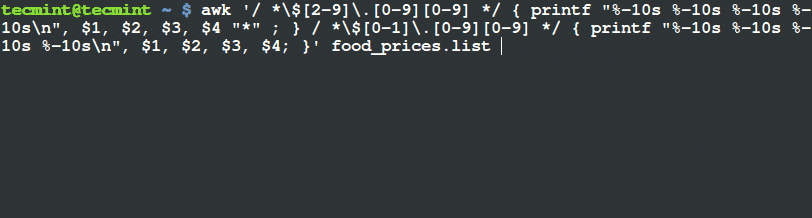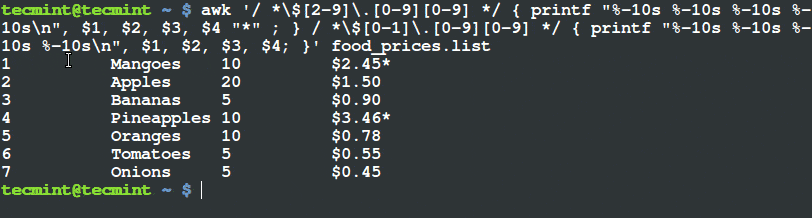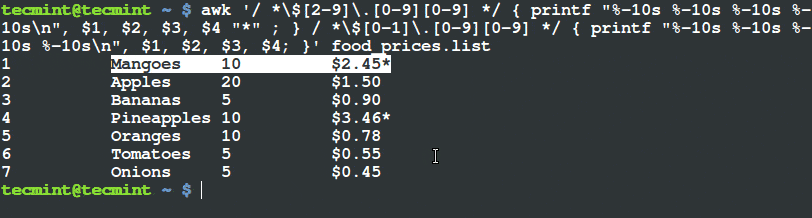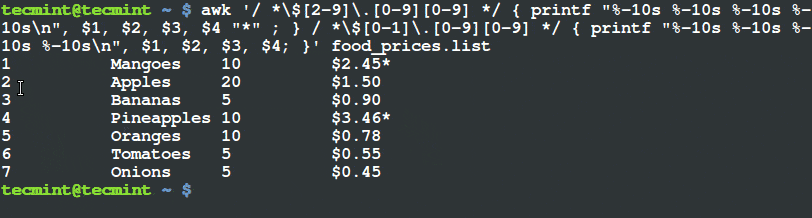
对于想学习 Linux 的初学者来说要适应使用命令行或者终端可能非常困难。由于终端比图形用户界面程序更能帮助用户控制 Linux 系统,我们必须习惯在终端中运行命令。因此为了有效记忆 Linux 不同的命令,你应该每天使用终端并明白怎样将命令和不同选项以及参数一同使用。

在 Linux 中管理文件类型和设置时间
请先查看我们 Linux 小技巧系列之前的文章:
在这篇文章中,我们打算看看终端中 5 个和文件以及时间相关的提示和技巧。
Linux 中的文件类型
在 Linux 中,一切皆文件,你的设备、目录以及普通文件都认为是文件。
Linux 系统中文件有不同的类型:
- 普通文件:可能包含命令、文档、音频文件、视频、图像,归档文件等。
- 设备文件:系统用于访问你硬件组件。
这里有两种表示存储设备的设备文件:块文件,例如硬盘,它们以块读取数据;字符文件,以逐个字符读取数据。
- 硬链接和软链接:用于在 Linux 文件系统的任意地方访问文件。
- 命名管道和套接字:允许不同的进程之间进行交互。
1. 用 ‘file’ 命令确定文件类型
你可以像下面这样使用 file 命令确定文件的类型。下面的截图显示了用 file 命令确定不同文件类型的例子。
tecmint@tecmint ~/Linux-Tricks $ dir
BACKUP master.zip
crossroads-stable.tar.gz num.txt
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3 reggea.xspf
Linux-Security-Optimization-Book.gif tmp-link
tecmint@tecmint ~/Linux-Tricks $ file BACKUP/
BACKUP/: directory
tecmint@tecmint ~/Linux-Tricks $ file master.zip
master.zip: Zip archive data, at least v1.0 to extract
tecmint@tecmint ~/Linux-Tricks $ file crossroads-stable.tar.gz
crossroads-stable.tar.gz: gzip compressed data, from Unix, last modified: Tue Apr 5 15:15:20 2011
tecmint@tecmint ~/Linux-Tricks $ file Linux-Security-Optimization-Book.gif
Linux-Security-Optimization-Book.gif: GIF image data, version 89a, 200 x 259
tecmint@tecmint ~/Linux-Tricks $ file EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3: Audio file with ID3 version 2.3.0, contains: MPEG ADTS, layer III, v1, 192 kbps, 44.1 kHz, JntStereo
tecmint@tecmint ~/Linux-Tricks $ file /dev/sda1
/dev/sda1: block special
tecmint@tecmint ~/Linux-Tricks $ file /dev/tty1
/dev/tty1: character special
2. 用 ‘ls’ 和 ‘dir’ 命令确定文件类型
确定文件类型的另一种方式是用 ls 和 dir 命令显示一长串结果。
用 ls -l 确定一个文件的类型。
当你查看文件权限时,第一个字符显示了文件类型,其它字符显示文件权限。
tecmint@tecmint ~/Linux-Tricks $ ls -l
total 6908
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
使用 ls -l 确定块和字符文件
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/sda1
brw-rw---- 1 root disk 8, 1 Sep 9 10:53 /dev/sda1
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/tty1
crw-rw---- 1 root tty 4, 1 Sep 9 10:54 /dev/tty1
使用 dir -l 确定一个文件的类型。
tecmint@tecmint ~/Linux-Tricks $ dir -l
total 6908
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
3. 统计指定类型文件的数目
下面我们来看看在一个目录中用 ls,grep 和 wc 命令统计指定类型文件数目的技巧。命令之间的交互通过命名管道完成。
- grep – 用户根据给定模式或正则表达式进行搜索的命令。
- wc – 用于统计行、字和字符的命令。
统计普通文件的数目
在 Linux 中,普通文件用符号 - 表示。
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^- | wc -l
7
统计目录的数目
在 Linux 中,目录用符号 d 表示。
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^d | wc -l
1
统计符号链接和硬链接的数目
在 Linux 中,符号链接和硬链接用符号 l 表示。
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^l | wc -l
0
统计块文件和字符文件的数目
在 Linux 中,块和字符文件用符号 b 和 c 表示。
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^b | wc -l
37
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^c | wc -l
159
4. 在 Linux 系统中查找文件
下面我们来看看在 Linux 系统中查找文件一些命令,它们包括 locate、find、whatis 和 which 命令。
用 locate 命令查找文件
在下面的输出中,我想要定位系统中的 Samba 服务器配置文件
tecmint@tecmint ~/Linux-Tricks $ locate samba.conf
/usr/lib/tmpfiles.d/samba.conf
/var/lib/dpkg/info/samba.conffiles
用 find 命令查找文件
想要学习如何在 Linux 中使用 find 命令,你可以阅读我们以下的文章,里面列出了 find 命令的 30 多个例子和使用方法。
用 whatis 命令定位命令
whatis 命令通常用于定位命令,它很特殊,因为它给出关于一个命令的信息,它还能查找配置文件和命令的帮助手册条目。
tecmint@tecmint ~/Linux-Tricks $ whatis bash
bash (1) - GNU Bourne-Again SHell
tecmint@tecmint ~/Linux-Tricks $ whatis find
find (1) - search for files in a directory hierarchy
tecmint@tecmint ~/Linux-Tricks $ whatis ls
ls (1) - list directory contents
用 which 命令定位命令
which 命令用于定位文件系统中的命令。
tecmint@tecmint ~/Linux-Tricks $ which mkdir
/bin/mkdir
tecmint@tecmint ~/Linux-Tricks $ which bash
/bin/bash
tecmint@tecmint ~/Linux-Tricks $ which find
/usr/bin/find
tecmint@tecmint ~/Linux-Tricks $ $ which ls
/bin/ls
5.处理 Linux 系统的时间
在联网环境中,保持你 Linux 系统时间准确是一个好的习惯。Linux 系统中有很多服务要求时间正确才能在联网条件下正常工作。
让我们来看看你可以用来管理你机器时间的命令。在 Linux 中,有两种方式管理时间:系统时间和硬件时间。
系统时间由系统时钟管理,硬件时间由硬件时钟管理。
要查看你的系统时间、日期和时区,像下面这样使用 date 命令。
tecmint@tecmint ~/Linux-Tricks $ date
Wed Sep 9 12:25:40 IST 2015
像下面这样用 date -s 或 date -set=“STRING” 设置系统时间。
tecmint@tecmint ~/Linux-Tricks $ sudo date -s "12:27:00"
Wed Sep 9 12:27:00 IST 2015
tecmint@tecmint ~/Linux-Tricks $ sudo date --set="12:27:00"
Wed Sep 9 12:27:00 IST 2015
你也可以像下面这样设置时间和日期。
tecmint@tecmint ~/Linux-Tricks $ sudo date 090912302015
Wed Sep 9 12:30:00 IST 2015
使用 cal 命令从日历中查看当前日期。
tecmint@tecmint ~/Linux-Tricks $ cal
September 2015
Su Mo Tu We Th Fr Sa
1 2 3 4 5
6 7 8 9 10 11 12
13 14 15 16 17 18 19
20 21 22 23 24 25 26
27 28 29 30
使用 hwclock 命令查看硬件时钟时间。
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
Wednesday 09 September 2015 06:02:58 PM IST -0.200081 seconds
要设置硬件时钟时间,像下面这样使用 hwclock –set –date=“STRING” 命令。
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock --set --date="09/09/2015 12:33:00"
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
Wednesday 09 September 2015 12:33:11 PM IST -0.891163 seconds
系统时间是由硬件时钟时间在启动时设置的,系统关闭时,硬件时间被重置为系统时间。
因此你查看系统时间和硬件时间时,它们是一样的,除非你更改了系统时间。当你的 CMOS 电量不足时,硬件时间可能不正确。
你也可以像下面这样使用硬件时钟的时间设置系统时间。
$ sudo hwclock --hctosys
也可以像下面这样用系统时钟时间设置硬件时钟时间。
$ sudo hwclock --systohc
要查看你的 Linux 系统已经运行了多长时间,可以使用 uptime 命令。
tecmint@tecmint ~/Linux-Tricks $ uptime
12:36:27 up 1:43, 2 users, load average: 1.39, 1.34, 1.45
tecmint@tecmint ~/Linux-Tricks $ uptime -p
up 1 hour, 43 minutes
tecmint@tecmint ~/Linux-Tricks $ uptime -s
2015-09-09 10:52:47
总结
对于初学者来说理解 Linux 中的文件类型是一个好的尝试,同时时间管理也非常重要,尤其是在需要可靠有效地管理服务的服务器上。希望这篇指南能对你有所帮助。如果你有任何反馈,别忘了给我们写评论。和我们保持联系。
via: http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
作者:Aaron Kili 译者:ictlyh 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出