如何用 Python 编写你喜爱的 R 函数
R 还是 Python ? Python 脚本模仿易使用的 R 风格函数,使得数据统计变得简单易行。

“Python vs. R” 是数据科学和机器学习的现代战争之一。毫无疑问,近年来这两者发展迅猛,成为数据科学、预测分析和机器学习领域的顶级编程语言。事实上,根据 IEEE 最近的一篇文章,Python 已在 最受欢迎编程语言排行榜 中超越 C++ 成为排名第一的语言,并且 R 语言也稳居前 10 位。
但是,这两者之间存在一些根本区别。R 语言设计的初衷主要是作为统计分析和数据分析问题的快速原型设计的工具,另一方面,Python 是作为一种通用的、现代的面向对象语言而开发的,类似 C++ 或 Java,但具有更简单的学习曲线和更灵活的语言风格。因此,R 仍在统计学家、定量生物学家、物理学家和经济学家中备受青睐,而 Python 已逐渐成为日常脚本、自动化、后端 Web 开发、分析和通用机器学习框架的顶级语言,拥有广泛的支持基础和开源开发社区。
在 Python 环境中模仿函数式编程
R 作为函数式编程语言的本质为用户提供了一个极其简洁的用于快速计算概率的接口,还为数据分析问题提供了必不可少的描述统计和推论统计方法(LCTT 译注:统计学从功能上分为描述统计学和推论统计学)。例如,只用一个简洁的函数调用来解决以下问题难道不是很好吗?
- 如何计算数据向量的平均数 / 中位数 / 众数。
- 如何计算某些服从正态分布的事件的累积概率。如果服 从泊松分布 又该怎样计算呢?
- 如何计算一系列数据点的四分位距。
- 如何生成服从学生 t 分布的一些随机数(LCTT 译注: 在概率论和统计学中,学生 t-分布(Student’s t-distribution)可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值)。
R 编程环境可以完成所有这些工作。
另一方面,Python 的脚本编写能力使分析师能够在各种分析流程中使用这些统计数据,具有无限的复杂性和创造力。
要结合二者的优势,你只需要一个简单的 Python 封装的库,其中包含与 R 风格定义的概率分布和描述性统计相关的最常用函数。 这使你可以非常快速地调用这些函数,而无需转到正确的 Python 统计库并理解整个方法和参数列表。
便于调用 R 函数的 Python 包装脚本
我编写了一个 Python 脚本 ,用 Python 简单统计分析定义了最简洁和最常用的 R 函数。导入此脚本后,你将能够原生地使用这些 R 函数,就像在 R 编程环境中一样。
此脚本的目标是提供简单的 Python 函数,模仿 R 风格的统计函数,以快速计算密度估计和点估计、累积分布和分位数,并生成重要概率分布的随机变量。
为了延续 R 风格,脚本不使用类结构,并且只在文件中定义原始函数。因此,用户可以导入这个 Python 脚本,并在需要单个名称调用时使用所有功能。
请注意,我使用 mimic 这个词。 在任何情况下,我都声称要模仿 R 的真正的函数式编程范式,该范式包括深层环境设置以及这些环境和对象之间的复杂关系。 这个脚本允许我(我希望无数其他的 Python 用户)快速启动 Python 程序或 Jupyter 笔记本程序、导入脚本,并立即开始进行简单的描述性统计。这就是目标,仅此而已。
如果你已经写过 R 代码(可能在研究生院)并且刚刚开始学习并使用 Python 进行数据分析,那么你将很高兴看到并在 Jupyter 笔记本中以类似在 R 环境中一样使用一些相同的知名函数。
无论出于何种原因,使用这个脚本很有趣。
简单的例子
首先,只需导入脚本并开始处理数字列表,就好像它们是 R 中的数据向量一样。
from R_functions import *
lst=[20,12,16,32,27,65,44,45,22,18]
<more code, more statistics...>假设你想从数据向量计算 Tuckey 五数摘要。 你只需要调用一个简单的函数 fivenum,然后将向量传进去。 它将返回五数摘要,存在 NumPy 数组中。
lst=[20,12,16,32,27,65,44,45,22,18]
fivenum(lst)
> array([12. , 18.5, 24.5, 41. , 65. ])或许你想要知道下面问题的答案:
假设一台机器平均每小时输出 10 件成品,标准偏差为 2。输出模式遵循接近正态的分布。 机器在下一个小时内输出至少 7 个但不超过 12 个单位的概率是多少?
答案基本上是这样的:
使用 pnorm ,你可以只用一行代码就能获得答案:
pnorm(12,10,2)-pnorm(7,10,2)
> 0.7745375447996848或者你可能需要回答以下问题:
假设你有一个不公平硬币,每次投它时有 60% 可能正面朝上。 你正在玩 10 次投掷游戏。 你如何绘制并给出这枚硬币所有可能的胜利数(从 0 到 10)的概率?
只需使用一个函数 dbinom 就可以获得一个只有几行代码的美观条形图:
probs=[]
import matplotlib.pyplot as plt
for i in range(11):
probs.append(dbinom(i,10,0.6))
plt.bar(range(11),height=probs)
plt.grid(True)
plt.show()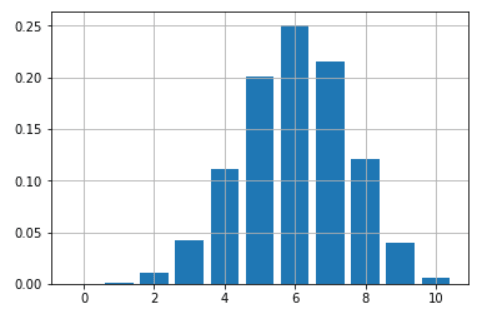
简单的概率计算接口
R 提供了一个非常简单直观的接口,可以从基本概率分布中快速计算。 接口如下:
- d 分布:给出点 x 处的密度函数值
- p 分布:给出 x 点的累积值
- q 分布:以概率 p 给出分位数函数值
- r 分布:生成一个或多个随机变量
在我们的实现中,我们坚持使用此接口及其关联的参数列表,以便你可以像在 R 环境中一样执行这些函数。
目前已实现的函数
脚本中实现了以下 R 风格函数,以便快速调用。
- 平均数、中位数、方差、标准差
- Tuckey 五数摘要、 四分位距 (IQR)
- 矩阵的协方差或两个向量之间的协方差
- 以下分布的密度、累积概率、分位数函数和随机变量生成:正态、均匀、二项式、 泊松 、F、 学生 t 、 卡方 、 贝塔 和 伽玛
进行中的工作
显然,这是一项正在进行的工作,我计划在此脚本中添加一些其他方便的R函数。 例如,在 R 中,单行命令 lm 可以为数字数据集提供一个简单的最小二乘拟合模型,其中包含所有必要的推理统计(P 值,标准误差等)。 这非常简洁! 另一方面,Python 中的标准线性回归问题经常使用 Scikit-learn 库来处理,此用途需要更多的脚本,所以我打算使用 Python 的 statsmodels 库合并这个单函数线性模型来拟合功能。
如果你喜欢这个脚本,并且愿意在工作中使用,请 GitHub 仓库点个 star 或者 fork 帮助其他人找到它。 另外,你可以查看我其他的 GitHub 仓库,了解 Python、R 或 MATLAB 中的有趣代码片段以及一些机器学习资源。
如果你有任何问题或想法要分享,请通过 [tirthajyoti [AT] gmail.com](mailto:[email protected]) 与我联系。 如果你像我一样热衷于机器学习和数据科学,请 在 LinkedIn 上加我为好友或者在 Twitter 上关注我。
本篇文章最初发表于走向数据科学。 请在 CC BY-SA 4.0 协议下转载。
via: https://opensource.com/article/18/10/write-favorite-r-functions-python
作者:Tirthajyoti Sarkar 选题:lujun9972 译者:yongshouzhang 校对:Flowsnow