JSON 的兴起与崛起

JSON 已经占领了全世界。当今,任何两个应用程序彼此通过互联网通信时,可以打赌它们在使用 JSON。它已被所有大型企业所采用:十大最受欢迎的 web API 接口列表中(主要由 Google、Facebook 和 Twitter 提供),仅仅只有一个 API 接口是以 XML 的格式开放数据的。 1 这个列表中的 Twitter API 为此做了一个鲜活的注脚:其对 XML 格式的支持到 2013 年结束,其时发布的新版本的 API 取消 XML 格式,转而仅使用 JSON。JSON 也在程序编码级别和文件存储上被广泛采用:在 Stack Overflow(LCTT 译注:一个面向程序员的问答网站)上,现在更多的是关于 JSON 的问题,而不是其他的数据交换格式。 2
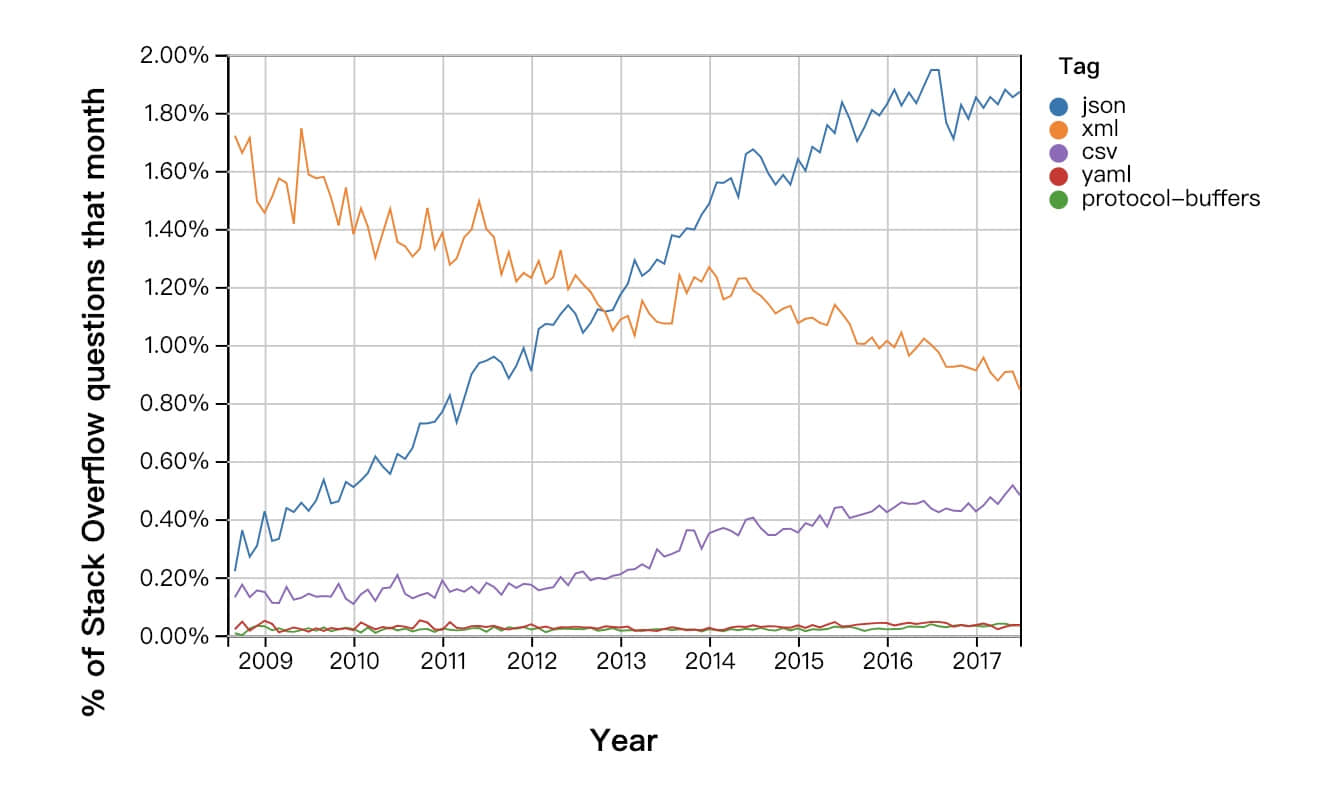
XML 仍然在很多地方存在。网络上它被用于 SVG 和 RSS / Atom 信息流。Android 开发者想要获得用户权限许可时,需要在其 APP 的 manifest 文件中声明 —— 此文件是 XML 格式的。XML 的替代品也不仅仅只有 JSON,现在有很多人在使用 YAML 或 Google 的 Protocol Buffers 等技术,但这些技术的受欢迎程度远不如 JSON。目前来看,JSON 是应用程序在网络之间通信的首选协议格式。
考虑到自 2005 年来 Web 编程世界就垂涎于 “异步 JavaScript 和 XML” 而非 “异步 JavaScript 和 JSON” 的技术潜力,你可以发现 JSON 的主导地位是如此的让人惊讶。当然了,这可能与这两种通信格式的受欢迎程度无关,而仅反映出缩写 “AJAX” 似乎比 “AJAJ” 更具吸引力。但是,即使在 2005 年有些人(实际上没有太多人)已经用 JSON 来取代 XML 了,我们不禁要问 XML 的噩运来的如此之快,以至于短短十来年,“异步 JavaScript 和 XML” 这个名称就成为一个很讽刺的误称。那这十来年发生了什么?JSON 怎么会在那么多应用程序中取代了 XML?现在被全世界工程师和系统所使用、依赖的这种数据格式是谁提出的?
JSON 之诞生
2001 年 4 月,首个 JSON 格式的消息被发送出来。此消息是从旧金山湾区某车库的一台计算机发出的,这是计算机历史上重要的的时刻。Douglas Crockford 和 Chip Morningstar 是一家名为 State Software 的技术咨询公司的联合创始人,他们当时聚集在 Morningstar 的车库里测试某个想法,发出了此消息。
在 “AJAX” 这个术语被创造之前,Crockford 和 Morningstar 就已经在尝试构建好用的 AJAX 应用程序了,可是浏览器对其兼容性不好。他们想要在初始页面加载后就将数据传递给应用程序,但其目标要针对所有的浏览器,这就实现不了。
这在今天看来不太可信,但是要记得 2001 年的时候 Internet Explorer(IE)代表了网页浏览器的最前沿技术产品。早在 1999 年的时候,Internet Explorer 5 就支持了原始形式的 XMLHttpRequest,开发者可以使用名为 ActiveX 的框架来访问此对象。Crockford 和 Morningstar 能够使用此技术(在 IE 中)来获取数据,但是在 Netscape 4 中(这是他们想要支持的另一种浏览器)就无法使用这种解决方案。为此 Crockford 和 Morningstar 只得使用一套不同的系统以兼容不同的浏览器。
第一条 JSON 消息如下所示:
<html><head><script>
document.domain = 'fudco';
parent.session.receive(
{ to: "session", do: "test",
text: "Hello world" }
)
</script></head></html>消息中只有一小部分类似于今天我们所知的 JSON,本身其实是一个包含有一些 JavaScript 的 HTML 文档。类似于 JSON 的部分只是传递给名为 receive() 的函数的 JavaScript 对象字面量。
Crockford 和 Morningstar 决定滥用 HTML 的帧(<frame>)以发送数据。他们可以让一个帧指向一个返回的上述 HTML 文档的 URL。当接收到 HTML 时,JavaScript 代码段就会运行,就可以把数据对象字面量如实地传递回应用程序。只要小心的回避浏览器保护策略(即子窗口不允许访问父窗口),这种技术就可以正常运行无误。可以看到 Crockford 和 Mornginstar 通过明确地设置文档域这种方法来达到其目的。(这种基于帧的技术,有时称为隐藏帧技术,通常在 90 年代后期,即在广泛使用 XMLHttpRequest 技术之前使用。 3 )
第一个 JSON 消息的惊人之处在于,它显然不是一种新的数据格式的首次使用。它就是 JavaScript!实际上,以此方式使用 JavaScript 的想法如此简单,Crockford 自己也说过他不是第一个这样做的人。他说 Netscape 公司的某人早在 1996 年就使用 JavaScript 数组字面量来交换信息。 4 因为消息就是 JavaScript,其不需要任何特殊解析工作,JavaScript 解释器就可搞定一切。
最初的 JSON 信息实际上与 JavaScript 解释器发生了冲突。JavaScript 保留了大量的关键字(ECMAScript 6 版本就有 64 个保留字),Crockford 和 Morningstar 无意中在其 JSON 中使用了一个保留字。他们使用了 do 作为了键名,但 do 是解释器中的保留字。因为 JavaScript 使用的保留字太多了,Crockford 做了决定:既然不可避免的要使用到这些保留字,那就要求所有的 JSON 键名都加上引号。被引起来的键名会被 JavaScript 解释器识别成字符串,其意味着那些保留字也可以放心安全的使用。这就为什么今天 JSON 键名都要用引号引起来的原因。
Crockford 和 Morningstar 意识到这技术可以应用于各类应用系统。想给其命名为 “JSML”,即 JavaScript 标记语言 的意思,但发现这个缩写已经被一个名为 Java Speech 标记语言的东西所使用了。因此他们决定采用 “JavaScript Object Notation”,缩写为 JSON。他们开始向客户推销,但很快发现客户不愿意冒险使用缺乏官方规范的未知技术。所以 Crockford 决定写一个规范。
2002 年,Crockford 买下了 JSON.org 域名,放上了 JSON 语法及一个解释器的实例例子。该网站仍然在运行,现在已经包含有 2013 年正式批准的 JSON ECMA 标准的显著链接。在该网站建立后,Crockford 并没有过多的推广,但很快发现很多人都在提交各种不同编程语言的 JSON 解析器实现。JSON 的血统显然与 JavaScript 相关联,但很明显 JSON 非常适合于不同语言之间的数据交换。
AJAX 导致的误会
2005 年,JSON 有了一次大爆发。那一年,一位名叫 Jesse James Garrett 的网页设计师和开发者在博客文章中创造了 “AJAX” 一词。他很谨慎地强调:AJAX 并不是新技术,而是 “好几种蓬勃发展的技术以某种强大的新方式汇集在一起。 5 ” AJAX 是 Garrett 给这种正受到青睐的 Web 应用程序的新开发方法的命名。他的博客文章接着描述了开发人员如何利用 JavaScript 和 XMLHttpRequest 构建新型应用程序,这些应用程序比传统的网页更具响应性和状态性。他还以 Gmail 和 Flickr 网站已经使用 AJAX 技术作为了例子。
当然了,“AJAX” 中的 “X” 代表 XML。但在随后的问答帖子中,Garrett 指出,JSON 可以完全替代 XML。他写道:“虽然 XML 是 AJAX 客户端进行数据输入、输出的最完善的技术,但要实现同样的效果,也可以使用像 JavaScript Object Notation(JSON)或任何类似的结构数据方法等技术。 ” 6
开发者确实发现在构建 AJAX 应用程序时可以很容易的使用 JSON,许多人更喜欢它而不是 XML。具有讽刺意味的是,对 AJAX 的兴趣逐渐的导致了 JSON 的普及。大约在这个时候,JSON 引起了博客圈的注意。
2006 年,Dave Winer,一位高产的博主,他也是许多基于 XML 的技术(如 RSS 和 XML-RPC)背后的开发工程师,他抱怨到 JSON 毫无疑问的正在重新发明 XML。尽管人们认为数据交换格式之间的竞争不会导致某一技术的消亡。其写到:
毫无疑问,我可以编写一个例程来解析 JSON,但来看看他们要重新发明一个东西有多大的意义,出于某种原因 XML 本身对他们来说还不够好(我很想听听原因)。谁想干这荒谬之事?查找一棵树然后把节点串起来。可以立马试试。 7
我很理解 Winer 的挫败感。事实上并没有太多人喜欢 XML。甚至 Winer 也说过他不喜欢 XML。 8 但 XML 已被设计成一个可供任何人使用,并且可以用于几乎能想象到的所有事情。归根到底,XML 实际上是一门元语言,允许你为特定应用程序自定义该领域特定的语言。如 Web 信息流技术 RSS 和 SOAP(简单对象访问协议)就是例子。Winer 认为由于通用交换格式所带来的好处,努力达成共识非常重要。XML 的灵活性应该能满足任何人的需求,然而 JSON 格式呢,其并没有比 XML 提供更多东西,除了它抛弃了使 XML 更灵活的那些繁琐的东西。
Crockford 阅读了 Winer 的这篇文章并留下了评论。为了回应 JSON 重新发明 XML 的指责,Crockford 写到:“重造轮子的好处是可以得到一个更好的轮子。” 9
JSON 与 XML 对比
到 2014 年,JSON 已经由 ECMA 标准和 RFC 官方正式认可。它有了自己的 MIME 类型。JSON 已经进入了大联盟时代。
为什么 JSON 比 XML 更受欢迎?
在 JSON.org 网站上,Crockford 总结了一些 JSON 的优势。他写到,JSON 的语法极少,其结构可预测,因此 JSON 更容易被人类和机器理解。 10 其他博主一直关注 XML 的冗长啰嗦及“尖括号负担”。 11 XML 中每个开始标记都必须与结束标记匹配,这意味着 XML 文档包含大量的冗余信息。在未压缩时,XML 文档的体积比同等信息量 JSON 文档的体积大很多,但是,更重要的,这也使 XML 文档更难以阅读。
Crockford 还声称 JSON 的另一个巨大优势是其被设计为数据交换格式。 12 从一开始,它的目的就是在应用程序间传递结构化信息的。而 XML 呢,虽然也可以使用来传递数据,但其最初被设计为文档标记语言。它演变自 SGML(通用标准标记语言),而它又是从被称为 Scribe 的标记语言演变而来,其旨在发展成类似于 LaTeX 一样的文字处理系统。XML 中,一个标签可以包含有所谓的“混合内容”,即带有围绕单词、短语的内嵌标签的文本。这会让人浮现出一副用红蓝笔记录的手稿画面,这是标记语言核心思想的形象比喻。另一方面,JSON 不支持对混合内容模型的清晰构建,但这也意味着它的结构足够简单。一份文档最好的建模就是一棵树,但 JSON 抛弃了这种文档的思想,Crockford 将 JSON 抽象限制为字典和数组,这是所有程序员构建程序时都会使用的最基本的、也最熟悉的元素。
最后,我认为人们不喜欢 XML 是因为它让人困惑。它让人迷惑的地方就是有很多不同的风格。乍一看,XML 本身及其子语言(如 RSS、ATOM、SOAP 或 SVG)之间的界限并不明显。典型的 XML 文档的第一行标识了该 XML 的版本,然后该 XML 文档应该符合特定的子语言。这就有变化需要考虑了,特别是跟 JSON 做比较,JSON 是如此简单,以至于永远不需要编写新版本的 JSON 规范。XML 的设计者试图将 XML 做为唯一的数据交换格式以支配所有格式,就会掉入那个经典的程序员陷阱:过度工程化。XML 非常笼统及概念化,所以很难于简单的使用。
在 2000 年的时候,发起了一场使 HTML 符合 XML 标准的活动,发布了一份符合 XML 标准的 HTML 开发规范,这就此后很出名的 XHTML。虽然一些浏览器厂商立即开始支持这个新标准,但也很明显,大部分基于 HTML 技术的开发者不愿意改变他们的习惯。新标准要求对 XHTML 文档进行严格的验证,而不是基于 HTML 的基准。但大多的网站都是依赖于 HTML 的宽容规则的。到 2009 年的时候,试图编写第二版本的 XHTML 标准的努力已经流产,因为未来已清晰可见,HTML 将会发展为 HTML5(一种不强制要求接受 XML 规则的标准)。
如果 XHTML 的努力取得了成功,那么 XML 可能会成为其设计者所希望的通用数据格式。想象一下,一个 HTML 文档和 API 响应具有完全相同结构的世界。在这样的世界中,JSON 可能不会像现在一样普遍存在。但我把 HTML 的失败看做是 XML 阵营的一种道义上的失败。如果 XML 不是 HTML 的最佳工具,那么对于其他应用程序,也许会有更好的工具出现。在这个世界,我们的世界,很容易看到像 JSON 格式这样的足够简单、量体裁衣的才能获得更大的成功。
如果你喜欢这博文,每两周会更新一次! 请在 Twitter 上关注 @TwoBitHistory 或订阅 RSS feed,以确保得到更新的通知。
- http://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#software ↩
- https://insights.stackoverflow.com/trends?tags=json%2Cxml%2Cprotocol-buffers%2Cyaml%2Ccsv ↩
- Zakas, Nicholas C., et al. “What Is Ajax?” Professional Ajax, 2nd ed., Wiley, 2007. ↩
- https://youtu.be/-C-JoyNuQJs?t=32s ↩
- http://adaptivepath.org/ideas/ajax-new-approach-web-applications/ ↩
- 同上 ↩
- http://scripting.com/2006/12/20.html ↩
- http://blogoscoped.com/archive/2009-03-05-n15.html ↩
- https://scripting.wordpress.com/2006/12/20/scripting-news-for-12202006/#comment-26383 ↩
- http://www.json.org/xml.html ↩
- https://blog.codinghorror.com/xml-the-angle-bracket-tax ↩
- https://youtu.be/-C-JoyNuQJs?t=33m50sgg ↩
via: https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html
作者:Two-Bit History 选题:lujun9972 译者:runningwater 校对:wxy











{kind=link}
{kind=link}