手册页 ,即 参考手册页 的简称,是你进入 Linux 的钥匙。你想知道的一切都在那里,包罗万象。这套文档永远不会赢得普利策奖,但这套文档是相当准确和完整的。手册页是主要信源,其权威性是众所周知的。
虽然它们是源头,但阅读起来并不是最令人愉快的。有一次,在很久以前的哲学课上,有人告诉我,阅读 亚里士多德 是最无聊的阅读。我不同意:说到枯燥的阅读,亚里士多德远远地排在第二位,仅次于手册页。
乍一看,这些页面可能看起来并不完整,但是,不管你信不信,手册页并不是为了隐藏信息 —— 只是因为信息量太大,这些页面必须要有结构,而且信息是以尽可能简短的形式给出的。这些解释相当简略,需要一些时间来适应,但一旦你掌握了使用它们的技巧,你就会发现它们实际上是多么有用。
Linux 中的手册页入门
这些页面是通过一个叫做 man 的工具查看的,使用它的命令相当简单。在最简单的情况下,要使用 man,你要在命令行上输入 man,后面加一个空格和你想查询的命令,比如 ls 或 cp,像这样:
man ls
man 会打开 ls 命令的手册页。
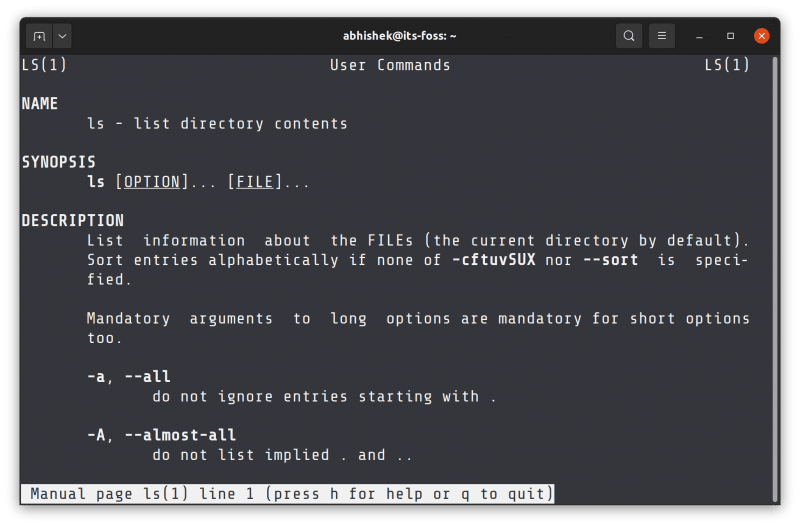
你可以用方向键上下移动,按 q 退出查看手册页。通常情况下,手册页是用 less 打开的,所以 less 命令的键盘快捷键在 man 中也可以使用。
例如,你可以用 /search_term 来搜索一个特定的文本,等等。
有一个关于手册页的介绍,这是一篇值得阅读介绍。它非常详细地说明了手册页是如何布局和组织的。
要看这个页面,请打开一个终端,然后输入:
man man

节
在你开始更深入地研究手册页之前,知道手册页有一个固定的页面布局和一个归档方案会有帮助。这可能会让新手感到困惑,因为我可以说:“看手册页中关于 ls 的 NAME 节 ”,我也可以说:“看第 5 节 中的 passwd 的手册页。”
我把 “ 节 ” 这个词用斜体字表示,是为了显示混淆的来源。这个词,“节” 被用于两种不同的方式,但并不总是向新人解释其中的区别。
我不确定为什么会出现这种混淆,但我在培训新用户和初级系统管理员时看到过几次这种混淆。我认为这可能是隧道视野,专注于一件事会使一个人忘记另一件事。一叶障目,不见泰山。
对于那些已经知道其中的区别的人,你可以跳过这一小节。这一部分是针对那些刚接触到手册页的人。
这就是区别:
对于手册页
单独的手册页是用来显示信息块的。例如,每个手册页都有一个“NAME”节,显示命令的名称和简短的描述。还会有另一个信息块,称为“SYNOPSIS”,显示该命令是如何使用的,以此类推。
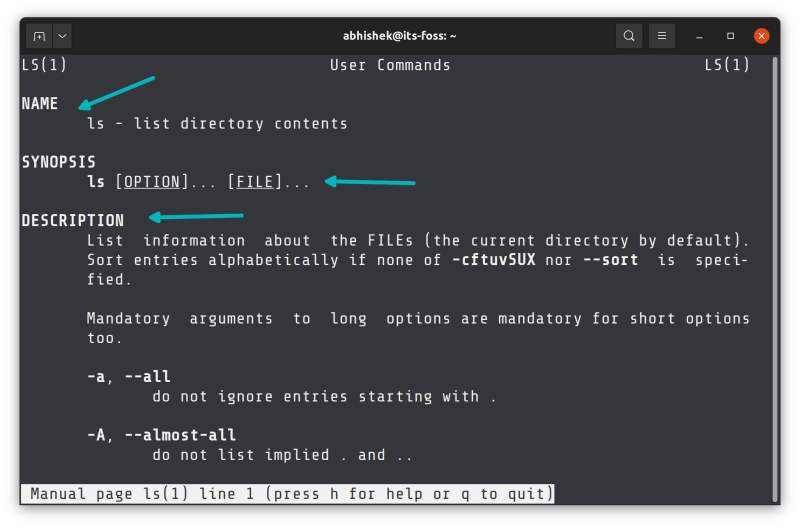
每个手册页都会有这些,以及其他的标题。这些在各个手册页上的节,或者说标题,有助于保持事情的一致性和信息的分工。
对于手册
使用“节”,如 “查看第 5 节中的 passwd 的手册页”,是指整个手册的内容。当我们只看一页时,很容易忽略这一点,但是 passwd 手册页是同一本手册的一部分,该手册还有 ls、rm、date、cal 等的手册页。
整个 Linux 手册是巨大的;它有成千上万的手册页。其中一些手册页有专门的信息。有些手册页有程序员需要的信息,有些手册页有网络方面的独特信息,还有一些是系统管理员会感兴趣的。
这些手册页根据其独特的目的被分组。想想看,把整个手册分成几个章节 —— 每章有一个特定的主题。有 9 个左右的章节(非常大的章节)。碰巧的是,这些章节被称为“节”。
总结一下:
- 手册中单页(我们称之为“手册页”)的节是由标题定义的信息块。
- 这个大的手册(所有页面的集合)中的章节,刚好被称为“节”。
现在你知道区别了,希望本文的其余部分会更容易理解。
手册页的节
你将会看到不同的手册页,所以让我们先研究一下各个页面的布局。
手册页被分成几个标题,它们可能因提供者不同而不同,但会有相似之处。一般的分类如下:
NAME(名称)SYNOPSIS(概要)DESCRIPTION(描述)EXAMPLES(例子)DIAGNOSTICS(诊断)FILES(文件)LIMITS(限制)PORTABILITY(可移植性)SEE ALSO(另见)HISTORY(历史)- WARNING
(警告)或BUGS`(错误) NOTES(注意事项)
NAME - 在这个标题下是命令的名称和命令的简要描述。
SYNOPSIS - 显示该命令的使用方法。例如,这里是 cal 命令的概要:
cal [Month] [Year]
概要以命令的名称开始,后面是选项列表。概要采用命令行的一般形式;它显示了你可以输入的内容和参数的顺序。方括号中的参数([])是可选的;你可以不输入这些参数,命令仍然可以正常工作。不在括号内的项目必须使用。
请注意,方括号只是为了便于阅读。当你输入命令时,不应该输入它们。
DESCRIPTION - 描述该命令或工具的作用以及如何使用它。这一节通常以对概要的解释开始,并说明如果你省略任何一个可选参数会发生什么。对于长的或复杂的命令,这一节可能会被细分。
EXAMPLES - 一些手册页提供了如何使用命令或工具的例子。如果有这一节,手册页会尝试给出一些简单的使用例子,以及更复杂的例子来说明如何完成复杂的任务。
DIAGNOSTICS - 本节列出了由命令或工具返回的状态或错误信息。通常不显示不言自明的错误和状态信息。通常会列出可能难以理解的信息。
FILES - 本节包含了 UNIX 用来运行这个特定命令的补充文件的列表。这里,“补充文件”是指没有在命令行中指定的文件。例如,如果你在看 passwd 命令的手册,你可能会发现 /etc/passwd 列在这一节中,因为 UNIX 是在这里存储密码信息。
LIMITS - 本节描述了一个工具的限制。操作系统和硬件的限制通常不会被列出,因为它们不在工具的控制范围内。
PORTABILITY - 列出其他可以使用该工具的系统,以及该工具的其他版本可能有什么不同。
SEE ALSO - 列出包含相关信息的相关手册页。
HISTORY - 提供命令的简要历史,如它第一次出现的时间。
WARNING - 如果有这个部分,它包含了对用户的重要建议。
NOTES - 不像警告那样严重,但也是重要的信息。
同样,并不是所有的手册都使用上面列出的确切标题,但它们足够接近,可以遵循。
手册的节
整个 Linux 手册集合的手册页传统上被划分为有编号的节:
第 1 节:Shell 命令和应用程序 第 2 节:基本内核服务 - 系统调用和错误代码 第 3 节:为程序员提供的库信息 第 4 节:网络服务 - 如果安装了 TCP/IP 或 NFS 设备驱动和网络协议 第 5 节:文件格式 - 例如:显示 tar 存档的样子 第 6 节:游戏 第 7 节:杂项文件和文档 第 8 节:系统管理和维护命令 第 9 节:不知名的内核规格和接口
将手册页分成这些组,可以使搜索更有效率。在我工作的地方,我有时会做一些编程工作,所以我花了一点时间看第 3 节的手册页。我也做一些网络方面的工作,所以我也知道要涉足网络部分。作为几个实验性机器的系统管理员,我在第 8 节花了很多时间。
将手册网归入特定的节(章节),使搜索信息更加容易 —— 无论是对需要搜索的人,还是对进行搜索的机器。
你可以通过名称旁边的数字来判断哪个手册页属于哪个部分。例如,如果你正在看 ls 的手册页,而页面的最上面写着。 LS(1),那么你正在浏览第 1 节中的 ls 页面,该节包含关于 shell 命令和应用程序的页面。
下面是另一个例子。如果你在看 passwd 的手册页,页面的顶部显示: PASSWD(1),说明你正在阅读第 1 节中描述 passwd 命令如何更改用户账户密码的手册页。如果你看到 PASSWD(5),那么你正在阅读关于密码文件和它是如何组成的的手册页。
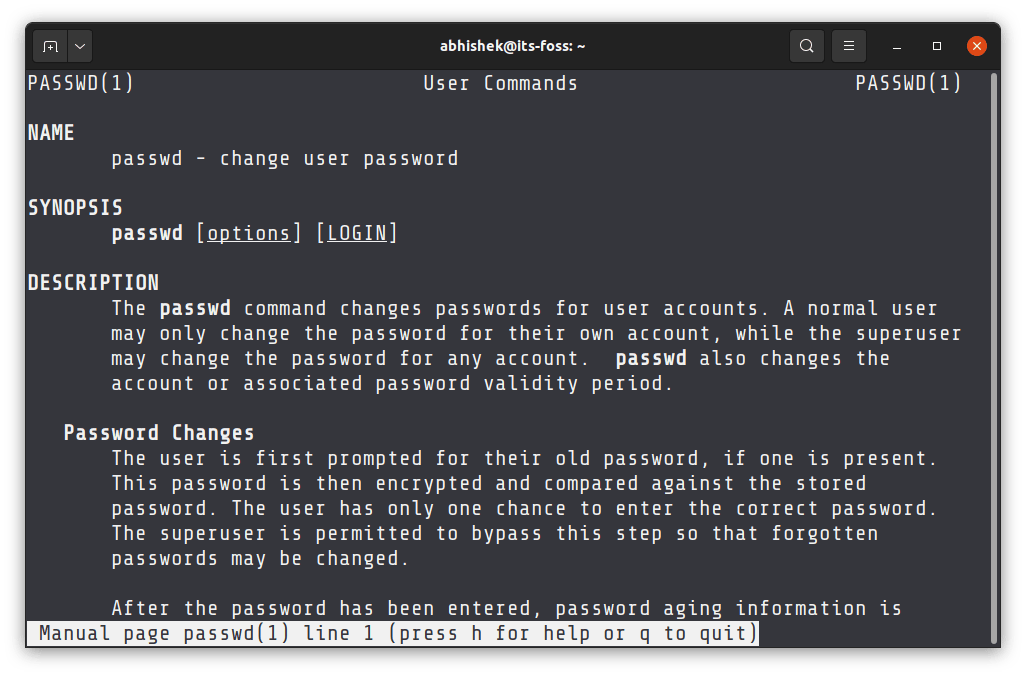
passwd 恰好是两个不同的东西:一个是命令的名称,一个是文件的名称。同样,第 1 节描述了命令,而第 5 节涉及文件格式。
括号中的数字是重要的线索 —— 这个数字告诉你正在阅读的页面来自哪一节。
搜索一个特定的节
基本命令:
man -a name
将在每一节中搜索由 name 标识的手册页,按数字顺序逐一显示。要把搜索限制在一个特定的部分,请在 man 命令中使用一个参数,像这样:
man 1 name
这个命令将只在手册页的第 1 节中搜索 name。使用我们前面的 passwd 例子,这意味着我们可以保持搜索的针对性。如果我想阅读 passwd 命令的手册页,我可以在终端输入以下内容:
man 1 passwd
man 工具将只在第 1 节中搜索 passwd 并显示它。它不会在任何其他节中寻找 passwd。
这个命令的另一种方法是输入: man passwd.1。
使用 man -k 来搜索包含某个关键词的所有手册页
如果你想获得包含某个关键词的手册页的列表,man 命令中的 -k 选项(通常称为标志或开关)可以派上用场。例如,如果你想看一个关于 ftp 的手册列表,你可以通过输入以下内容得到这个列表:
man -k ftp
在接下来的列表中,你可以选择一个特定的手册页来阅读:

在某些系统上,在 man -k 工作之前,系统管理员需要运行一个叫做 catman 的工具。
使用 whatis 和 whereis 命令来了解手册的各个节
有两个有趣的工具可以帮助你搜索信息:whatis和 whereis。
whatis
有的时候,我们完全可以得到我们需要的信息。我们需要的信息有很大的机会是可以找到的 —— 找到它可能是一个小问题。
例如,如果我想看关于 passwd 文件的手册页,我在终端上输入:
man passwd
我就会看到关于 passwd 命令所有信息的手册页,但没有关于 passwd 文件的内容。我知道 passwd 是一个命令,也有一个 passwd 文件,但有时,我可能会忘记这一点。这时我才意识到,文件结构在手册页中的不同节,所以我输入了:
man 4 passwd
我得到这样的答复:
No manual entry for passwd in section 4
See 'man 7 undocumented' for help when manual pages are not available.
又是一次健忘的失误。文件结构在 System V UNIX 页面的第 4 节中。几年前,当我建立文件时,我经常使用 man 4 ...;这仍然是我的一个习惯。那么它在 Linux 手册中的什么地方呢?
现在是时候调用 whatis 来纠正我了。为了做到这一点,我在我的终端中输入以下内容:
whatis passwd
然后我看到以下内容:
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password file
啊!passwd 文件的页面在第 5 节。现在没问题了,可以访问我想要的信息了:
man 5 passwd
然后我被带到了有我需要的信息的手册页。
whatis 是一个方便的工具,可以用简短的一句话告诉你一个命令的作用。想象一下,你想知道 cal 是做什么的,而不想查看手册页。只要在命令提示符下键入以下内容。
whatis cal
你会看到这样的回应:
cal (1) - displays a calendar and the date of Easter
现在你知道了 whatis 命令,我可以告诉你一个秘密 —— 有一个 man 命令的等价物。为了得到这个,我们使用 -f 开关:man -f ...。
试试吧。在终端提示下输入 whatis cal。执行后就输入:man -f cal。两个命令的输出将是相同的:

whereis
whereis 命令的名字就说明了这一点 —— 它告诉你一个程序在文件系统中的位置。它也会告诉你手册页的存放位置。再以 cal 为例,我在提示符下输入以下内容:
whereis cal
我将看到这个:

仔细看一下这个回答。答案只在一行里,但它告诉我两件事:
/usr/bin/cal 是 cal 程序所在的地方,以及/usr/share/man/man1/cal.1.gz 是手册页所在的地方(我也知道手册页是被压缩的,但不用担心 —— man 命令知道如何即时解压)。
whereis 依赖于 PATH 环境变量;它只能告诉你文件在哪里,如果它们在你的 PATH 环境变量中。
你可能想知道是否有一个与 whereis 相当的 man 命令。没有一个命令可以告诉你可执行文件的位置,但有一个开关可以告诉你手册页的位置。在这个例子中使用 date 命令,如果我们输入:
whereis date
在终端提示符下,我们会看到:

我们看到 date 程序在 /usr/bin/ 目录下,其手册页的名称和位置是:/usr/share/man/man1/date.1.gz。
我们可以让 man 像 whereis 一样行事,最接近的方法是使用 -w 开关。我们不会得到程序的位置,但我们至少可以得到手册页的位置,像这样:
man -w date
我们将看到这样的返回:

你知道了 whatis 和 whereis,以及让 man 命令做同样(或接近)事情的方法。我展示了这两种方法,有几个不同的原因。
多年来,我使用 whatis 和 whereis,因为它们在我的培训手册中。直到最近我才了解到 man -f ... 和 man -w ...。我确信我看了几百次 man 的手册页,但我从未注意到 -f 和 -w 开关。我总是在看手册页的其他东西(例如:man -k ...)。我只专注于我需要找到的东西,而忽略了其他的东西。一旦我找到了我需要的信息,我就会离开这个页面,去完成工作,而不去注意这个命令所提供的其他一些宝贝。
这没关系,因为这部分就是手册页的作用:帮助你完成工作。
直到最近我向别人展示如何使用手册页时,我才花时间去阅读 —— “看看还有什么可能” —— 我们才真正注意到关于 man 命令的 -f 和 -w 标记可以做什么的信息。
不管你使用 Linux 多久了,或者多么有经验,总有一些新东西需要学习。
手册页会告诉你在完成某项任务时可能需要知道的东西 —— 但它们也有很多内容 —— 足以让你看起来像个魔术师,但前提是你要花时间去读。
结论
如果你花一些时间和精力在手册页上,你将会取得胜利。你对手册页的熟练程度,将在你掌握 Linux 的过程中发挥巨大作用。
via: https://itsfoss.com/linux-man-page-guide/
作者:Bill Dyer 选题:lujun9972 译者:wxy 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出