通常,Linux 管理员们都使用 history 命令来跟踪在先前的会话中执行过哪些命令,但是 history 命令的局限性在于它不存储命令的输出。在某些情况下,我们要检查上一个会话的命令输出,并希望将其与当前会话进行比较。除此之外,在某些情况下,我们正在对 Linux 生产环境中的问题进行故障排除,并希望保存所有终端会话活动以供将来参考,因此在这种情况下,script 命令就变得很方便。

script 是一个命令行工具,用于捕获/记录你的 Linux 服务器终端会话活动,以后可以使用 scriptreplay 命令重放记录的会话。在本文中,我们将演示如何安装 script 命令行工具以及如何记录 Linux 服务器终端会话活动,然后,我们将看到如何使用 scriptreplay 命令来重放记录的会话。
安装 script 工具
在 RHEL 7/ CentOS 7 上安装 script 工具
script 命令由 RPM 包 util-linux 提供,如果你没有在你的 CentOS 7 / RHEL 7 系统上安装它,运行下面的 yum 安装它:
[root@linuxtechi ~]# yum install util-linux -y
在 RHEL 8 / CentOS 8 上安装 script 工具
运行下面的 dnf 命令来在 RHEL 8 / CentOS 8 上安装 script 工具:
[root@linuxtechi ~]# dnf install util-linux -y
在基于 Debian 的系统(Ubuntu / Linux Mint)上安装 script 工具
运行下面的 apt-get 命令来安装 script 工具:
root@linuxtechi ~]# apt-get install util-linux -y
如何使用 script 工具
直接使用 script 命令,在终端上键入 script 命令,然后按回车,它将开始在名为 typescript 的文件中捕获当前的终端会话活动。
[root@linuxtechi ~]# script
Script started, file is typescript
[root@linuxtechi ~]#
要停止记录会话活动,请键入 exit 命令,然后按回车:
[root@linuxtechi ~]# exit
exit
Script done, file is typescript
[root@linuxtechi ~]#
script 命令的语法格式:
~] # script {options} {file_name}
能在 script 命令中使用的不同选项:

让我们开始通过执行 script 命令来记录 Linux 终端会话,然后执行诸如 w,route -n,df -h 和 free -h,示例如下所示:

正如我们在上面看到的,终端会话日志保存在文件 typescript 中:
现在使用 cat / vi 命令查看 typescript 文件的内容,
[root@linuxtechi ~]# ls -l typescript
-rw-r--r--. 1 root root 1861 Jun 21 00:50 typescript
[root@linuxtechi ~]#

以上内容确认了我们在终端上执行的所有命令都已保存在 typescript 文件中。
在 script 命令中使用定制文件名
假设我们要使用自定义文件名来执行 script 命令,可以在 script 命令后指定文件名。在下面的示例中,我们使用的文件名为 session-log-(当前日期时间).txt。
[root@linuxtechi ~]# script sessions-log-$(date +%d-%m-%Y-%T).txt
Script started, file is sessions-log-21-06-2019-01:37:39.txt
[root@linuxtechi ~]#
现在运行该命令并输入 exit:
[root@linuxtechi ~]# exit
exit
Script done, file is sessions-log-21-06-2019-01:37:39.txt
[root@linuxtechi ~]#
附加命令输出到 script 记录文件
假设 script 命令已经将命令输出记录到名为 session-log.txt 的文件中,现在我们想将新会话命令的输出附加到该文件中,那么可以在 script 命令中使用 -a 选项。
[root@linuxtechi ~]# script -a sessions-log.txt
Script started, file is sessions-log.txt
[root@linuxtechi ~]# xfs_info /dev/mapper/centos-root
meta-data=/dev/mapper/centos-root isize=512 agcount=4, agsize=2746624 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=10986496, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=5364, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@linuxtechi ~]# exit
exit
Script done, file is sessions-log.txt
[root@linuxtechi ~]#
要查看更新的会话记录,使用 cat session-log.txt 命令。
无需 shell 交互而捕获命令输出到 script 记录文件
假设我们要捕获命令的输出到会话记录文件,那么使用 -c 选项,示例如下所示:
[root@linuxtechi ~]# script -c "uptime && hostname && date" root-session.txt
Script started, file is root-session.txt
01:57:40 up 2:30, 3 users, load average: 0.00, 0.01, 0.05
linuxtechi
Fri Jun 21 01:57:40 EDT 2019
Script done, file is root-session.txt
[root@linuxtechi ~]#
以静默模式运行 script 命令
要以静默模式运行 script 命令,请使用 -q 选项,该选项将禁止 script 的启动和完成消息,示例如下所示:
[root@linuxtechi ~]# script -c "uptime && date" -q root-session.txt
02:01:10 up 2:33, 3 users, load average: 0.00, 0.01, 0.05
Fri Jun 21 02:01:10 EDT 2019
[root@linuxtechi ~]#
要将时序信息记录到文件中并捕获命令输出到单独的文件中,这可以通过在 script 命令中传递时序文件(-timing)实现,示例如下所示:
语法格式:
~ ]# script -t <timing-file-name> {file_name}
[root@linuxtechi ~]# script --timing=timing.txt session.log
Script started, file is session.log
[root@linuxtechi ~]# uptime
02:27:59 up 3:00, 3 users, load average: 0.00, 0.01, 0.05
[root@linuxtechi ~]# date
Fri Jun 21 02:28:02 EDT 2019
[root@linuxtechi ~]# free -h
total used free shared buff/cache available
Mem: 3.9G 171M 2.0G 8.6M 1.7G 3.3G
Swap: 3.9G 0B 3.9G
[root@linuxtechi ~]# whoami
root
[root@linuxtechi ~]# exit
exit
Script done, file is session.log
[root@linuxtechi ~]#
[root@linuxtechi ~]# ls -l session.log timing.txt
-rw-r--r--. 1 root root 673 Jun 21 02:28 session.log
-rw-r--r--. 1 root root 414 Jun 21 02:28 timing.txt
[root@linuxtechi ~]#
重放记录的 Linux 终端会话活动
现在,使用 scriptreplay 命令重放录制的终端会话活动。
注意:scriptreplay 也由 RPM 包 util-linux 提供。scriptreplay 命令需要时序文件才能工作。
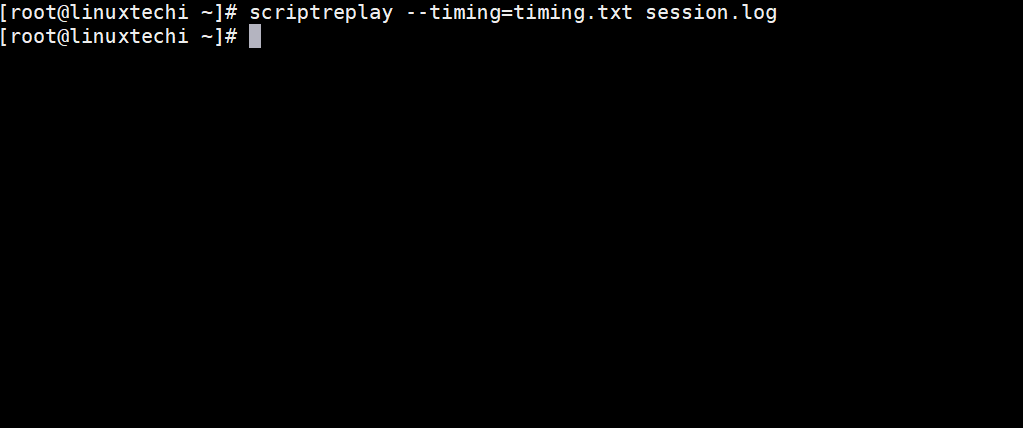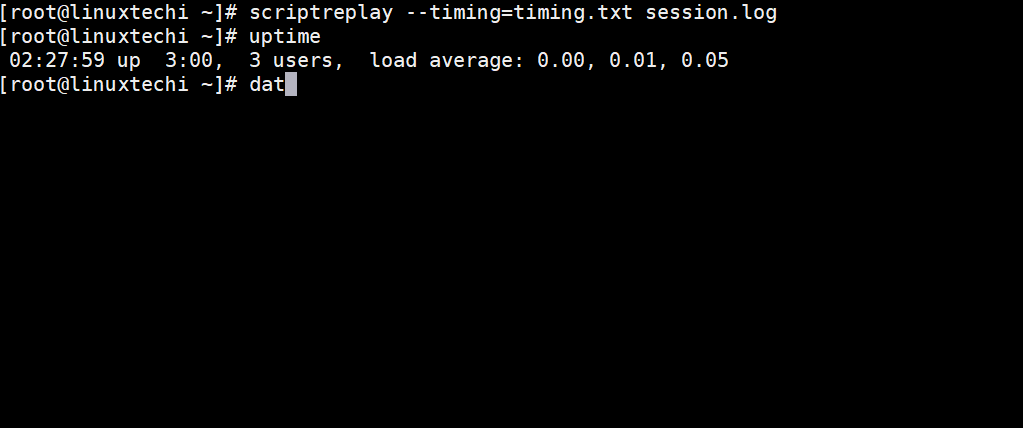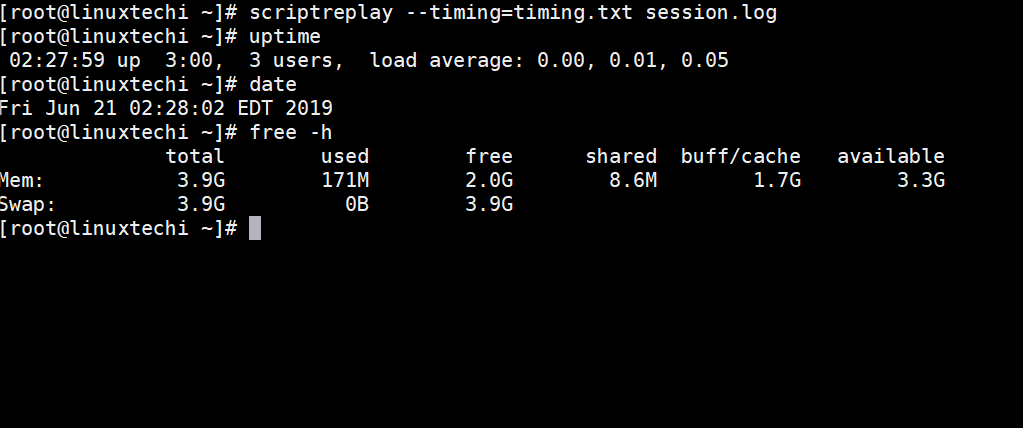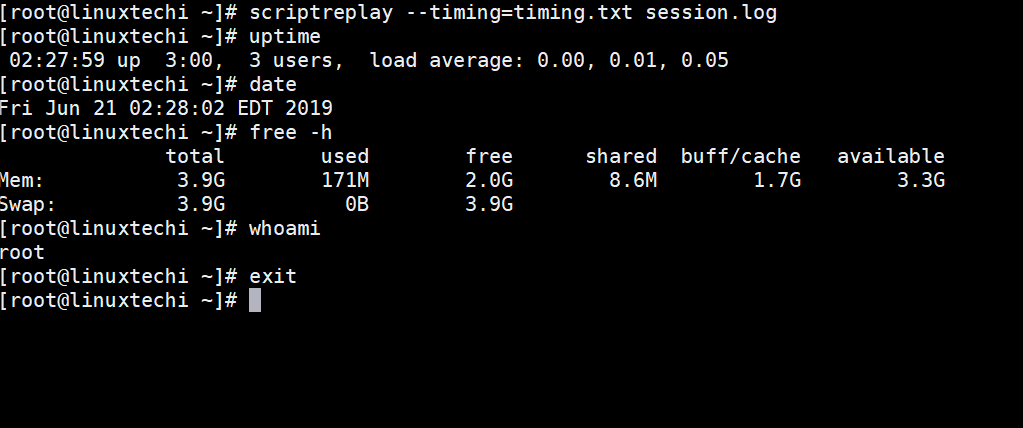
[root@linuxtechi ~]# scriptreplay --timing=timing.txt session.log
上面命令的输出将如下所示,
记录所有用户的 Linux 终端会话活动
在某些关键业务的 Linux 服务器上,我们希望跟踪所有用户的活动,这可以使用 script 命令来完成,将以下内容放在 /etc/profile 文件中,
[root@linuxtechi ~]# vi /etc/profile
……………………………………………………
if [ "x$SESSION_RECORD" = "x" ]
then
timestamp=$(date +%d-%m-%Y-%T)
session_log=/var/log/session/session.$USER.$$.$timestamp
SESSION_RECORD=started
export SESSION_RECORD
script -t -f -q 2>${session_log}.timing $session_log
exit
fi
……………………………………………………
保存文件并退出。
在 /var/log 文件夹下创建 session 目录:
[root@linuxtechi ~]# mkdir /var/log/session
给该文件夹指定权限:
[root@linuxtechi ~]# chmod 777 /var/log/session/
[root@linuxtechi ~]#
现在,验证以上代码是否有效。在我正在使用 pkumar 用户的情况下,登录普通用户到 Linux 服务器:
~ ] # ssh root@linuxtechi
root@linuxtechi's password:
[root@linuxtechi ~]$ uptime
04:34:09 up 5:06, 3 users, load average: 0.00, 0.01, 0.05
[root@linuxtechi ~]$ date
Fri Jun 21 04:34:11 EDT 2019
[root@linuxtechi ~]$ free -h
total used free shared buff/cache available
Mem: 3.9G 172M 2.0G 8.6M 1.7G 3.3G
Swap: 3.9G 0B 3.9G
[root@linuxtechi ~]$ id
uid=1001(pkumar) gid=1002(pkumar) groups=1002(pkumar) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
[root@linuxtechi ~]$ whoami
pkumar
[root@linuxtechi ~]$ exit
Login as root and view user’s linux terminal session activity
[root@linuxtechi ~]# cd /var/log/session/
[root@linuxtechi session]# ls -l | grep pkumar
-rw-rw-r--. 1 pkumar pkumar 870 Jun 21 04:34 session.pkumar.19785.21-06-2019-04:34:05
-rw-rw-r--. 1 pkumar pkumar 494 Jun 21 04:34 session.pkumar.19785.21-06-2019-04:34:05.timing
[root@linuxtechi session]#

我们还可以使用 scriptreplay 命令来重放用户的终端会话活动:
[root@linuxtechi session]# scriptreplay --timing session.pkumar.19785.21-06-2019-04\:34\:05.timing session.pkumar.19785.21-06-2019-04\:34\:05
以上就是本教程的全部内容,请在下面的评论部分中分享你的反馈和评论。
via: https://www.linuxtechi.com/record-replay-linux-terminal-sessions-activity/
作者:Pradeep Kumar 选题:lujun9972 译者:wxy 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出












