如何在 Linux 上查找硬件规格

在 Linux 系统上有许多工具可用于查找硬件规格。在这里,我列出了四种最常用的工具,可以获取 Linux 系统的几乎所有硬件(和软件)细节。好在是这些工具在某些 Linux 发行版上默认预装。我在 Ubuntu 18.04 LTS 桌面上测试了这些工具,但是它们也适用于其他 Linux 发行版。
1、LSHW
lshw(硬件列表)是一个简单但功能齐全的实用程序,它提供了 Linux 系统上的硬件规格的详细信息。它可以报告确切的内存规格、固件版本、主板规格、CPU 版本和速度、缓存规格、总线速度等。信息可以以纯文本、XML 或 HTML 格式输出。
它目前支持 DMI(仅限 x86 和 EFI)、Open Firmware 设备树(仅限 PowerPC)、PCI/AGP、ISA PnP(x86)、CPUID(x86)、IDE/ATA/ATAPI、PCMCIA(仅在 x86 上测试过)、USB 和 SCSI。
就像我已经说过的那样,Ubuntu 默认预装了 lshw。如果它未安装在你的 Ubuntu 系统中,请使用以下命令安装它:
$ sudo apt install lshw lshw-gtk在其他 Linux 发行版上,例如 Arch Linux,运行:
$ sudo pacman -S lshw lshw-gtk安装后,运行 lshw 以查找系统硬件详细信息:
$ sudo lshw你将看到输出详细的系统硬件。
示例输出:
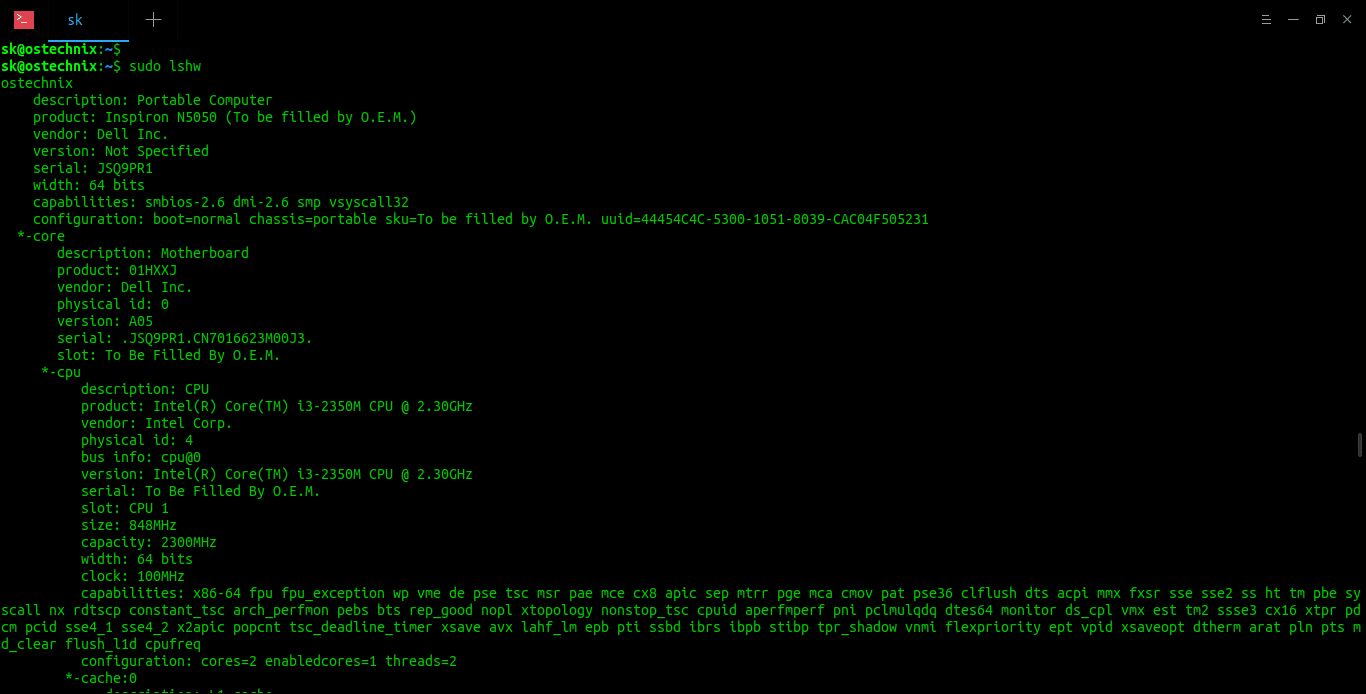
使用 lshw 在 Linux 上查找硬件规格
请注意,如果你没有以 sudo 权限运行 lshw 命令,则输出可能不完整或不准确。
lshw 可以将输出显示为 HTML 页面。为此,请使用:
$ sudo lshw -html同样,我们可以将设备树输出为 XML 和 json 格式,如下所示:
$ sudo lshw -xml
$ sudo lshw -json要输出显示硬件路径的设备树,请使用 -short 选项:
$ sudo lshw -short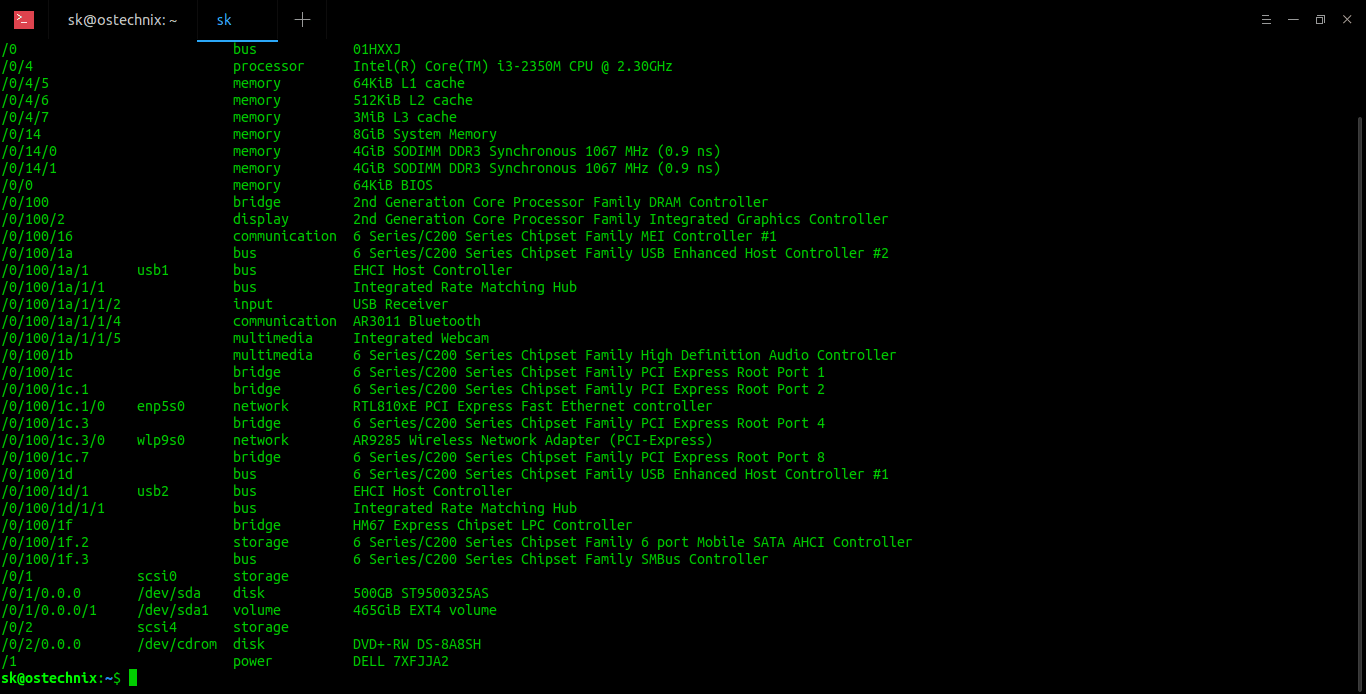
使用 lshw 显示具有硬件路径的设备树
要列出设备的总线信息、详细的 SCSI、USB、IDE 和 PCI 地址,请运行:
$ sudo lshw -businfo默认情况下,lshw 显示所有硬件详细信息。你还可以使用类选项查看特定硬件详细信息的硬件信息,例如处理器、内存、显示器等。可以使用 lshw -short 或 lshw -businfo 找到类选项。
要显示特定硬件详细信息,例如处理器,请执行以下操作:
$ sudo lshw -class processor示例输出:
*-cpu
description: CPU
product: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
vendor: Intel Corp.
physical id: 4
bus info: [email protected]
version: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
serial: To Be Filled By O.E.M.
slot: CPU 1
size: 913MHz
capacity: 2300MHz
width: 64 bits
clock: 100MHz
capabilities: x86-64 fpu fpu_exception wp vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer xsave avx lahf_lm epb pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid xsaveopt dtherm arat pln pts md_clear flush_l1d cpufreq
configuration: cores=2 enabledcores=1 threads=2类似的,你可以得到系统细节:
$ sudo lshw -class system硬盘细节:
$ sudo lshw -class disk网络细节:
$ sudo lshw -class network内存细节:
$ sudo lshw -class memory你也可以像下面这样列出多个设备的细节:
$ sudo lshw -class storage -class power -class volume如果你想要查看带有硬件路径的细节信息,加上 -short 选项即可:
$ sudo lshw -short -class processor示例输出:
H/W path Device Class Description
=======================================================
/0/4 processor Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz有时,你可能希望将某些硬件详细信息共享给别人,例如客户支持人员。如果是这样,你可以从输出中删除潜在的敏感信息,如 IP 地址、序列号等,如下所示。
$ lshw -sanitizelshw-gtk GUI 工具
如果你对 CLI 不熟悉,可以使用 lshw-gtk,这是 lshw 命令行工具的图形界面。
它可以从终端或 Dash 中打开。
要从终端启动它,只需执行以下操作:
$ sudo lshw-gtk这是 lshw 工具的默认 GUI 界面。
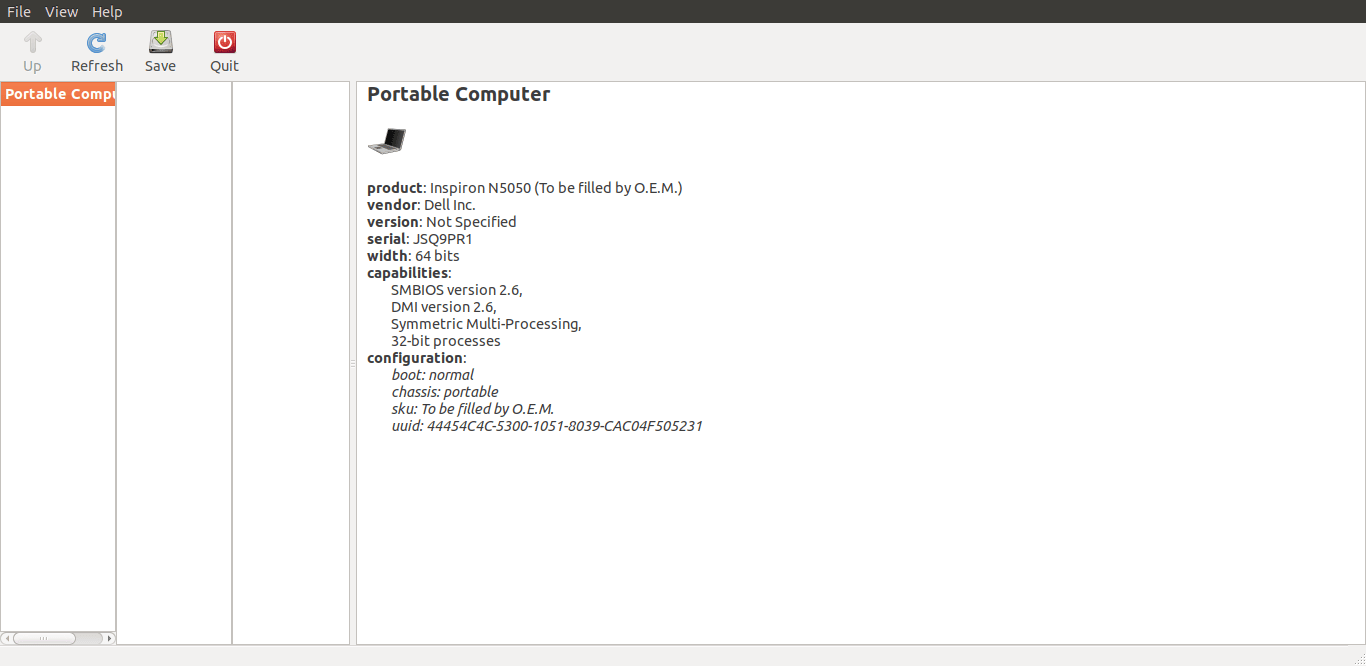
使用 lshw-gtk 在 Linux 上查找硬件
只需双击“Portable Computer”即可进一步展开细节。
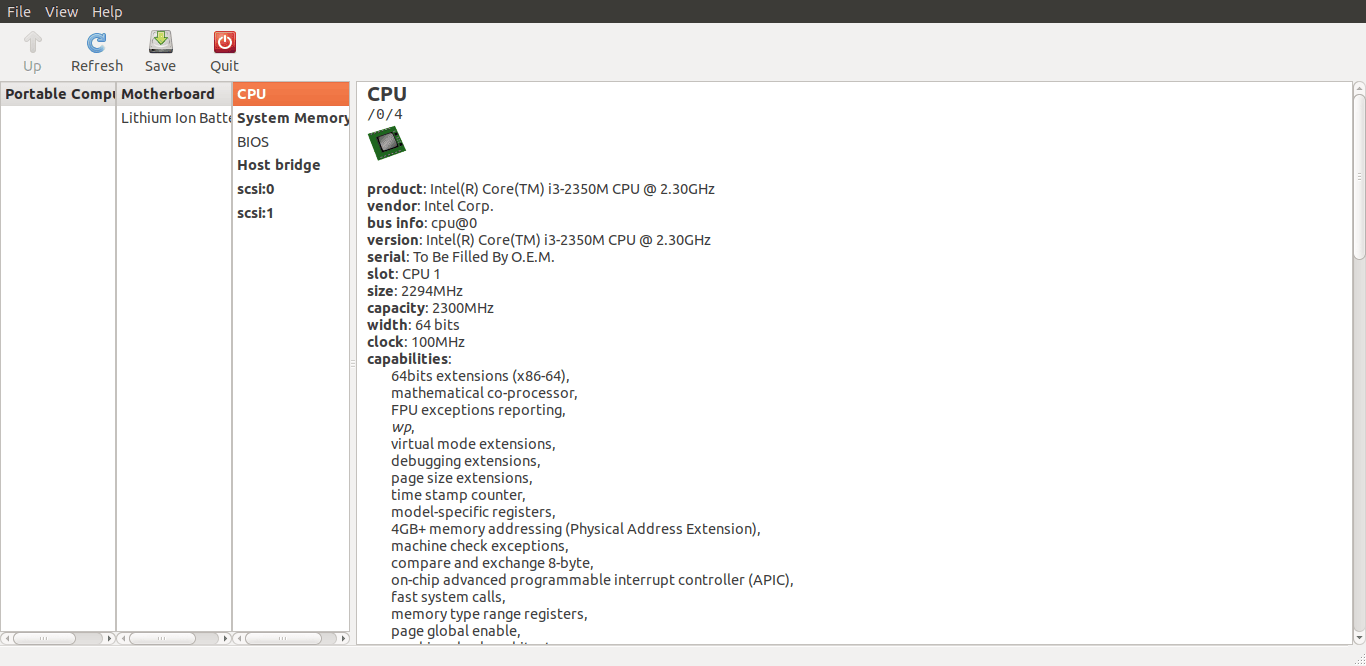
使用 lshw-gtk GUI 在 Linux 上查找硬件
你可以双击后续的硬件选项卡以获取详细视图。
有关更多详细信息,请参阅手册页。
$ man lshw2、Inxi
Inxi 是我查找 Linux 系统上几乎所有内容的另一个最喜欢的工具。它是一个自由开源的、功能齐全的命令行系统信息工具。它显示了系统硬件、CPU、驱动程序、Xorg、桌面、内核、GCC 版本、进程、RAM 使用情况以及各种其他有用信息。无论是硬盘还是 CPU、主板还是整个系统的完整细节,inxi 都能在几秒钟内更准确地显示它。由于它是 CLI 工具,你可以在桌面或服务器版本中使用它。有关更多详细信息,请参阅以下指南。
3、Hardinfo
Hardinfo 将为你提供 lshw 中没有的系统硬件和软件详细信息。
HardInfo 可以收集有关系统硬件和操作系统的信息,执行基准测试,并以 HTML 或纯文本格式生成可打印的报告。
如果 Ubuntu 中未安装 Hardinfo,请使用以下命令安装:
$ sudo apt install hardinfo安装后,Hardinfo 工具可以从终端或菜单中进行。
以下是 Hardinfo 默认界面的外观。
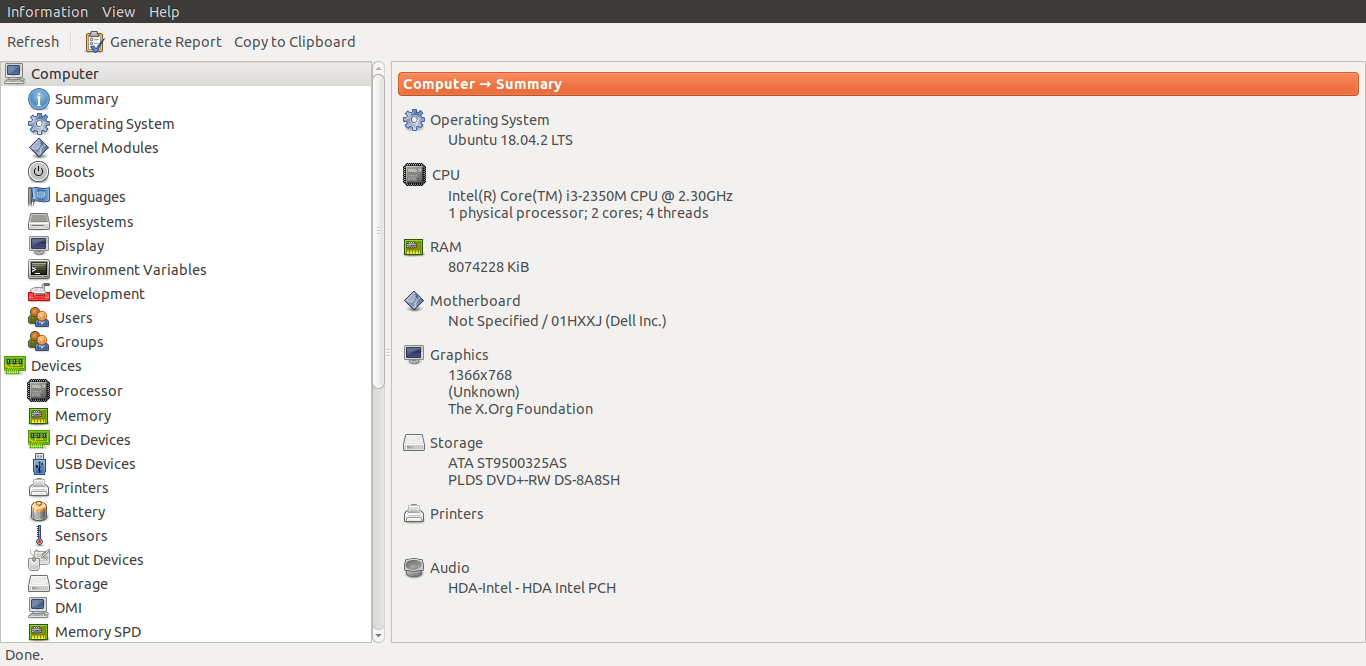
使用 Hardinfo 在 Linux 上查找硬件
正如你在上面的屏幕截图中看到的,Hardinfo 的 GUI 简单直观。
所有硬件信息分为四个主要组:计算机、设备、网络和基准。每个组都显示特定的硬件详细信息。
例如,要查看处理器详细信息,请单击“设备”组下的“处理器”选项。
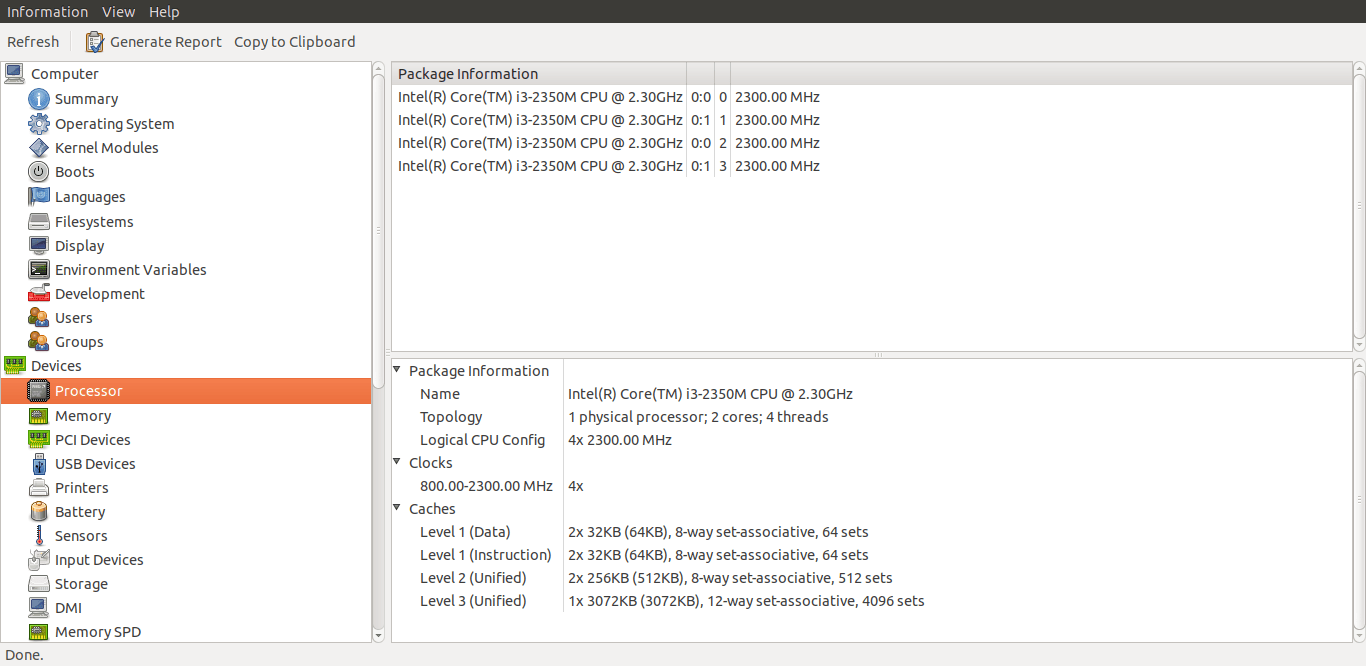
使用 hardinfo 显示处理器详细信息
与 lshw 不同,Hardinfo 可帮助你查找基本软件规范,如操作系统详细信息、内核模块、区域设置信息、文件系统使用情况、用户/组和开发工具等。
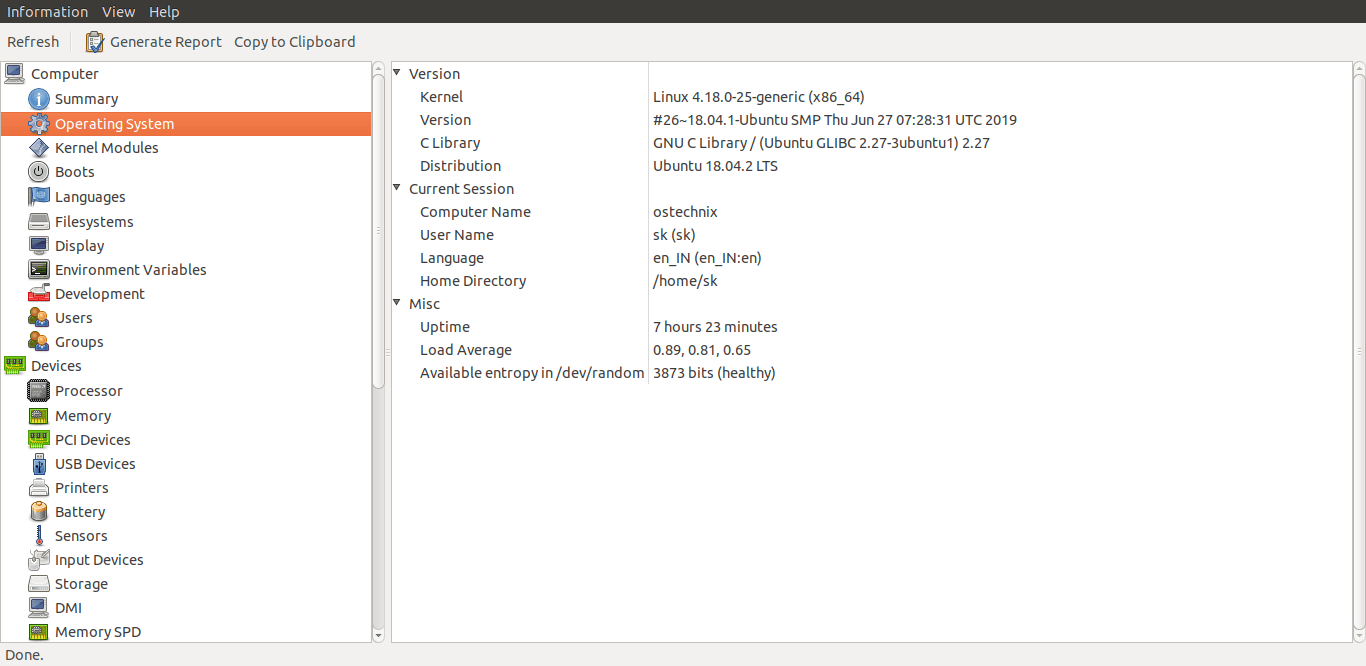
使用 hardinfo 显示操作系统详细信息
Hardinfo 的另一个显着特点是它允许我们做简单的基准测试来测试 CPU 和 FPU 功能以及一些图形用户界面功能。
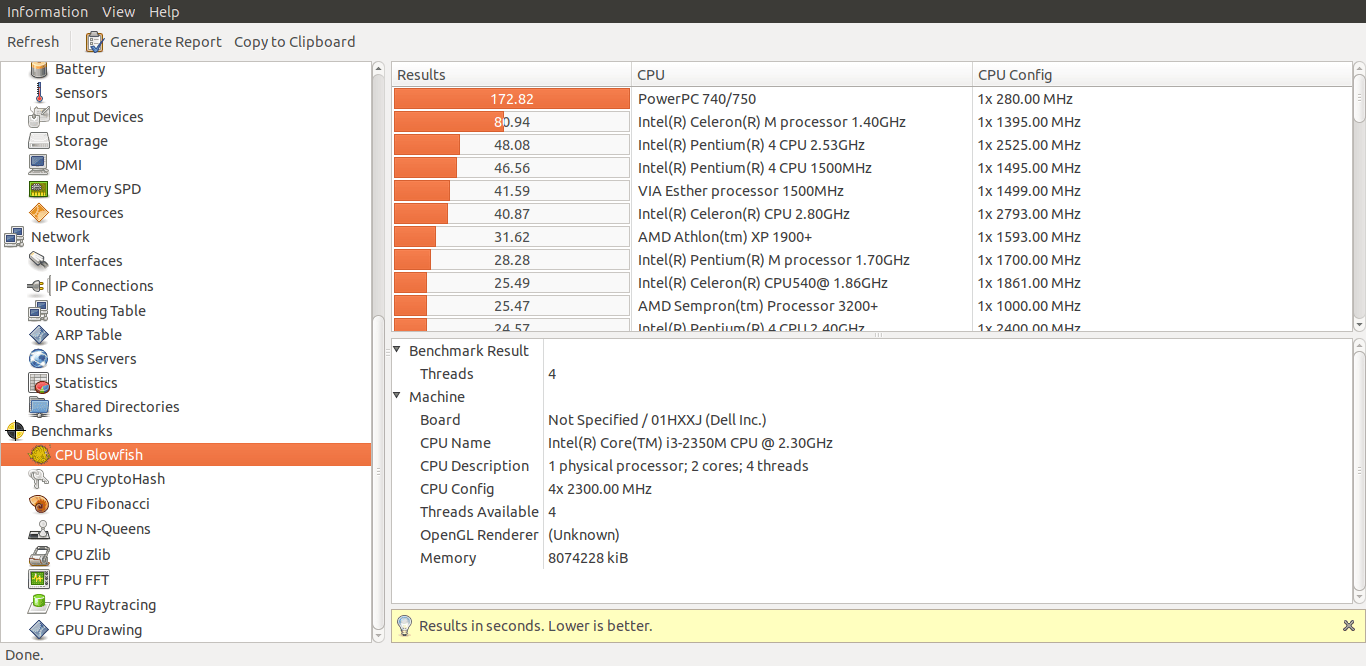
使用 hardinfo 执行基准测试
建议阅读:
我们可以生成整个系统以及各个设备的报告。要生成报告,只需单击菜单栏上的“生成报告”按钮,然后选择要包含在报告中的信息。
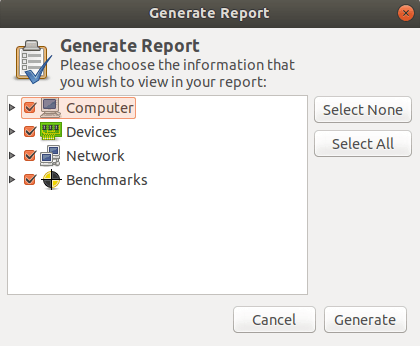
使用 hardinfo 生成系统报告
Hardinfo 也有几个命令行选项。
例如,要生成报告并在终端中显示它,请运行:
$ hardinfo -r列出模块:
$ hardinfo -l更多信息请参考手册:
$ man hardinfo4、Sysinfo
Sysinfo 是 HardInfo 和 lshw-gtk 实用程序的另一个替代品,可用于获取下面列出的硬件和软件信息。
- 系统详细信息,如发行版版本、GNOME 版本、内核、gcc 和 Xorg 以及主机名。
- CPU 详细信息,如供应商标识、型号名称、频率、L2 缓存、型号和标志。
- 内存详细信息,如系统全部内存、可用内存、交换空间总量和空闲、缓存、活动/非活动的内存。
- 存储控制器,如 IDE 接口、所有 IDE 设备、SCSI 设备。
- 硬件详细信息,如主板、图形卡、声卡和网络设备。
让我们使用以下命令安装 sysinfo:
$ sudo apt install sysinfoSysinfo 可以从终端或 Dash 启动。
要从终端启动它,请运行:
$ sysinfo这是 Sysinfo 实用程序的默认界面。
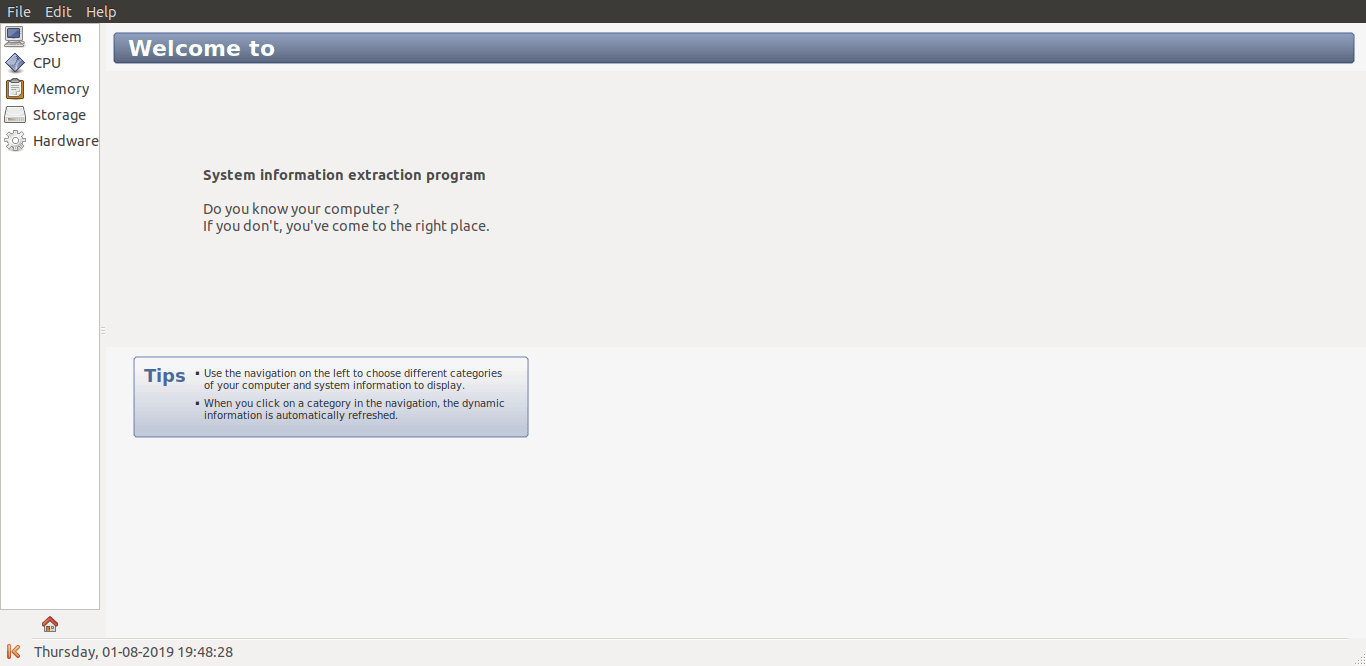
sysinfo 界面
如你所见,所有硬件(和软件)详细信息都分为五类,即系统、CPU、内存、存储和硬件。单击导航栏上的类别以获取相应的详细信息。
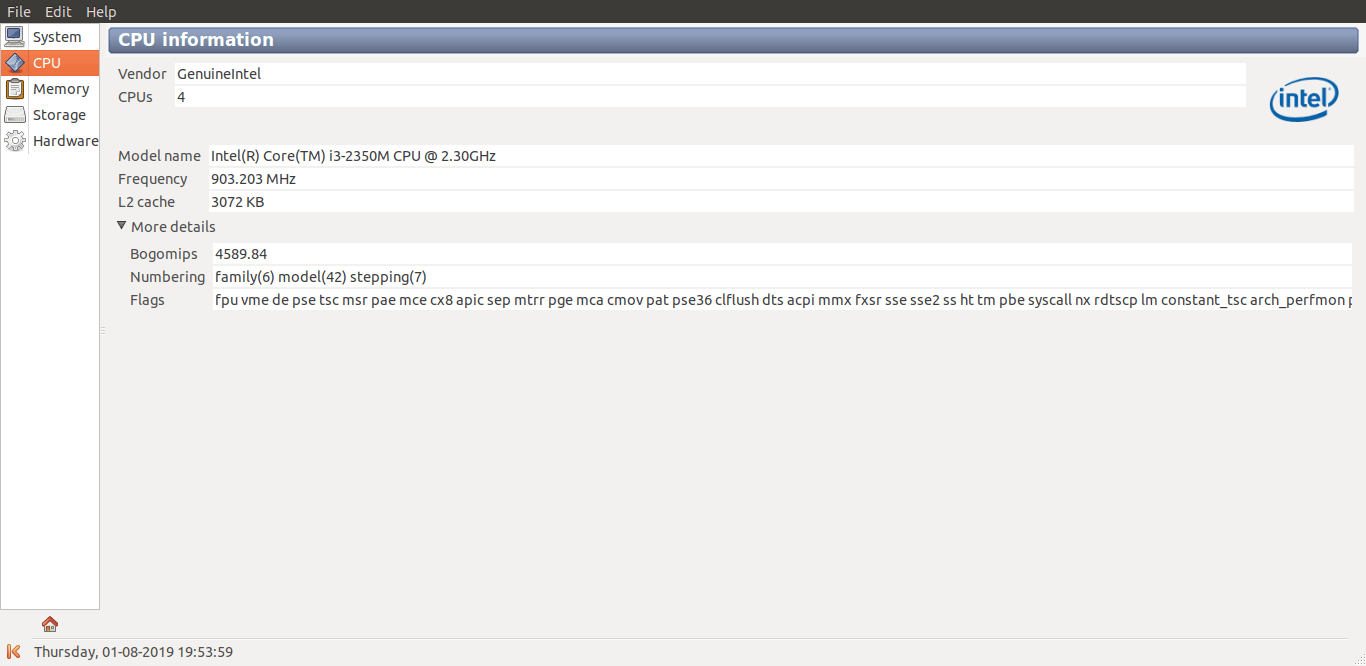
使用 Sysinfo 在 Linux 上查找硬件
更多细节可以在手册页上找到。
$ man sysinfo就这样。就像我已经提到的那样,可以有很多工具可用于显示硬件/软件规范。但是,这四个工具足以找到你的 Linux 发行版的所有软硬件规格信息。
via: https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/