PPython:PHP 拥抱 Python 的利器

介绍
Python 与 PHP 都是广泛使用的语言,各有所长,让人期待两者结合可以实现更丰富的效果。
在 PHP 中调用 Python 实现某些处理,这种需求虽然比较小众,还是实用的。目前网上可以查到很多资料仍在探讨 exec()(也包括 system()、shell_exec()、passthru() 等)执行外部的 Python 文件,但这只是一种通用的方式,调用成本比较高,在每次调用时,需要装载整个 Python 解释环境。
有此类需求的开发者非常适合看一下 PPython,这是一种从根本上将 PHP 与 Python 有效结合的技术。
PPython 最初见于 https://code.google.com/p/ppython,该作者将 lajp(一种 PHP 结合 Java 的技术)移植到了 Python 上。
该项目最初建立于 2012 年,而且似乎已经停止维护多年,不过目前来看其思路及效果还是值得肯定的,因此将此项目从停止运营的 Google Code 上迁移到了 GitHub,并遵循原 Apache 许可证重新发布和维护。
日前笔者对此作了一番尝试,对 PPython 的方便易用有所体会。
原理与架构
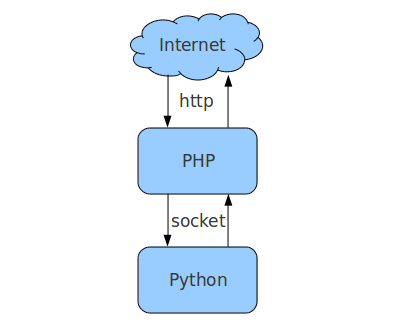
PHP 与 Python 通讯有两种不同的套接字机制:TCP 套接字和 UNIX 套接字。UNIX 套接字是 Unix/Linux 本地套接字,相对于 TCP 套接字,具有以下特点:
- 只能在同一台主机中通讯(IPC),不能跨主机;
- 传输速度大于 TCP 套接字;
- 服务端只向本机提供服务(没有对外侦听端口),相对安全,易于管理。
PHP 和 Python 各有其语言内部定义的数据类型,通常 PHP 进程与 Python 进程进行数据交互时,需要进行转码处理。此类转换如由应用自行实现,从开发效率到运行性能都会增加不少额外负担。
PPython 对 PHP 和 Python 间的通讯方式的处理支持 TCP 套接字和 UNIX 套接字两种机制,兼顾通讯效率和分布式,转码由服务统一处理,Python 为 PHP 的数据类型提供格式兼容,使 PHP 端开发无须为底层通讯担心。
Python 因其语言 GIL 特性,同一进程内多线程效率不高。PPython 可根据项目需要部署服务,多进程运行 Python,提高应用综合性能。
使用方法
PPython 的代码可从上述项目仓库中下载。
下载得到的文件中,以下三个是 PPython 的核心代码,作用如下:
php_python.py,Python 进程主文件,完成 Python 端监听请求并运行返回process.py,Python 端核心类,实现 Python 内部进程调用及 PHP 与 Python 数据结构转化等关键处理php_python.php,PPython 客户端,PHP 端引用此文件,可直接使用 PPython 函数实现调用。
将以上文件放置到任意目录。先修改准备运行 PPython 的端口,监听端口不限,只要 php_python.py 和 php_python.php 两端修改一致。笔者统一改为 10240。
在当前目录下运行 php_python.py,只要 Python 环境正常,便将运行起一个 PPython 的服务。
-------------------------------------------
- PPython Service
- Time: 2019-05-13 22:24:09
-------------------------------------------
Listen port: 10240
charset: utf-8
Server startup...PHP 端引入 php_python.php,就可以用 ppython 函数与之前启动的 PPython 服务通讯,传入请求由 PPython 服务调用 Python 处理后返回结果,如 $res = ppython('test::go') 是调用test.py 中的 go 函数,也可加上更多参数,第二个参数起将为被调的函数传递更多参数。
php_python.py 是 PPython 启动后直接运行的全局代码,有全局配置或进程启动后的通用处理都写在这里,如原生代码中建立了数据库连接等,项目中应视情况作优化。
但 Python 令人感兴趣的主要方面不只是像 PHP 那样描述业务功能,它可以在人工智能等领域所需要的计算型任务提供对更复杂的数据结构的处理,因此二者的结合可以给 PHP 带来更多应用场景。
改进
此外,原生的 php_python.py 还有些不足。笔者用 ppython 调用自定义代码中遇到了三个问题,并相应做了解决:
- 不支持
complex(复数类),复数是数学上的一种数据类型,主要包括real(实部)和imag(虚部)数据,虽然日常生活中遇到较少,但 AI 和各种专业研究领域或并不罕见。Python 里有complex类,对复数可以直接进行各种计算,但PPython序列化和反序列化对complex没有处理。为了能让complex包括的数据能正常返回,只要在process.py的z_encode()方法中加上符合 PHP 要求的序列化处理,代码如下:
elif isinstance(p, numpy.complex128):
t1 = str(p.real)
t2 = str(p.imag)
return 'O:7:"complex":2:{s:4:"real";d:%s;s:4:"imag";d:%s;}' % (t1,t2)- 不支持
ndarray(多维数组)。相比complex,ndarray要普通得多,相信凡使用到 Python 的各种计算功能,ndarray是无法回避的,甚至ndarray在一定程度上成就了 Python。但原php_python.py不能识别ndarray。不过解决起来并不难,在process.py里找到z_encode()方法,加上下面这段,可以直接将ndarray转化为符合 PHP 要求的数组(数字索引)。
elif isinstance(p, numpy.ndarray):
s = ''
i = 0
for d in p:
s += 'i:%d;%s' % (i,z_encode(d))
i += 1
return "a:%d:{%s}" % (len(p),s)- 原代码不太稳健,如数据为
ndarray类型,if p == None:报错ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all(),因为p == None的结果也是ndarray,不返回false,将判断方法改为if p is None:可避免出错。
相应地 PHP 端也要注意一下序列化和反序列化的处理。
处理回复中类似 complex 这样的对象数据时,如系统中没有定义相应的类,PHP 是可以反序列化的,但将显示为 “incomplete object”,vardump 看得到 real 和 imag 数据,但不能直接操作,自行定义 complex 类后,则按指定的类进行解析,与 PHP 内的一般对象无异,可以轻松进行所有操作。
至此,PHP 与 Python 的功能调讯已无问题。
补充:注册为服务
命令行下启动 php_python.py 主要是方便调试,可以看到观察反馈信息等,生产环境中手工启动 PPython 毕竟不太方便。可以将 PPython 配置成服务,修改端口也可以为不同的应用配置不同的 PPython 端。
Linux 下将一个进程注册为服务很简单,只要建立 /usr/lib/systemd/system/ppython.service,内容如下:
[Unit]
Description=PHP-Python Service
After=network.target remote-fs.target nss-lookup.target
[Service]
ExecStart={PPYTHON_PATH}/php_python.py
[Install]
WantedBy=multi-user.target其中 {PPYTHON_PATH} 要改成实际路径。
总结
有了 PPython,可以摒弃 exec() 这种 shell 调用,使开发回归到逻辑本身。
个人认为该方案值得所有对 PHP 和 Python 都感兴趣的开发人员了解,也欢迎大家参与和贡献这个项目。