在 Ubuntu 18.04 LTS 无头服务器上安装 Oracle VirtualBox

本教程将指导你在 Ubuntu 18.04 LTS 无头服务器上,一步一步地安装 Oracle VirtualBox。同时,本教程也将介绍如何使用 phpVirtualBox 去管理安装在无头服务器上的 VirtualBox 实例。phpVirtualBox 是 VirtualBox 的一个基于 Web 的前端工具。这个教程也可以工作在 Debian 和其它 Ubuntu 衍生版本上,如 Linux Mint。现在,我们开始。
前提条件
在安装 Oracle VirtualBox 之前,我们的 Ubuntu 18.04 LTS 服务器上需要满足如下的前提条件。
首先,逐个运行如下的命令来更新 Ubuntu 服务器。
$ sudo apt update
$ sudo apt upgrade
$ sudo apt dist-upgrade接下来,安装如下的必需的包:
$ sudo apt install build-essential dkms unzip wget安装完成所有的更新和必需的包之后,重启动 Ubuntu 服务器。
$ sudo reboot在 Ubuntu 18.04 LTS 服务器上安装 VirtualBox
添加 Oracle VirtualBox 官方仓库。为此你需要去编辑 /etc/apt/sources.list 文件:
$ sudo nano /etc/apt/sources.list添加下列的行。
在这里,我将使用 Ubuntu 18.04 LTS,因此我添加下列的仓库。
deb http://download.virtualbox.org/virtualbox/debian bionic contrib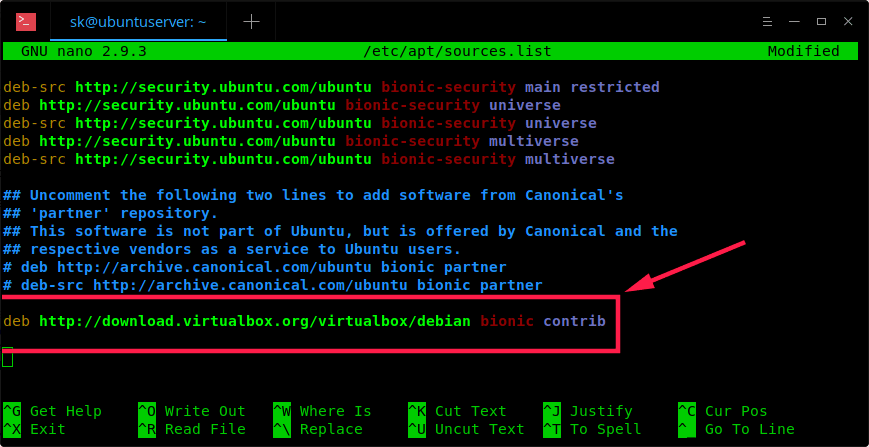
用你的 Ubuntu 发行版的代码名字替换关键字 ‘bionic’,比如,‘xenial’、‘vivid’、‘utopic’、‘trusty’、‘raring’、‘quantal’、‘precise’、‘lucid’、‘jessie’、‘wheezy’、或 ‘squeeze‘。
然后,运行下列的命令去添加 Oracle 公钥:
$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -对于 VirtualBox 的老版本,添加如下的公钥:
$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -接下来,使用如下的命令去更新软件源:
$ sudo apt update最后,使用如下的命令去安装最新版本的 Oracle VirtualBox:
$ sudo apt install virtualbox-5.2添加用户到 VirtualBox 组
我们需要去创建并添加我们的系统用户到 vboxusers 组中。你也可以单独创建用户,然后将它分配到 vboxusers 组中,也可以使用已有的用户。我不想去创建新用户,因此,我添加已存在的用户到这个组中。请注意,如果你为 virtualbox 使用一个单独的用户,那么你必须注销当前用户,并使用那个特定的用户去登入,来完成剩余的步骤。
我使用的是我的用户名 sk,因此,我运行如下的命令将它添加到 vboxusers 组中。
$ sudo usermod -aG vboxusers sk现在,运行如下的命令去检查 virtualbox 内核模块是否已加载。
$ sudo systemctl status vboxdrv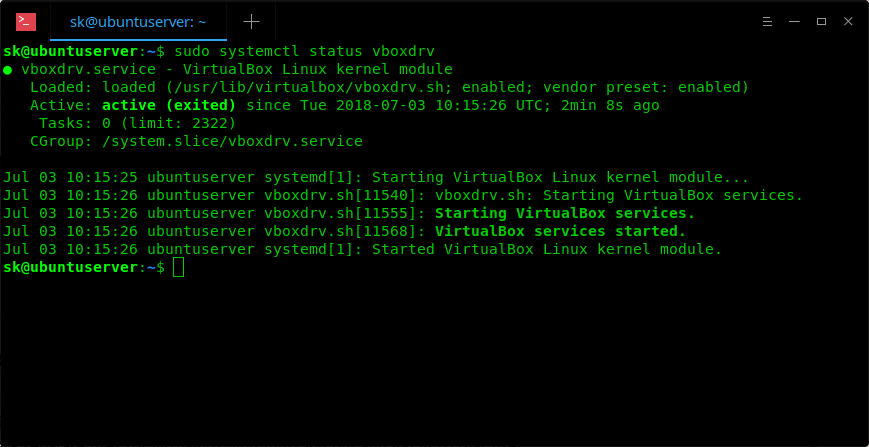
正如你在上面的截屏中所看到的,vboxdrv 模块已加载,并且是已运行的状态!
对于老的 Ubuntu 版本,运行:
$ sudo /etc/init.d/vboxdrv status如果 virtualbox 模块没有启动,运行如下的命令去启动它。
$ sudo /etc/init.d/vboxdrv setup很好!我们已经成功安装了 VirtualBox 并启动了 virtualbox 模块。现在,我们继续来安装 Oracle VirtualBox 的扩展包。
安装 VirtualBox 扩展包
VirtualBox 扩展包为 VirtualBox 访客系统提供了如下的功能。
- 虚拟的 USB 2.0 (EHCI) 驱动
- VirtualBox 远程桌面协议(VRDP)支持
- 宿主机网络摄像头直通
- Intel PXE 引导 ROM
- 对 Linux 宿主机上的 PCI 直通提供支持
从这里为 VirtualBox 5.2.x 下载最新版的扩展包。
$ wget https://download.virtualbox.org/virtualbox/5.2.14/Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack使用如下的命令去安装扩展包:
$ sudo VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-5.2.14.vbox-extpack恭喜!我们已经成功地在 Ubuntu 18.04 LTS 服务器上安装了 Oracle VirtualBox 的扩展包。现在已经可以去部署虚拟机了。参考 virtualbox 官方指南,在命令行中开始创建和管理虚拟机。
然而,并不是每个人都擅长使用命令行。有些人可能希望在图形界面中去创建和使用虚拟机。不用担心!下面我们为你带来非常好用的 phpVirtualBox 工具!
关于 phpVirtualBox
phpVirtualBox 是一个免费的、基于 web 的 Oracle VirtualBox 后端。它是使用 PHP 开发的。用 phpVirtualBox 我们可以通过 web 浏览器从网络上的任意一个系统上,很轻松地创建、删除、管理、和执行虚拟机。
在 Ubuntu 18.04 LTS 上安装 phpVirtualBox
由于它是基于 web 的工具,我们需要安装 Apache web 服务器、PHP 和一些 php 模块。
为此,运行如下命令:
$ sudo apt install apache2 php php-mysql libapache2-mod-php php-soap php-xml然后,从 下载页面 上下载 phpVirtualBox 5.2.x 版。请注意,由于我们已经安装了 VirtualBox 5.2 版,因此,同样的我们必须去安装 phpVirtualBox 的 5.2 版本。
运行如下的命令去下载它:
$ wget https://github.com/phpvirtualbox/phpvirtualbox/archive/5.2-0.zip使用如下命令解压下载的安装包:
$ unzip 5.2-0.zip这个命令将解压 5.2.0.zip 文件的内容到一个名为 phpvirtualbox-5.2-0 的文件夹中。现在,复制或移动这个文件夹的内容到你的 apache web 服务器的根文件夹中。
$ sudo mv phpvirtualbox-5.2-0/ /var/www/html/phpvirtualbox给 phpvirtualbox 文件夹分配适当的权限。
$ sudo chmod 777 /var/www/html/phpvirtualbox/接下来,我们开始配置 phpVirtualBox。
像下面这样复制示例配置文件。
$ sudo cp /var/www/html/phpvirtualbox/config.php-example /var/www/html/phpvirtualbox/config.php编辑 phpVirtualBox 的 config.php 文件:
$ sudo nano /var/www/html/phpvirtualbox/config.php找到下列行,并且用你的系统用户名和密码去替换它(就是前面的“添加用户到 VirtualBox 组中”节中使用的用户名)。
在我的案例中,我的 Ubuntu 系统用户名是 sk ,它的密码是 ubuntu。
var $username = 'sk';
var $password = 'ubuntu';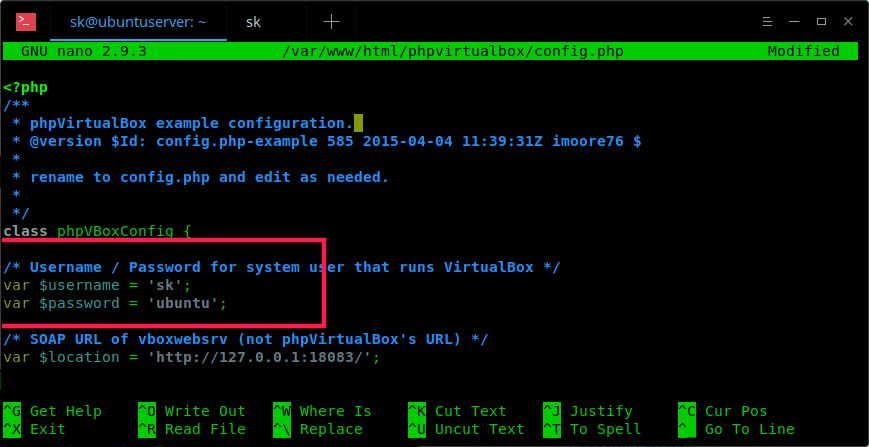
保存并关闭这个文件。
接下来,创建一个名为 /etc/default/virtualbox 的新文件:
$ sudo nano /etc/default/virtualbox添加下列行。用你自己的系统用户替换 sk。
VBOXWEB_USER=sk最后,重引导你的系统或重启下列服务去完成整个配置工作。
$ sudo systemctl restart vboxweb-service
$ sudo systemctl restart vboxdrv
$ sudo systemctl restart apache2调整防火墙允许连接 Apache web 服务器
如果你在 Ubuntu 18.04 LTS 上启用了 UFW,那么在默认情况下,apache web 服务器是不能被任何远程系统访问的。你必须通过下列的步骤让 http 和 https 流量允许通过 UFW。
首先,我们使用如下的命令来查看在策略中已经安装了哪些应用:
$ sudo ufw app list
Available applications:
Apache
Apache Full
Apache Secure
OpenSSH正如你所见,Apache 和 OpenSSH 应该已经在 UFW 的策略文件中安装了。
如果你在策略中看到的是 Apache Full,说明它允许流量到达 80 和 443 端口:
$ sudo ufw app info "Apache Full"
Profile: Apache Full
Title: Web Server (HTTP,HTTPS)
Description: Apache v2 is the next generation of the omnipresent Apache web
server.
Ports:
80,443/tcp现在,运行如下的命令去启用这个策略中的 HTTP 和 HTTPS 的入站流量:
$ sudo ufw allow in "Apache Full"
Rules updated
Rules updated (v6)如果你希望允许 https 流量,但是仅是 http (80) 的流量,运行如下的命令:
$ sudo ufw app info "Apache"访问 phpVirtualBox 的 Web 控制台
现在,用任意一台远程系统的 web 浏览器来访问。
在地址栏中,输入:http://IP-address-of-virtualbox-headless-server/phpvirtualbox。
在我的案例中,我导航到这个链接 – http://192.168.225.22/phpvirtualbox。
你将看到如下的屏幕输出。输入 phpVirtualBox 管理员用户凭据。
phpVirtualBox 的默认管理员用户名和密码是 admin / admin。
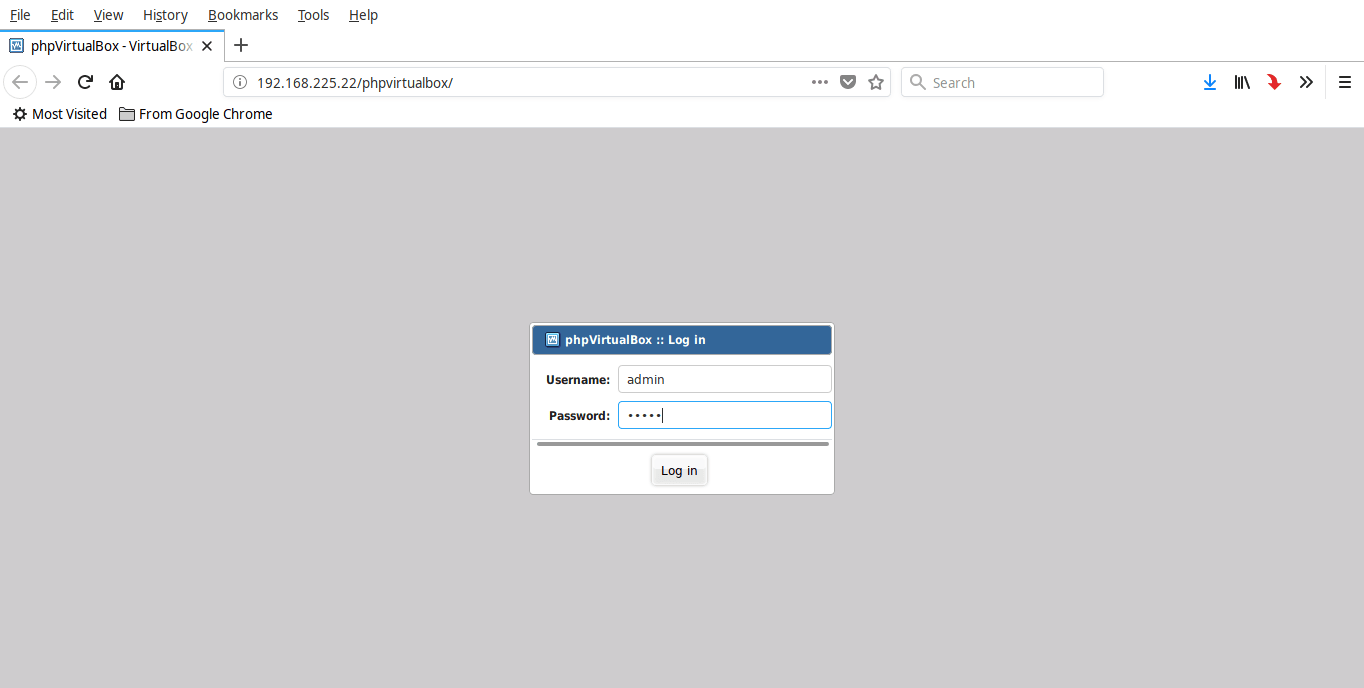
恭喜!你现在已经进入了 phpVirtualBox 管理面板了。
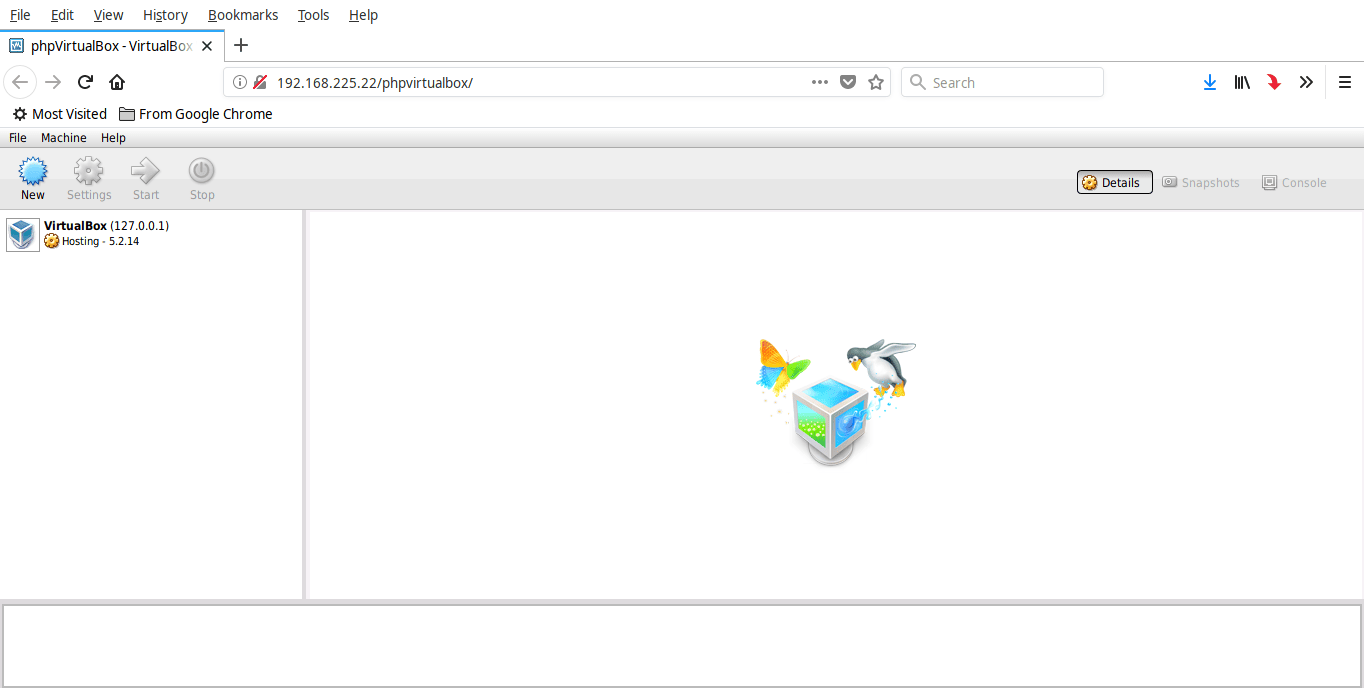
现在,你可以从 phpvirtualbox 的管理面板上,开始去创建你的 VM 了。正如我在前面提到的,你可以从同一网络上的任意一台系统上访问 phpVirtualBox 了,而所需要的仅仅是一个 web 浏览器和 phpVirtualBox 的用户名和密码。
如果在你的宿主机系统(不是访客机)的 BIOS 中没有启用虚拟化支持,phpVirtualBox 将只允许你去创建 32 位的访客系统。要安装 64 位的访客系统,你必须在你的宿主机的 BIOS 中启用虚拟化支持。在你的宿主机的 BIOS 中你可以找到一些类似于 “virtualization” 或 “hypervisor” 字眼的选项,然后确保它是启用的。
本文到此结束了,希望能帮到你。如果你找到了更有用的指南,共享出来吧。
还有一大波更好玩的东西即将到来,请继续关注!
via: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/










")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
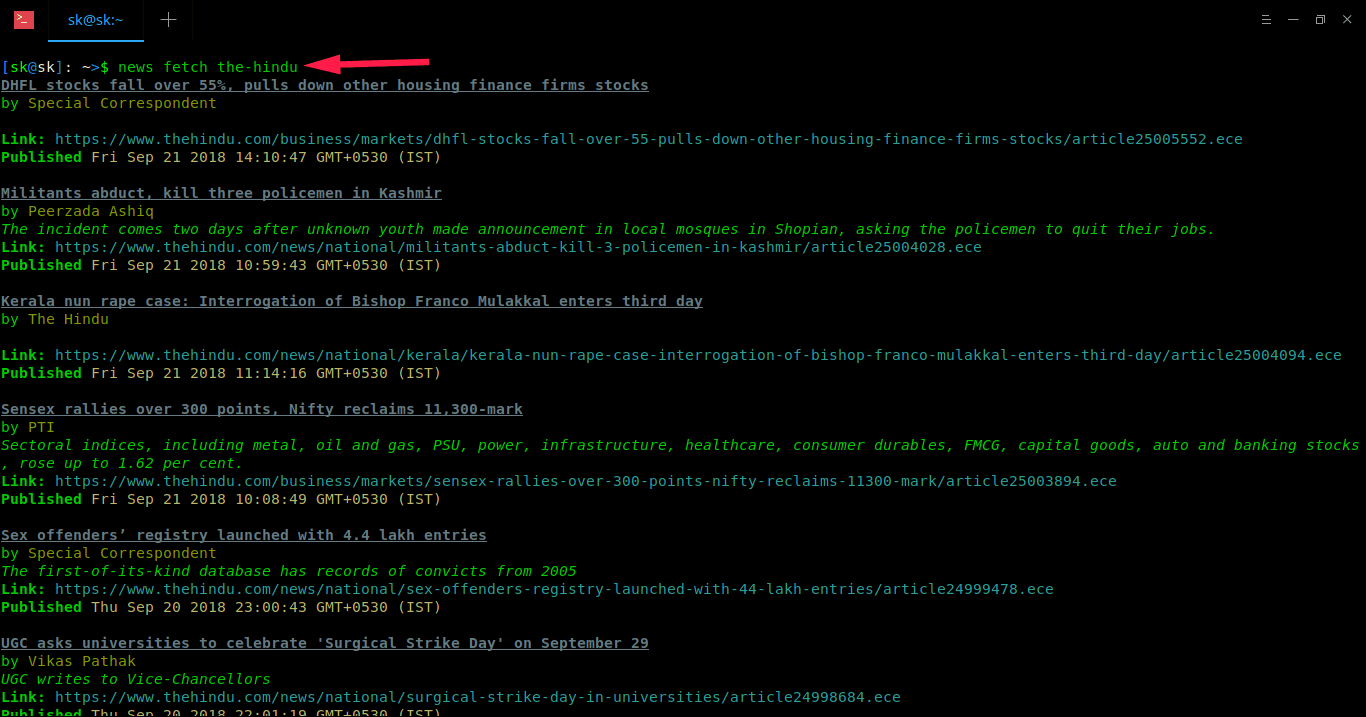
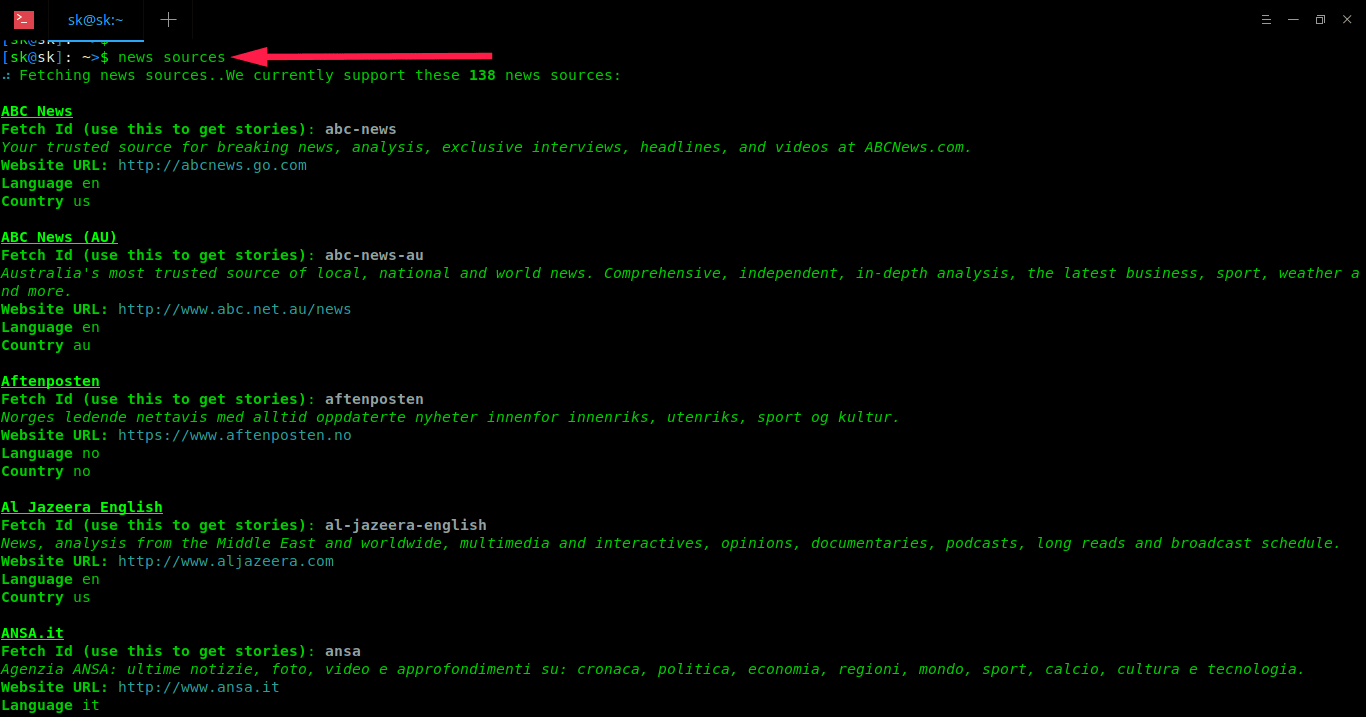
")
")