超过 3 亿用户正在使用 Stream。这些用户全都依赖我们的框架,而我们十分擅长测试要放到生产环境中的任何东西。我们大部分的代码库是用 Go 语言编写的,剩下的部分则是用 Python 编写。
我们最新的展示应用,Winds 2.0,是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
为什么测试如此重要
我们都向生产环境中推送过糟糕的提交,并且遭受了其后果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够完全地重构代码,并自信重构之后的代码仍然可以正常运行。这在你刚刚开始编写代码的时候尤为重要。
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(或破坏)。
编写测试同时会促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
困难的部分
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统一直在变大。例如,如果你用的是 macOS,运行 brew upgrade(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
以下是一些马上映入脑海的痛点:
- 在 Node.js 中进行测试是非常主观而又不主观的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
- 有一堆框架能够用在你的应用里。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你最终会想要从零开始编写自己的 测试执行平台 测试执行平台。
- 几乎可以保证你 需要 编写自己的测试执行平台(马上就会讲到这一节)。
以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
编写你自己的测试执行平台
所以……你可能会好奇test runner测试执行平台 是 什么,说实话,它并不复杂。测试执行平台是测试套件中最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?别那么快下结论。
我们所了解到的是,尽管现在就有足够多的测试框架了,但没有一个测试框架为 Node.js 提供了构建你的测试执行平台的标准方式。不幸的是,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
- 能够加载不同的配置(比如,本地的、测试的、开发的),并确保你 永远不会 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
- 播种数据库——产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
- 能够加载配置(带有用于开发环境测试的播种数据的文件)。
开发 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
尽管这不是测试执行平台的一部分,有一个 配置 加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手程序,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
Winds 中用到的工具
尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
Mocha
Mocha,被称为 “运行在 Node.js 上的特性丰富的测试框架”,是我们用于该任务的首选工具。拥有超过 15K 的星标,很多支持者和贡献者,我们知道对于这种任务,这是正确的框架。
Chai
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— Chai。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。拥有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 期望 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
describe('retrieve user', () => {
let user;
before(async () => {
await loadFixture('user');
user = await User.findOne({email: authUser.email});
expect(user).to.not.be.null;
});
after(async () => {
await User.remove().exec();
});
describe('valid request', () => {
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
expect(response).to.have.status(200);
expect(response.body._id).to.equal(user._id.toString());
});
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
const anotherUser = await User.findOne({email: '[email protected]'});
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
expect(response).to.have.status(200);
expect(response.body._id).to.equal(anotherUser._id.toString());
expect(response.body).to.not.have.an('email');
});
});
describe('invalid requests', () => {
it('should return 404 if requested user does not exist', async () => {
const nonExistingId = '5b10e1c601e9b8702ccfb974';
expect(await User.findOne({_id: nonExistingId})).to.be.null;
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
expect(response).to.have.status(404);
});
});
});
Sinon
拥有与任何单元测试框架相适应的能力,Sinon 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成了简单而轻松的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
Nock
对于所有外部的 HTTP 请求,我们使用健壮的 HTTP 模拟库 nock,在你要和第三方 API 交互时非常易用(比如说 Stream 的 REST API)。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 personalization:
nock(config.stream.baseUrl)
.get(/winds_article_recommendations/)
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
Mock-require
mock-require 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们是它的超级粉丝。
Istanbul
Istanbul 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
最终结果 — 运行测试
有了这些库,还有之前提过的测试执行平台,现在让我们看看什么是完整的测试(你可以在 这里 看看我们完整的测试套件):
import nock from 'nock';
import { expect, request } from 'chai';
import api from '../../src/server';
import Article from '../../src/models/article';
import config from '../../src/config';
import { dropDBs, loadFixture, withLogin } from '../utils.js';
describe('Article controller', () => {
let article;
before(async () => {
await dropDBs();
await loadFixture('initial-data', 'articles');
article = await Article.findOne({});
expect(article).to.not.be.null;
expect(article.rss).to.not.be.null;
});
describe('get', () => {
it('should return the right article via /articles/:articleId', async () => {
let response = await withLogin(request(api).get(`/articles/${article.id}`));
expect(response).to.have.status(200);
});
});
describe('get parsed article', () => {
it('should return the parsed version of the article', async () => {
const response = await withLogin(
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
);
expect(response).to.have.status(200);
});
});
describe('list', () => {
it('should return the list of articles', async () => {
let response = await withLogin(request(api).get('/articles'));
expect(response).to.have.status(200);
});
});
describe('list from personalization', () => {
after(function () {
nock.cleanAll();
});
it('should return the list of articles', async () => {
nock(config.stream.baseUrl)
.get(/winds_article_recommendations/)
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
const response = await withLogin(
request(api).get('/articles').query({
type: 'recommended',
})
);
expect(response).to.have.status(200);
expect(response.body.length).to.be.at.least(1);
expect(response.body[0].url).to.eq(article.url);
});
});
});
持续集成
有很多可用的持续集成服务,但我们钟爱 Travis CI,因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
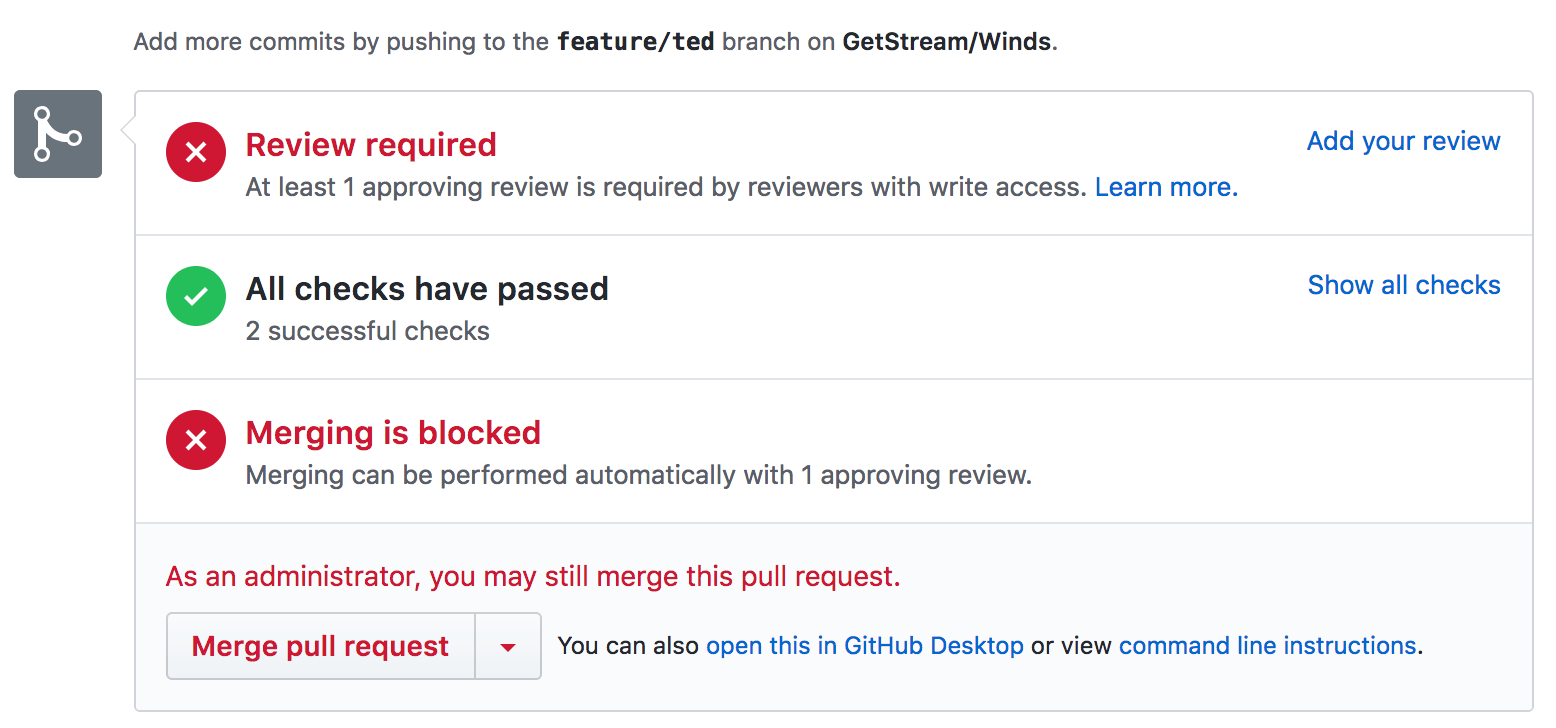
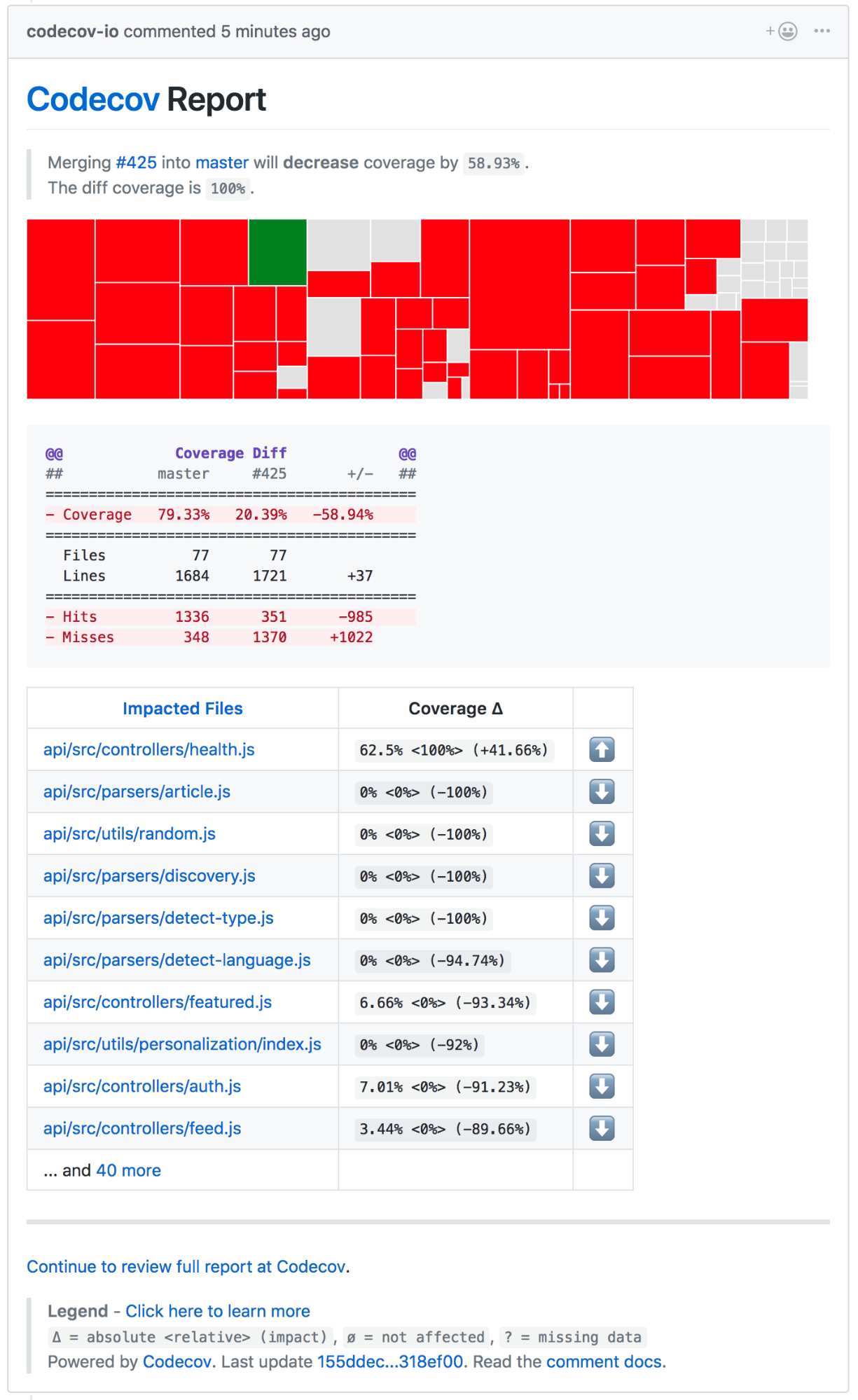
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 npm 命令进行测试。测试覆盖率反馈给 GitHub,在 GitHub 上我们将清楚地看出我们最新的代码或者 PR 是不是通过了测试。GitHub 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 GitHub 上看到 (经过了测试的) PR 的简单截图:
除了 Travis CI,我们还用到了叫做 CodeCov 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们查看代码覆盖率、文件变动、行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。
我们学到了什么
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有所谓“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
但在那时到来之前,我们还会接着用自己的测试套件,它开源在 Winds 的 GitHub 仓库。
局限
创建配置没有简单的方法
有的框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
以下命令会把整个数据库导出到 db.json 文件中:
./manage.py dumpdata > db.json
以下命令仅导出 django 中 admin.logentry 表里的内容:
./manage.py dumpdata admin.logentry > logentry.json
以下命令会导出 auth.user 表中的内容:
./manage.py dumpdata auth.user > user.json
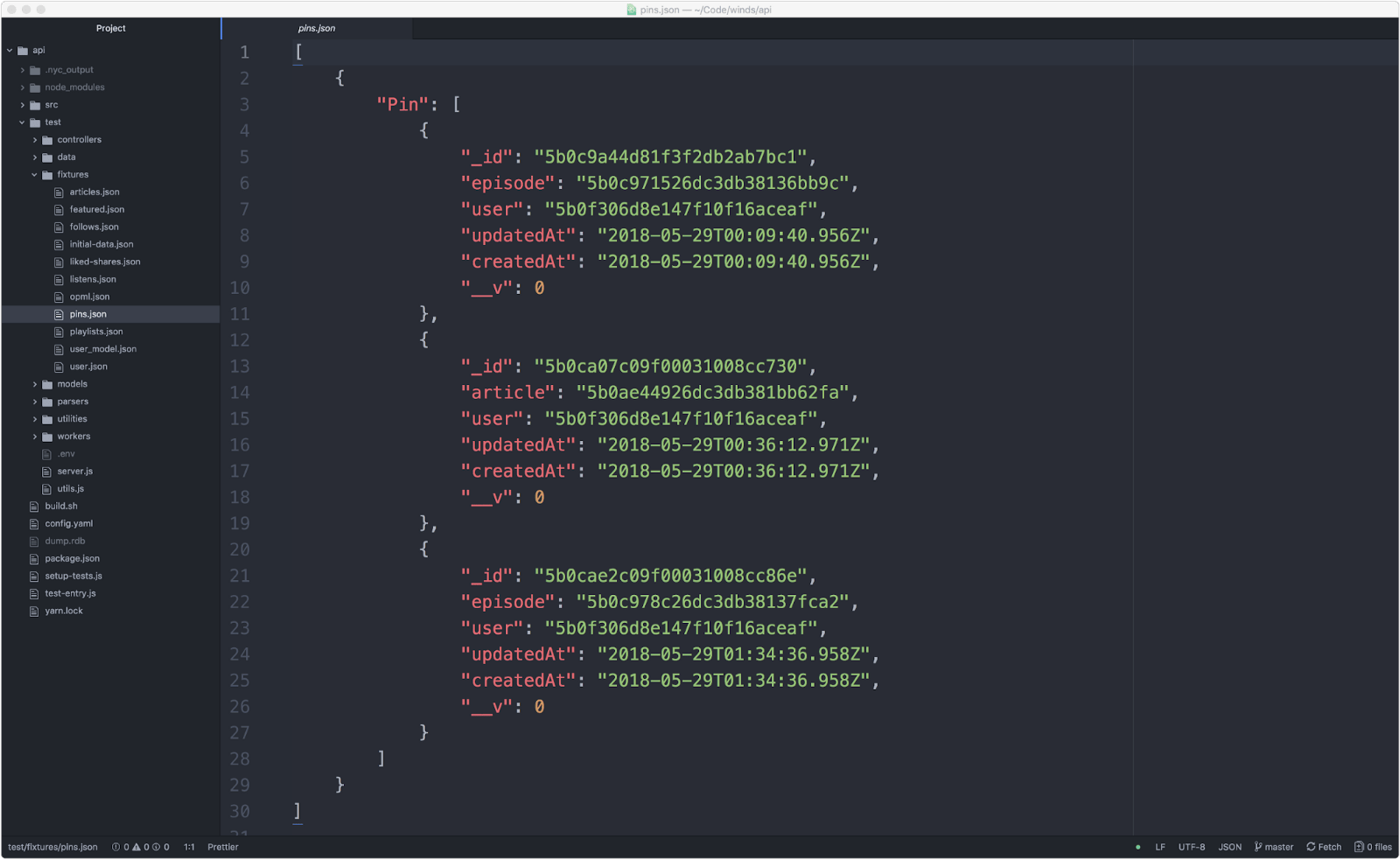
Node.js 里面没有创建配置的简单方式。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):
使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
为了支持多种 node 版本,和获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用 mock-require 来介入模块的加载,所以我们经历了罕见的怪异的模块加载过程,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
当一个模块导出多个函数,其中一个函数调用了其他的函数,就不可能模拟使用在模块内部的函数。原因在于当你引用一个 ES6 模块时,你得到的引用集合和模块内部的是不同的。任何重新绑定引用,将其指向新值的尝试都无法真正影响模块内部的函数,内部函数仍然使用的是原始的函数。
最后的思考
测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
如今有很多方式获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 JavaScript Weekly 和 Node Weekly 是良好的开始。还有,关注一些 reddit 子模块如 /r/node 也不错。如果你喜欢了解最新的趋势,State of JS 在测试领域帮助开发者可视化趋势方面就做的很好。
最后,这里是一些我喜欢的博客,我经常在这上面发文章:
觉得我遗漏了某些重要的东西?在评论区或者 Twitter @NickParsons 让我知道。
还有,如果你想要了解 Stream,我们的网站上有很棒的 5 分钟教程。点 这里 进行查看。
作者简介:
Nick Parsons
Dreamer. Doer. Engineer. Developer Evangelist https://getstream.io.
via: https://hackernoon.com/testing-node-js-in-2018-10a04dd77391
作者:Nick Parsons 译者:BriFuture 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出