虽然有些人认为区块链是一个早晚会出现问题的解决方案,但是毫无疑问,这个创新技术是一个计算机技术上的奇迹。那么,究竟什么是区块链呢?
区块链
以 比特币 或其它加密货币按时间顺序公开地记录交易的数字账本。
更通俗的说,它是一个公开的数据库,新的数据存储在被称之为 区块 的容器中,并被添加到一个不可变的 链 中(因此被称为 区块链 ),之前添加的数据也在该链中。对于比特币或其它加密货币来说,这些数据就是一组组交易,不过,也可以是其它任何类型的数据。
区块链技术带来了全新的、完全数字化的货币,如比特币和 莱特币 ,它们并不由任何中心机构管理。这给那些认为当今的银行系统是骗局并将最终走向失败的人带来了自由。区块链也革命性地改变了分布式计算的技术形式,如 以太坊 就引入了一种有趣的概念: 智能合约 。
在这篇文章中,我将用不到 50 行的 Python 2.x 代码实现一个简单的区块链,我把它叫做 SnakeCoin。
不到 50 行代码的区块链
我们首先将从定义我们的区块是什么开始。在区块链中,每个区块随同时间戳及可选的索引一同存储。在 SnakeCoin 中,我们会存储这两者。为了确保整个区块链的完整性,每个区块都会有一个自识别的哈希值。如在比特币中,每个区块的哈希是该块的索引、时间戳、数据和前一个区块的哈希值等数据的加密哈希值。这里提及的“数据”可以是任何你想要的数据。
import hashlib as hasher
class Block:
def __init__(self, index, timestamp, data, previous_hash):
self.index = index
self.timestamp = timestamp
self.data = data
self.previous_hash = previous_hash
self.hash = self.hash_block()
def hash_block(self):
sha = hasher.sha256()
sha.update(str(self.index) +
str(self.timestamp) +
str(self.data) +
str(self.previous_hash))
return sha.hexdigest()
真棒,现在我们有了区块的结构了,不过我们需要创建的是一个区块链。我们需要把区块添加到一个实际的链中。如我们之前提到过的,每个区块都需要前一个区块的信息。但问题是,该区块链中的第一个区块在哪里?好吧,这个第一个区块,也称之为创世区块,是一个特别的区块。在很多情况下,它是手工添加的,或通过独特的逻辑添加的。
我们将创建一个函数来简单地返回一个创世区块解决这个问题。这个区块的索引为 0 ,其包含一些任意的数据值,其“前一哈希值”参数也是任意值。
import datetime as date
def create_genesis_block():
# Manually construct a block with
# index zero and arbitrary previous hash
return Block(0, date.datetime.now(), "Genesis Block", "0")
现在我们可以创建创世区块了,我们需要一个函数来生成该区块链中的后继区块。该函数将获取链中的前一个区块作为参数,为要生成的区块创建数据,并用相应的数据返回新的区块。新的区块的哈希值来自于之前的区块,这样每个新的区块都提升了该区块链的完整性。如果我们不这样做,外部参与者就很容易“改变过去”,把我们的链替换为他们的新链了。这个哈希链起到了加密的证明作用,并有助于确保一旦一个区块被添加到链中,就不能被替换或移除。
def next_block(last_block):
this_index = last_block.index + 1
this_timestamp = date.datetime.now()
this_data = "Hey! I'm block " + str(this_index)
this_hash = last_block.hash
return Block(this_index, this_timestamp, this_data, this_hash)
这就是主要的部分。
现在我们能创建自己的区块链了!在这里,这个区块链是一个简单的 Python 列表。其第一个的元素是我们的创世区块,我们会添加后继区块。因为 SnakeCoin 是一个极小的区块链,我们仅仅添加了 20 个区块。我们通过循环来完成它。
# Create the blockchain and add the genesis block
blockchain = [create_genesis_block()]
previous_block = blockchain[0]
# How many blocks should we add to the chain
# after the genesis block
num_of_blocks_to_add = 20
# Add blocks to the chain
for i in range(0, num_of_blocks_to_add):
block_to_add = next_block(previous_block)
blockchain.append(block_to_add)
previous_block = block_to_add
# Tell everyone about it!
print "Block #{} has been added to the blockchain!".format(block_to_add.index)
print "Hash: {}\n".format(block_to_add.hash)
让我们看看我们的成果:
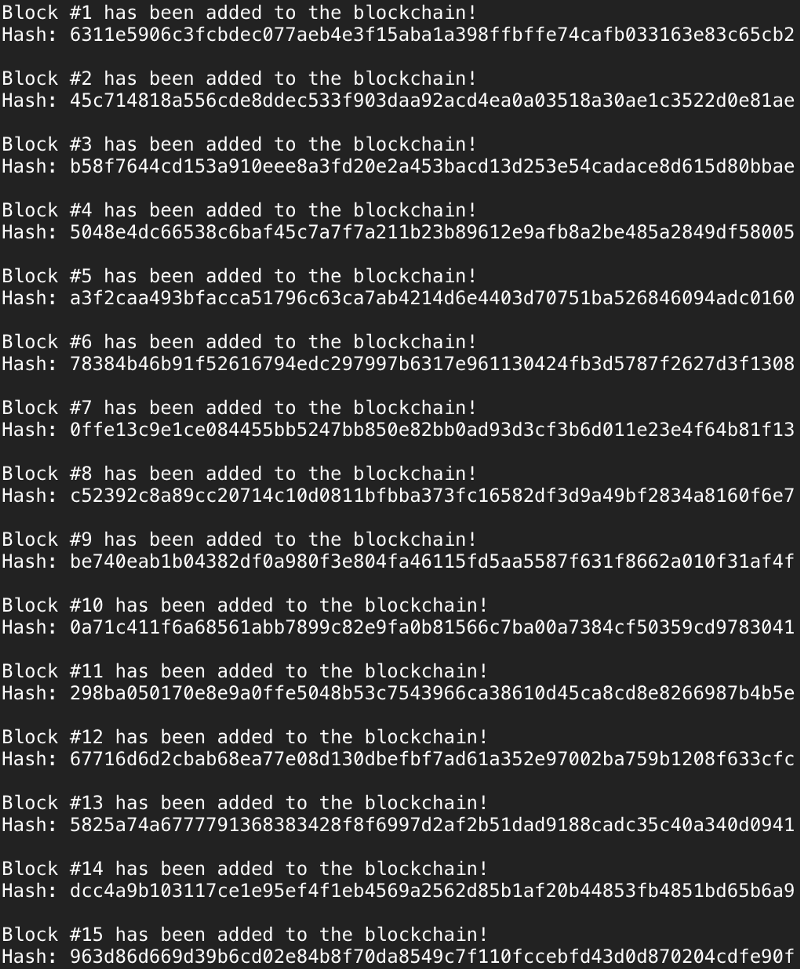
别担心,它将一直添加到 20 个区块
很好,我们的区块链可以工作了。如果你想要在主控台查看更多的信息,你可以编辑其完整的源代码并输出每个区块的时间戳或数据。
这就是 SnakeCoin 所具有的功能。要使 SnakeCoin 达到现今的产品级的区块链的高度,我们需要添加更多的功能,如服务器层,以在多台机器上跟踪链的改变,并通过工作量证明算法(POW)来限制给定时间周期内可以添加的区块数量。
如果你想了解更多技术细节,你可以在这里查看最初的比特币白皮书。
让这个极小区块链稍微变大些
这个极小的区块链及其简单,自然也相对容易完成。但是因其简单也带来了一些缺陷。首先,SnakeCoin 仅能运行在单一的一台机器上,所以它相距分布式甚远,更别提去中心化了。其次,区块添加到区块链中的速度同在主机上创建一个 Python 对象并添加到列表中一样快。在我们的这个简单的区块链中,这不是问题,但是如果我们想让 SnakeCoin 成为一个实际的加密货币,我们就需要控制在给定时间内能创建的区块(和币)的数量。
从现在开始,SnakeCoin 中的“数据”将是交易数据,每个区块的“数据”字段都将是一些交易信息的列表。接着我们来定义“交易”。每个“交易”是一个 JSON 对象,其记录了币的发送者、接收者和转移的 SnakeCoin 数量。注:交易信息是 JSON 格式,原因我很快就会说明。
{
"from": "71238uqirbfh894-random-public-key-a-alkjdflakjfewn204ij",
"to": "93j4ivnqiopvh43-random-public-key-b-qjrgvnoeirbnferinfo",
"amount": 3
}
现在我们知道了交易信息看起来的样子了,我们需要一个办法来将其加到我们的区块链网络中的一台计算机(称之为节点)中。要做这个事情,我们会创建一个简单的 HTTP 服务器,以便每个用户都可以让我们的节点知道发生了新的交易。节点可以接受 POST 请求,请求数据为如上的交易信息。这就是为什么交易信息是 JSON 格式的:我们需要它们可以放在请求信息中传递给服务器。
$ pip install flask # 首先安装 Web 服务器框架
from flask import Flask
from flask import request
node = Flask(__name__)
# Store the transactions that
# this node has in a list
this_nodes_transactions = []
@node.route('/txion', methods=['POST'])
def transaction():
if request.method == 'POST':
# On each new POST request,
# we extract the transaction data
new_txion = request.get_json()
# Then we add the transaction to our list
this_nodes_transactions.append(new_txion)
# Because the transaction was successfully
# submitted, we log it to our console
print "New transaction"
print "FROM: {}".format(new_txion['from'])
print "TO: {}".format(new_txion['to'])
print "AMOUNT: {}\n".format(new_txion['amount'])
# Then we let the client know it worked out
return "Transaction submission successful\n"
node.run()
真棒!现在我们有了一种保存用户彼此发送 SnakeCoin 的记录的方式。这就是为什么人们将区块链称之为公共的、分布式账本:所有的交易信息存储给所有人看,并被存储在该网络的每个节点上。
但是,有个问题:人们从哪里得到 SnakeCoin 呢?现在还没有办法得到,还没有一个称之为 SnakeCoin 这样的东西,因为我们还没有创建和分发任何一个币。要创建新的币,人们需要“挖”一个新的 SnakeCoin 区块。当他们成功地挖到了新区块,就会创建出一个新的 SnakeCoin ,并奖励给挖出该区块的人(矿工)。一旦挖矿的矿工将 SnakeCoin 发送给别人,这个币就流通起来了。
我们不想让挖新的 SnakeCoin 区块太容易,因为这将导致 SnakeCoin 太多了,其价值就变低了;同样,我们也不想让它变得太难,因为如果没有足够的币供每个人使用,它们对于我们来说就太昂贵了。为了控制挖新的 SnakeCoin 区块的难度,我们会实现一个 工作量证明 (PoW)算法。工作量证明基本上就是一个生成某个项目比较难,但是容易验证(其正确性)的算法。这个项目被称之为“证明”,听起来就像是它证明了计算机执行了特定的工作量。
在 SnakeCoin 中,我们创建了一个简单的 PoW 算法。要创建一个新区块,矿工的计算机需要递增一个数字,当该数字能被 9 (“SnakeCoin” 这个单词的字母数)整除时,这就是最后这个区块的证明数字,就会挖出一个新的 SnakeCoin 区块,而该矿工就会得到一个新的 SnakeCoin。
# ...blockchain
# ...Block class definition
miner_address = "q3nf394hjg-random-miner-address-34nf3i4nflkn3oi"
def proof_of_work(last_proof):
# Create a variable that we will use to find
# our next proof of work
incrementor = last_proof + 1
# Keep incrementing the incrementor until
# it's equal to a number divisible by 9
# and the proof of work of the previous
# block in the chain
while not (incrementor % 9 == 0 and incrementor % last_proof == 0):
incrementor += 1
# Once that number is found,
# we can return it as a proof
# of our work
return incrementor
@node.route('/mine', methods = ['GET'])
def mine():
# Get the last proof of work
last_block = blockchain[len(blockchain) - 1]
last_proof = last_block.data['proof-of-work']
# Find the proof of work for
# the current block being mined
# Note: The program will hang here until a new
# proof of work is found
proof = proof_of_work(last_proof)
# Once we find a valid proof of work,
# we know we can mine a block so
# we reward the miner by adding a transaction
this_nodes_transactions.append(
{ "from": "network", "to": miner_address, "amount": 1 }
)
# Now we can gather the data needed
# to create the new block
new_block_data = {
"proof-of-work": proof,
"transactions": list(this_nodes_transactions)
}
new_block_index = last_block.index + 1
new_block_timestamp = this_timestamp = date.datetime.now()
last_block_hash = last_block.hash
# Empty transaction list
this_nodes_transactions[:] = []
# Now create the
# new block!
mined_block = Block(
new_block_index,
new_block_timestamp,
new_block_data,
last_block_hash
)
blockchain.append(mined_block)
# Let the client know we mined a block
return json.dumps({
"index": new_block_index,
"timestamp": str(new_block_timestamp),
"data": new_block_data,
"hash": last_block_hash
}) + "\n"
现在,我们能控制特定的时间段内挖到的区块数量,并且我们给了网络中的人新的币,让他们彼此发送。但是如我们说的,我们只是在一台计算机上做的。如果区块链是去中心化的,我们怎样才能确保每个节点都有相同的链呢?要做到这一点,我们会使每个节点都广播其(保存的)链的版本,并允许它们接受其它节点的链。然后,每个节点会校验其它节点的链,以便网络中每个节点都能够达成最终的链的共识。这称之为 共识算法 。
我们的共识算法很简单:如果一个节点的链与其它的节点的不同(例如有冲突),那么最长的链保留,更短的链会被删除。如果我们网络上的链没有了冲突,那么就可以继续了。
@node.route('/blocks', methods=['GET'])
def get_blocks():
chain_to_send = blockchain
# Convert our blocks into dictionaries
# so we can send them as json objects later
for block in chain_to_send:
block_index = str(block.index)
block_timestamp = str(block.timestamp)
block_data = str(block.data)
block_hash = block.hash
block = {
"index": block_index,
"timestamp": block_timestamp,
"data": block_data,
"hash": block_hash
}
# Send our chain to whomever requested it
chain_to_send = json.dumps(chain_to_send)
return chain_to_send
def find_new_chains():
# Get the blockchains of every
# other node
other_chains = []
for node_url in peer_nodes:
# Get their chains using a GET request
block = requests.get(node_url + "/blocks").content
# Convert the JSON object to a Python dictionary
block = json.loads(block)
# Add it to our list
other_chains.append(block)
return other_chains
def consensus():
# Get the blocks from other nodes
other_chains = find_new_chains()
# If our chain isn't longest,
# then we store the longest chain
longest_chain = blockchain
for chain in other_chains:
if len(longest_chain) < len(chain):
longest_chain = chain
# If the longest chain wasn't ours,
# then we set our chain to the longest
blockchain = longest_chain
我们差不多就要完成了。在运行了完整的 SnakeCoin 服务器代码之后,在你的终端可以运行如下代码。(假设你已经安装了 cCUL)。
1、创建交易
curl "localhost:5000/txion" \
-H "Content-Type: application/json" \
-d '{"from": "akjflw", "to":"fjlakdj", "amount": 3}'
2、挖一个新区块
curl localhost:5000/mine
3、 查看结果。从客户端窗口,我们可以看到。

对代码做下美化处理,我们看到挖矿后我们得到的新区块的信息:
{
"index": 2,
"data": {
"transactions": [
{
"to": "fjlakdj",
"amount": 3,
"from": "akjflw"
},
{
"to": "q3nf394hjg-random-miner-address-34nf3i4nflkn3oi",
"amount": 1,
"from": "network"
}
],
"proof-of-work": 36
},
"hash": "151edd3ef6af2e7eb8272245cb8ea91b4ecfc3e60af22d8518ef0bba8b4a6b18",
"timestamp": "2017-07-23 11:23:10.140996"
}
大功告成!现在 SnakeCoin 可以运行在多个机器上,从而创建了一个网络,而且真实的 SnakeCoin 也能被挖到了。
你可以根据你的喜好去修改 SnakeCoin 服务器代码,并问各种问题了。
在下一篇(LCTT 译注:截止至本文翻译,作者还没有写出下一篇),我们将讨论创建一个 SnakeCoin 钱包,这样用户就可以发送、接收和存储他们的 SnakeCoin 了。