理解运转良好的系统对于处理不可避免的故障是最好的准备。

关于开源软件最古老的笑话是:“代码是 自具文档化的 ”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个功能正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
从某些方面看,启动过程非常简单。内核在单核上以单线程和同步状态启动,似乎可以理解。但内核本身是如何启动的呢?initrd(initial ramdisk) 和 引导程序 具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
请继续阅读寻找答案。在 GitHub 上也提供了 介绍演示和练习的代码。
启动的开始:OFF 状态
局域网唤醒
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用了局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
# sudo ethtool <interface name>
其中 <interface name> 是网络接口的名字,比如 eth0。(ethtool 可以在同名的 Linux 软件包中找到。)如果输出中的 Wake-on 显示 g,则远程主机可以通过发送 魔法数据包 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
# sudo ethtool -s <interface name> wol d
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 底板管理控制器 (BMC)。
英特尔管理引擎、平台控制器单元和 Minix
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86\_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,它开启了如 KVM 远程控制和英特尔功能许可服务等 功能。根据 Intel 自己的检测工具,IME 存在尚未修补的漏洞。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 me\_cleaner 项目,它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
IME 固件和 系统管理模式 (SMM)软件是 基于 Minix 操作系统 的,并运行在单独的 平台控制器单元 上(LCTT 译注:即南桥芯片),而不是主 CPU 上。然后,SMM 启动位于主处理器上的 通用可扩展固件接口 (UEFI)软件,相关内容 已被提及多次。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 非扩展性缩减版固件 (NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 禁用了 IME 的笔记本电脑,另外 带有 ARM 64 位处理器笔记本电脑 还是值得期待的。
引导程序
除了启动那些问题不断的间谍软件外,早期引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供通用操作系统(如 Linux)所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 闪存和 NAND 闪存。引导程序还与 可信平台模块 (TPM)等硬件安全设备进行交互,在启动最开始建立信任链。

在构建主机上的沙盒中运行 U-boot 引导程序。
包括树莓派、任天堂设备、汽车主板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 U-Boot。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续集成(CI)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
# git clone git://git.denx.de/u-boot; cd u-boot
# make ARCH=sandbox defconfig
# make; ./u-boot
=> printenv
=> help
在 x86\_64 上运行 U-Boot,可以测试一些棘手的功能,如 模拟存储设备 的重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 Ctrl + C 恢复一个“变砖”的沙盒。
启动内核
配置引导内核
引导程序完成任务后将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 file /boot/vmlinuz 可以看到它是一个 “bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— extract-vmlinux:
# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
# file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
linked, stripped
内核是一个 可执行与可链接格式 (ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 binutils 包中的命令,如 readelf 来检查它。比较一下输出,例如:
# readelf -S /bin/date
# readelf -S vmlinux
这两个二进制文件中的段内容大致相同。
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 main() 函数中?并不确切。
在 main() 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 stdio、stdout 和 stderr 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用 “glibc”)中获取这些资源。参照以下输出:
# file /bin/date
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
stripped
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 #! 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 _start() 函数来用所需资源 配置一个二进制文件,这个函数可以从 glibc 源代码包中找到,可以 用 GDB 查看。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个 未剥离的 vmlinux,例如 apt-get install linux-image-amd64-dbg,或者从源代码编译和安装你自己的内核,可以参照 Debian Kernel Handbook 中的指令。gdb vmlinux 后加 info files 可显示 ELF 段 init.text。在 init.text 中用 l *(address) 列出程序执行的开头,其中 address 是 init.text 的十六进制开头。用 GDB 可以看到 x86\_64 内核从内核文件 arch/x86/kernel/head\_64.S 开始启动,在这个文件中我们找到了汇编函数 start_cpu0(),以及一段明确的代码显示在调用 x86_64 start_kernel() 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 arch/arm/kernel/head.S。start_kernel() 不针对特定的体系结构,所以这个函数驻留在内核的 init/main.c 中。start_kernel() 可以说是 Linux 真正的 main() 函数。
从 start\_kernel() 到 PID 1
内核的硬件清单:设备树和 ACPI 表
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法: 设备树 和 高级配置和电源接口(ACPI)表。内核通过读取这些文件了解每次启动时需要运行的硬件。
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 vmlinux 一样位于 /boot 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 /boot/*.dtb 匹配的文件执行 binutils 包中的 strings 命令即可,这里 dtb 是指 设备树二进制文件 。显然,只需编辑构成它的类 JSON 的文件并重新运行随内核源代码提供的特殊 dtc 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 设备树覆盖 的功能,内核在启动后可以动态加载热插拔的附加设备。
x86 系列和许多企业级的 ARM64 设备使用 ACPI 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 /sys/firmware/acpi/tables 虚拟文件系统中。读取 ACPI 表的简单方法是使用 acpica-tools 包中的 acpidump 命令。例如:

联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 acpi_listen 命令(在 apcid 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 覆盖 ACPI 表 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 安装 coreboot,这是开源固件的替代品。
从 start\_kernel() 到用户空间
init/main.c 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 dmesg | head,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 timekeeping_init() 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,dmesg 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 rest_init() 中,该函数在终止时由 start_kernel() 调用。

早期的内核启动流程。
函数 rest_init() 产生了一个新进程以运行 kernel_init(),并调用了 do_initcalls()。用户可以通过将 initcall_debug 附加到内核命令行来监控 initcalls,这样每运行一次 initcall 函数就会产生 一个 dmesg 条目。initcalls 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。initcalls 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。rest_init() 也会在引导处理器上产生第二个线程,它首先运行 cpu_idle(),然后等待调度器分配工作。
kernel_init() 也可以 设置对称多处理(SMP)结构。在较新的内核中,如果 dmesg 的输出中出现 “Bringing up secondary CPUs...” 等字样,系统便使用了 SMP。SMP 通过“热插拔” CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个 核 离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 BCC 工具 称为 offcputime.py。
请注意,init/main.c 中的代码在 smp_init() 运行时几乎已执行完毕:引导处理器已经完成了大部分一次性初始化操作,其它核无需重复。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 ps -o psr 命令可以查看服务每个 CPU 上的线程的 softirqs 和 workqueues。
# ps -o pid,psr,comm $(pgrep ksoftirqd)
PID PSR COMMAND
7 0 ksoftirqd/0
16 1 ksoftirqd/1
22 2 ksoftirqd/2
28 3 ksoftirqd/3
# ps -o pid,psr,comm $(pgrep kworker)
PID PSR COMMAND
4 0 kworker/0:0H
18 1 kworker/1:0H
24 2 kworker/2:0H
30 3 kworker/3:0H
[ . . . ]
其中,PSR 字段代表“ 处理器 ”。每个核还必须拥有自己的定时器和 cpuhp 热插拔处理程序。
那么用户空间是如何启动的呢?在最后,kernel_init() 寻找可以代表它执行 init 进程的 initrd。如果没有找到,内核直接执行 init 本身。那么为什么需要 initrd 呢?
早期的用户空间:谁规定要用 initrd?
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 initrd 的路径。initrd 通常位于 /boot 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 initramfs-tools-core 软件包中的 lsinitramfs 工具可以列出 initrd 的内容。发行版的 initrd 方案包含了最小化的 /bin、/sbin 和 /etc 目录以及内核模块,还有 /scripts 中的一些文件。所有这些看起来都很熟悉,因为 initrd 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 /bin 和 /sbin 目录下的所有可执行文件几乎都是指向 BusyBox 二进制文件 的符号链接,由此导致 /bin 和 /sbin 目录比 glibc 的小 10 倍。
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 init,为什么还要创建一个 initrd 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 /lib/modules 的内核模块,当然还有 initrd 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 initrd 中。initrd 基本上包含了任何挂载根文件系统所必需的非内核代码。initrd 也是用户存放 自定义ACPI 表代码的地方。
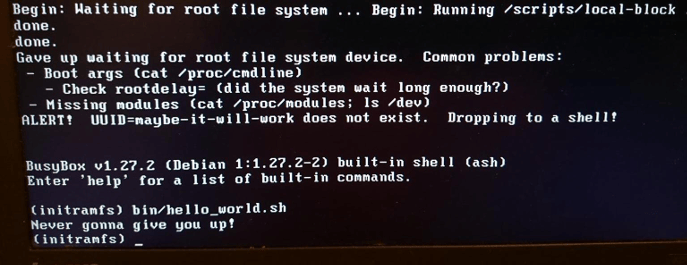 initrd."" title=" title="Rescue shell and a custom
initrd."" title=" title="Rescue shell and a custom initrd."">
救援模式的 shell 和自定义的 initrd 还是很有意思的。
initrd 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 initrd 中,并从内存中运行测试,而不是从被测对象中运行。
最后,当 init 开始运行时,系统就启动啦!由于第二个处理器现在在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,ps -o pid,psr,comm -p 1 很容易显示用户空间的 init 进程已不在引导处理器上运行了。
总结
Linux 引导过程听起来或许令人生畏,即使是简单嵌入式设备上的软件数量也是如此。但换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
要了解更多信息,请参阅 Alison Chaiken 的演讲——Linux: The first second,已于 1 月 22 日至 26 日在悉尼举行。参见 linux.conf.au。
感谢 Akkana Peck 的提议和指正。
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
作者:Alison Chaiken 译者:jessie-pang 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出