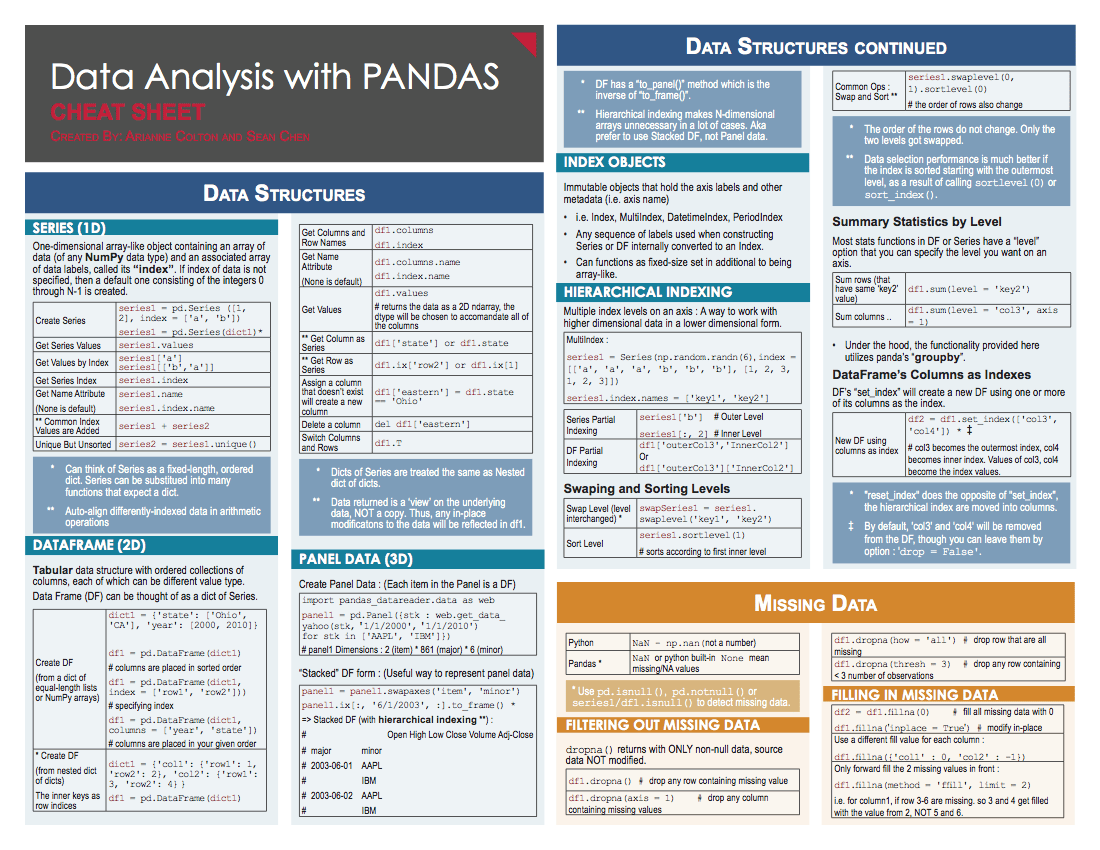
CoreOS 和 OCI 揭开了容器工业标准的论战

CoreOS 和 开放容器联盟(OCI) 周三(2017 年 7 月 19 日)发布的镜像和运行时标准主要参照了 Docker 的镜像格式技术。
然而,OCI 决定在 Docker 的事实标准平台上建立模型引发了一些问题。一些批评者提出其他方案。
CoreOS 的 CTO 及 OCI 技术管理委员会主席 Brandon Philips 说, 1.0版本为应用容器提供了一个稳定标准。他说,拥有产业领导者所创造的标准,应能激发 OCI 合作伙伴进一步地发展标准和创新。Philips 补充道,OCI 完成 1.0 版本意味着 OCI 运行时规范和 OCI 镜像格式标准现在已经可以广泛使用。此外,这一成就将推动 OCI 社区稳固日益增长的可互操作的可插拔工具集市场。
产业支持的标准将提供一种信心:容器已被广泛接受,并且 Kubernetes 用户将获得更进一步的支持。
Philips 告诉 LinuxInsider,结果是相当不错的,认证流程已经开始。
合作挑战
Philips 说,开放标准是容器生态系统取得成功的关键,构建标准的最好方式是与社区密切协作。然而,在 1.0 版本上达成共识所花费的时间超出了预期。
“早期,最大的挑战在于如今解决项目的发布模式及如何实施该项目”,他追述道,”每个人都低估了项目所要花费的时间。“
他说,OCI 联盟成员对他们想做的事情抱有不相匹配的预期,但是在过去的一年中,该组织了解了期望程度,并且经历了更多的测试。
追逐标准
CoreOS 官方在几年前就开始讨论行业支持的容器镜像和运行时规范的开放标准的想法,Phillips 说,早期的探索使我们认识到:在标准镜像格式上达成一致是至关重要的。
CoreOS 和容器技术创造者 Docker 在 2015 年 6 月宣布 OCI 成立。合作起始于 21 个行业领导者制定开放容器计划(OCP)。它作为一个非营利组织,旨在建立云存储软件容器的最低通用标准。
联盟包括容器业界的领导者:Docker、微软、红帽、IBM、谷歌和 Linux 基金会。
OCI 的目的是让应用开发者相信:当新的规范出来并开发出新的工具时,部署在容器上的软件仍然能够持续运行。这种信心必须同时满足所有私有和开源软件。
工具和应用是私有还是开源的并没有什么关系。当规范开始应用,产品可以被设计成与任何容器配置相适应,Philips 说。
“你需要有意识地超越编写代码的人能力之外创建标准。它是一个额外的付出。”他补充道。
作为联盟的一部分,Docker 向 OCP(开放容器计划)捐献出它的镜像格式的事实标准技术。它包括该公司的容器格式、运行时代码和规范。建立 OCI 镜像标准的工作起始于去年。
标准的里程碑给予容器使用者开发、打包、签名应用容器的能力。他们也能够在各种容器引擎上运行容器,Philips 强调。
唯一选择?
Pund-IT 的首席分析师 Charles King 表示:联盟面临着两种实现标准的方式。第一种选择是汇集相同意向的人员来避免分歧从零开始建立标准。
但是联盟成员似乎满足于第二种方案:采用一种强大的市场领先的平台作为一个有效的标准。
“Docker 对 Linux 基金会的贡献使 OCI 坚定的选择了第二种方案。但是那些关注于 Docker 的做法和它的市场地位的人也许感觉应该有更好的选择。”King 对 LinuxInsider 说。
事实上,有个 OCI 成员 CoreOS 在开始的时候对该组织的总体方向进行了一些强烈的批评。他说,“所以看看 V1.0 版本是否处理或不处理那些关注点将是很有趣的事情。”
更快之路
Docker 已经被广泛部署的运行时实现是建立开放标准的合适基础。据 Cloud Technology Partners 的高级副总裁 David Linthicum 所说,Docker 已经是一个事实标准。
“我们能很快就让它们工作起来也是很重要的。但是一次次的标准会议、处理政治因素以及诸如此类的事情只是浪费时间” 。他告诉 LinuxInsider。
但是现在没有更好的选择,他补充道。
据 RedHat 公司的 Linux 容器技术高级布道者 Joe Brockmeier 所说,Docker 的运行时是 runC 。它是 OCI 运行时标准的一种实现。
“因此,runC 是一个合适的运行时标准的基础。它被广泛的接受并成为了大多数容器技术实现的基础。他说。
OCI 是比 Docker 更进一步的标准。尽管 Docker 确实提交了遵循 OCI 规范的底层代码,然而这一系列代码就此停止,并且没真正的可行替代方案存在。
对接问题
Pund-IT 的 King 建议:采用一种广泛使用的产业标准将简化和加速许多公司对容器技术的采纳和管理。也有可能一些关键的供应商将继续关注他们自己的专有容器技术。
“他们辩称他们的做法是一个更好的方式,但这将有效的阻止 OCI 取得市场的主导地位。”他说,“从一个大体上实现的标准开始,就像 OCI 所做的那样,也许并不能完美的使所有人满意,但是这也许能比其他方案更加快速有效的实现目标。”
容器已经标准化的部署到了云上,Docker 显然是领先的。Semaphore 联合创始人 Marko Anastasov 说。
他说,Docker 事实标准的容器代表了开发开放标准的的最佳基础。Docker 的商业利益将如何影响其参与 OCI 的规模还有待观察。
反对观点
开放标准并不是在云部署中采用更多的容器的最终目标。ThoughtWorks 的首席顾问 Nic Cheneweth 表示。更好的的方法是查看 IT 行业的服务器虚拟化部分的影响。
Cheneweth 对 LinuxInsider 说:“持续增长和广泛采用的主要动力不是在行业标准的声明中,而是通过使用任何竞争技术所获得的潜在的和实现的效率,比如 VMware、Xen 等。”
容器技术的某些方面,例如容器本身,可以根据标准来定义。他说,在此之前,深入开源软件参与引导的健康竞争将有助于成为一个更好的标准。
据 Cheneweth 说,容器编排标准对该领域的持续增长并不特别重要。
不过,他表示,如果行业坚持锁定容器事实标准,那么 OCI 所选择的模型是一个很好的起点。“我不知道是否有更好的选择,但肯定这不是最糟糕的选择。”
作者简介:
自 2003 年以来,Jack M.Germain一直是一个新闻网络记者。他主要关注的领域是企业 IT、Linux 和开源技术。他已经写了很多关于 Linux 发行版和其他开源软件的评论。
via: http://www.linuxinsider.com/story/84689.html
作者:Jack M. Germain 译者:LHRchina 校对:wxy