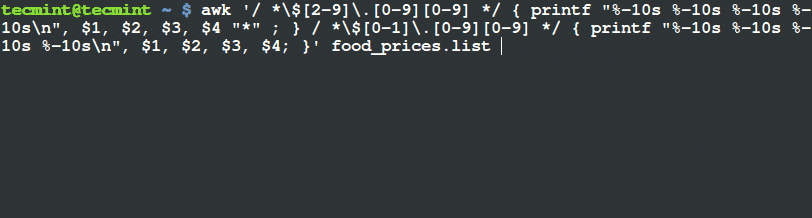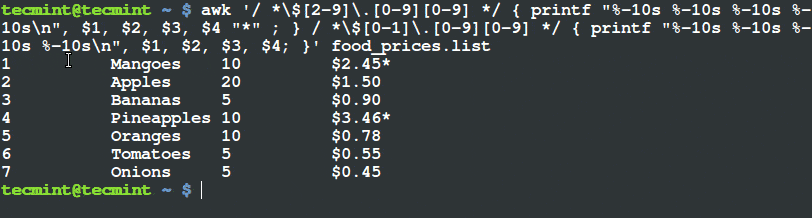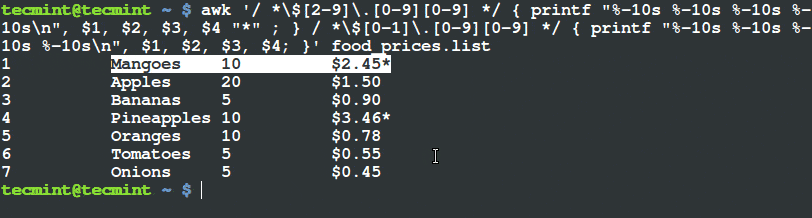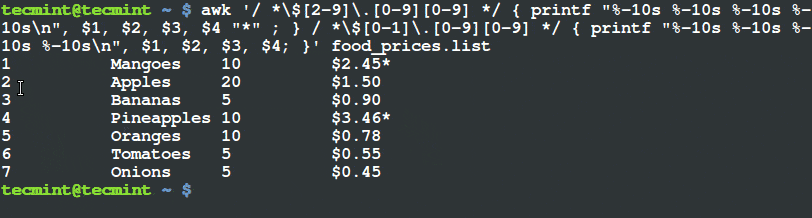
你知道 OpenCV 可以识别在图片中小猫的脸吗?而且是拿来就能用,不需要其它的库之类的。
之前我也不知道。
但是在 Kendrick Tan 曝出这个功能后,我需要亲自体验一下……去看看到 OpenCV 是如何在我没有察觉到的情况下,将这一个功能添加进了他的软件库(就像一只悄悄溜进空盒子的猫咪一样,等待别人发觉)。
下面,我将会展示如何使用 OpenCV 的猫咪检测器在图片中识别小猫的脸。同样的,该技术也可以用在视频流中。
使用 OpenCV 在图片中检测猫咪
如果你查找过 OpenCV 的代码仓库,尤其是在 haarcascades 目录里(OpenCV 在这里保存处理它预先训练好的 Haar 分类器,以检测各种物体、身体部位等), 你会看到这两个文件:
- haarcascade\_frontalcatface.xml
- haarcascade\_frontalcatface\_extended.xml
这两个 Haar Cascade 文件都将被用来在图片中检测小猫的脸。实际上,我使用了相同的 cascades 分类器来生成这篇博文顶端的图片。
在做了一些调查工作之后,我发现这些 cascades 分类器是由鼎鼎大名的 Joseph Howse 训练和贡献给 OpenCV 仓库的,他写了很多很棒的教程和书籍,在计算机视觉领域有着很高的声望。
下面,我将会展示给你如何使用 Howse 的 Haar cascades 分类器来检测图片中的小猫。
猫咪检测代码
让我们开始使用 OpenCV 来检测图片中的猫咪。新建一个叫 cat\_detector.py 的文件,并且输入如下的代码:
# import the necessary packages
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-c", "--cascade",
default="haarcascade_frontalcatface.xml",
help="path to cat detector haar cascade")
args = vars(ap.parse_args())
第 2 和第 3 行主要是导入了必要的 python 包。6-12 行用于解析我们的命令行参数。我们仅要求一个必需的参数 --image ,它是我们要使用 OpenCV 检测猫咪的图片。
我们也可以(可选的)通过 --cascade 参数指定我们的 Haar cascade 分类器的路径。默认使用 haarcascades_frontalcatface.xml,假定这个文件和你的 cat_detector.py 在同一目录下。
注意:我已经打包了猫咪的检测代码,还有在这个教程里的样本图片。你可以在博文原文的 “下载” 部分下载到。如果你是刚刚接触 Python+OpenCV(或者 Haar cascade),我建议你下载这个 zip 压缩包,这个会方便你跟着教程学习。
接下来,就是检测猫的时刻了:
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# load the cat detector Haar cascade, then detect cat faces
# in the input image
detector = cv2.CascadeClassifier(args["cascade"])
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
minNeighbors=10, minSize=(75, 75))
在 15、16 行,我们从硬盘上读取了图片,并且进行灰度化(这是一个在将图片传给 Haar cascade 分类器之前的常用的图片预处理步骤,尽管不是必须的)
20 行,从硬盘加载 Haar casacade 分类器,即猫咪检测器,并且实例化 cv2.CascadeClassifier 对象。
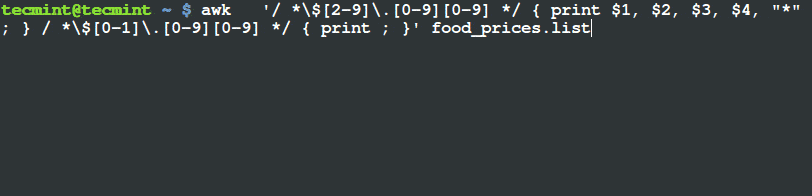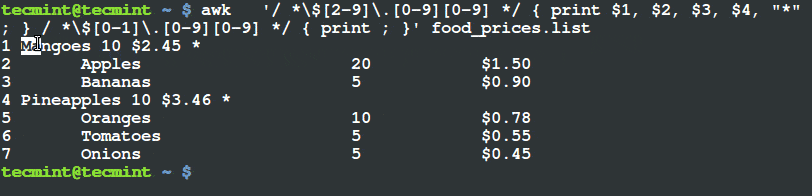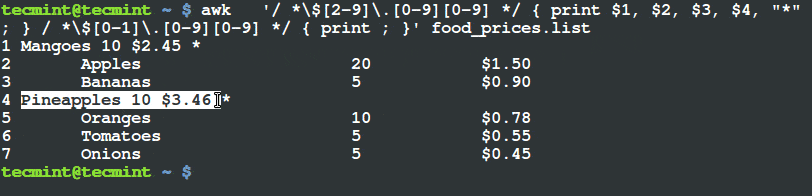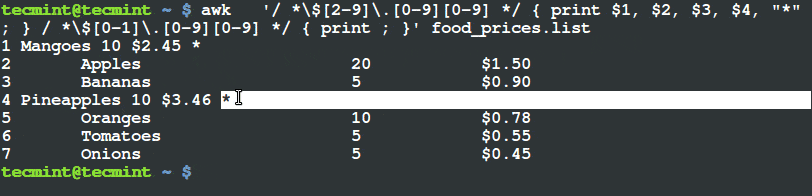
在 21、22 行通过调用 detector 的 detectMultiScale 方法使用 OpenCV 完成猫脸检测。我们给 detectMultiScale 方法传递了四个参数。包括:
- 图片
gray,我们要在该图片中检测猫脸。 - 检测猫脸时的图片金字塔 的检测粒度
scaleFactor 。更大的粒度将会加快检测的速度,但是会对检测 准确性 产生影响。相反的,一个更小的粒度将会影响检测的时间,但是会增加 准确性 。但是,细粒度也会增加 误报率 。你可以看这篇博文的“ Haar cascades 注意事项”部分来获得更多的信息。 minNeighbors 参数控制了检定框的最少数量,即在给定区域内被判断为猫脸的最少数量。这个参数可以很好的排除 误报 结果。- 最后,
minSize 参数不言自明。这个值描述每个检定框的最小宽高尺寸(单位是像素),这个例子中就是 75*75
detectMultiScale 函数会返回 rects,这是一个 4 元组列表。这些元组包含了每个检测到的猫脸的 (x,y) 坐标值,还有宽度、高度。
最后,让我们在图片上画下这些矩形来标识猫脸:
# loop over the cat faces and draw a rectangle surrounding each
for (i, (x, y, w, h)) in enumerate(rects):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
# show the detected cat faces
cv2.imshow("Cat Faces", image)
cv2.waitKey(0)
给我们这些框(比如,rects)的数据,我们在 25 行依次遍历它。
在 26 行,我们在每张猫脸的周围画上一个矩形。27、28 行展示了一个整数,即图片中猫咪的数量。
最后,31,32 行在屏幕上展示了输出的图片。
猫咪检测结果
为了测试我们的 OpenCV 猫咪检测器,可以在原文的最后,下载教程的源码。
然后,在你解压缩之后,你将会得到如下的三个文件/目录:
- cat\_detector.py:我们的主程序
- haarcascade\_frontalcatface.xml: 猫咪检测器 Haar cascade
- images:我们将会使用的检测图片目录。
到这一步,执行以下的命令:
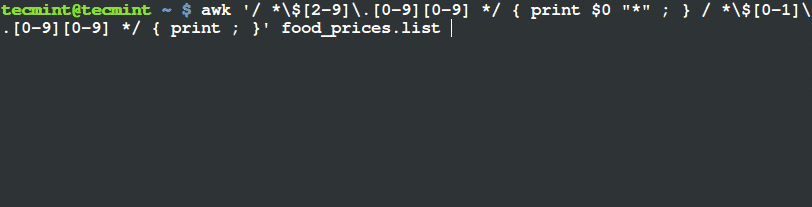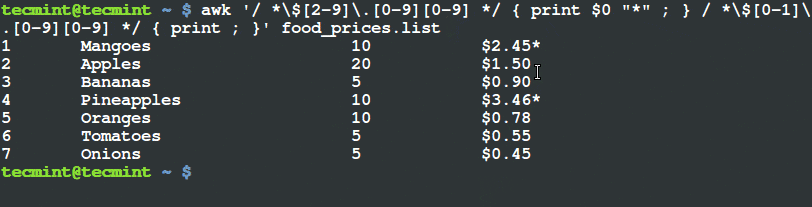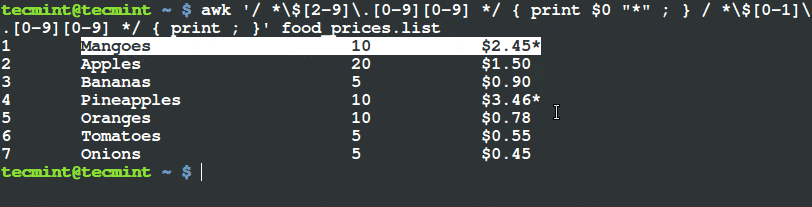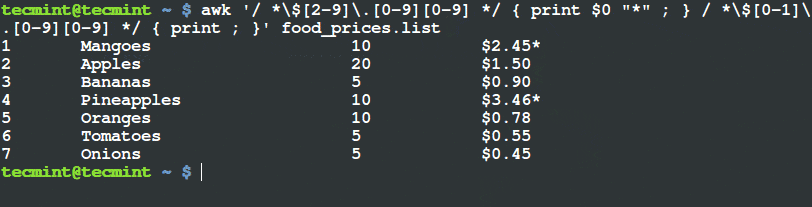
$ python cat_detector.py --image images/cat_01.jpg
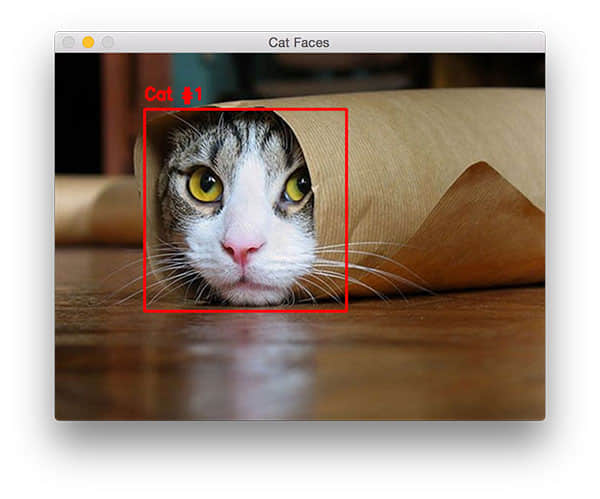
图 1. 在图片中检测猫脸,甚至是猫咪部分被遮挡了。
注意,我们已经可以检测猫脸了,即使它的其余部分是被遮挡的。
试下另外的一张图片:
python cat_detector.py --image images/cat_02.jpg

图 2. 使用 OpenCV 检测猫脸的第二个例子,这次猫脸稍有不同。
这次的猫脸和第一次的明显不同,因为它正在发出“喵呜”叫声的当中。这种情况下,我们依旧能检测到正确的猫脸。
在下面这张图片的结果也是正确的:
$ python cat_detector.py --image images/cat_03.jpg
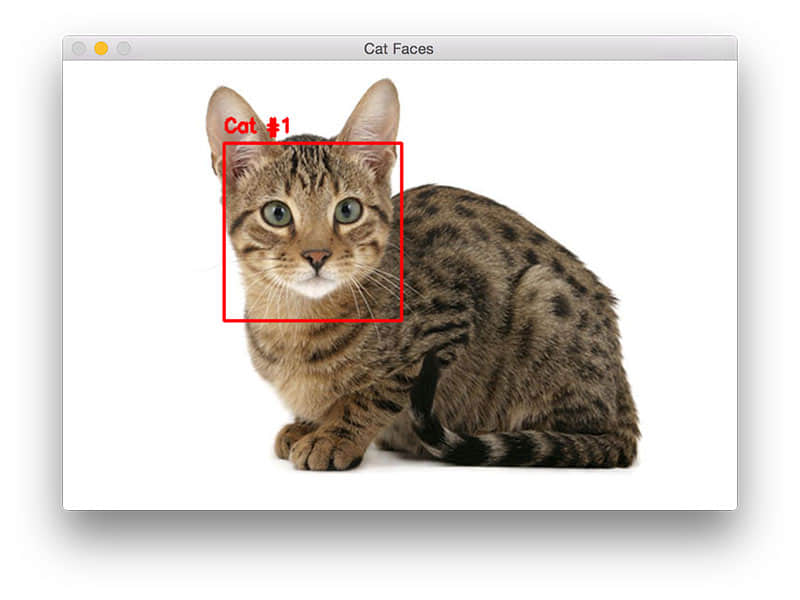
图 3. 使用 OpenCV 和 python 检测猫脸
我们最后的一个样例就是在一张图中检测多张猫脸:
$ python cat_detector.py --image images/cat_04.jpg
图 4. 在同一张图片中使用 OpenCV 检测多只猫
注意,Haar cascade 返回的检定框不一定是以你预期的顺序。这种情况下,中间的那只猫会被标记成第三只。你可以通过判断他们的 (x, y) 坐标来自己排序这些检定框。
关于精度的说明
在这个 xml 文件中的注释非常重要,Joseph Hower 提到了这个猫脸检测器有可能会将人脸识别成猫脸。
这种情况下,他推荐使用两种检测器(人脸 & 猫脸),然后将出现在人脸识别结果中的结果剔除掉。
Haar cascades 注意事项
这个方法首先出现在 Paul Viola 和 Michael Jones 2001 年出版的 Rapid Object Detection using a Boosted Cascade of Simple Features 论文中。现在它已经成为了计算机识别领域引用最多的论文之一。
这个算法能够识别图片中的对象,无论它们的位置和比例。而且最令人感兴趣的或许是它能在现有的硬件条件下实现实时检测。
在他们的论文中,Viola 和 Jones 关注在训练人脸检测器;但是,这个框架也能用来检测各类事物,如汽车、香蕉、路标等等。
问题是?
Haar cascades 最大的问题就是如何确定 detectMultiScale 方法的参数正确。特别是 scaleFactor 和 minNeighbors 参数。你很容易陷入一张一张图片调参数的坑,这个就是该对象检测器很难被实用化的原因。
这个 scaleFactor 变量控制了用来检测对象的图片的各种比例的图像金字塔。如果 scaleFactor 参数过大,你就只需要检测图像金字塔中较少的层,这可能会导致你丢失一些在图像金字塔层之间缩放时少了的对象。
换句话说,如果 scaleFactor 参数过低,你会检测过多的金字塔图层。这虽然可以能帮助你检测到更多的对象。但是他会造成计算速度的降低,还会明显提高误报率。Haar cascades 分类器就是这样。
为了避免这个,我们通常使用 Histogram of Oriented Gradients + 线性 SVM 检测 替代。
上述的 HOG + 线性 SVM 框架的参数更容易调优。而且更好的误报率也更低,但是唯一不好的地方是无法实时运算。
对对象识别感兴趣?并且希望了解更多?

图 5. 在 PyImageSearch Gurus 课程中学习如何构建自定义的对象识别器。
如果你对学习如何训练自己的自定义对象识别器感兴趣,请务必要去了解下 PyImageSearch Gurus 课程。
在这个课程中,我提供了 15 节课,覆盖了超过 168 页的教程,来教你如何从 0 开始构建自定义的对象识别器。你会掌握如何应用 HOG + 线性 SVM 框架来构建自己的对象识别器来识别路标、面孔、汽车(以及附近的其它东西)。
要学习 PyImageSearch Gurus 课程(有 10 节示例免费课程),点此: https://www.pyimagesearch.com/pyimagesearch-gurus/?src=post-cat-detection
总结
在这篇博文里,我们学习了如何使用 OpenCV 默认就有的 Haar cascades 分类器来识别图片中的猫脸。这些 Haar casacades 是由 Joseph Howse 训练兵贡献给 OpenCV 项目的。我是在 Kendrick Tan 的这篇文章中开始注意到这个。
尽管 Haar cascades 相当有用,但是我们也经常用 HOG + 线性 SVM 替代。因为后者相对而言更容易使用,并且可以有效地降低误报率。
我也会在 PyImageSearch Gurus 课程中详细的讲述如何构建定制的 HOG + 线性 SVM 对象识别器,来识别包括汽车、路标在内的各种事物。
不管怎样,我希望你喜欢这篇博文。
via: http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/
作者:Adrian Rosebrock 译者:MikeCoder 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出