Linux 有一个显著的特点,在正常情况下,你可以通过日志分析系统日志来了解你的系统中发生了什么,或正在发生什么。的确,系统日志是系统管理员在解决系统和应用问题时最需要的第一手资源。我们将在这篇文章中着重讲解 Apache HTTP web server 生成的 Apache access 日志。
这次,我们会通过另类的途径来分析 Apache access 日志,我们使用的工具是 asql。asql 是一个开源的工具,它能够允许使用者使用 SQL 语句来查询日志,从而通过更加友好的格式展现相同的信息。

Apache 日志背景知识
Apache 有两种日志:
- Access log:存放在路径 /var/log/apache2/access.log (Debian) 或者 /var/log/httpd/access\_log (Red Hat)。Access Log 记录所有 Apache web server 执行的请求。
- Error log:存放在路径 /var/log/apache2/error.log (Debian) 或者 /var/log/httpd/error\_log (Red Hat)。Error log 记录所有 Apache web server 报告的错误以及错误的情况。Error 情况包括(不限于)403(Forbidden,通常在请求被拒绝访问时被报告),404(Not found,在请求资源不存在时被报告)。
虽然管理员可以通过配置 Apache 的配置文件来自定义 Apache access log 的详细程度,不过在这篇文章中,我们会使用默认的配置,如下:
远程 IP - 请求时间 - 请求类型 - 响应代码 - 请求的 URL - 远程的浏览器信息 (也许包含操作系统信息)
因此一个典型的 Apache 日志条目就是下面这个样子:
192.168.0.101 - - [22/Aug/2014:12:03:36 -0300] "GET /icons/unknown.gif HTTP/1.1" 200 519 "http://192.168.0.10/test/projects/read_json/" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:30.0) Gecko/20100101 Firefox/30.0"
但是 Apache error log 又是怎么样的呢?因为 error log 条目主要记录 access log 中特殊的请求(你可以自定义),所以你可以通过 access log 来获得关于错误情况的更多信息(example 5 有更多细节)。
此外要提前说明的, access log 是系统级别的日志文件。要分析虚拟主机的日志文件,你需要检查它们相应的配置文件(例如: 在 /etc/apache2/sites-available/[virtual host name] 里(Debian))。
在 Linux 上安装 asql
asql 由 Perl 编写,而且需求以下两个 Perl 模块:SQLite 的 DBI 驱动以及 GNU readline。
在 Debian, Ubuntu 以及其衍生发行版上安装 asql
使用基于 Debian 发行版上的 aptitude,asql 以及其依赖会被自动安装。
# aptitude install asql
在 Fedora,CentOS,RHEL 上安装 asql
在 CentOS 或 RHEL 上,你需要启用 EPEL repository,然后运行以下代码。在 Fedora 中,直接运行以下代码:
# sudo yum install perl-DBD-SQLite perl-Term-Readline-Gnu
# wget http://www.steve.org.uk/Software/asql/asql-1.7.tar.gz
# tar xvfvz asql-1.7.tar.gz
# cd asql
# make install
asql 是如何工作的?
从上面代码中的依赖中你就可以看出来,asql 转换未结构化的明文 Apache 日志为结构化的 SQLite 数据库信息。生成的 SQLite 数据库可以接受正常的 SQL 查询语句。数据库可以通过当前以及之前的日志文件生成,其中也包括压缩转换过的日志文件,类似 access.log.X.gz 或者 access\_log.old。
首先,从命令行启动 asql:
# asql
你会进入 asql 内置的 shell 交互界面。
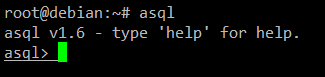
输入 help 列表可执行的命令:
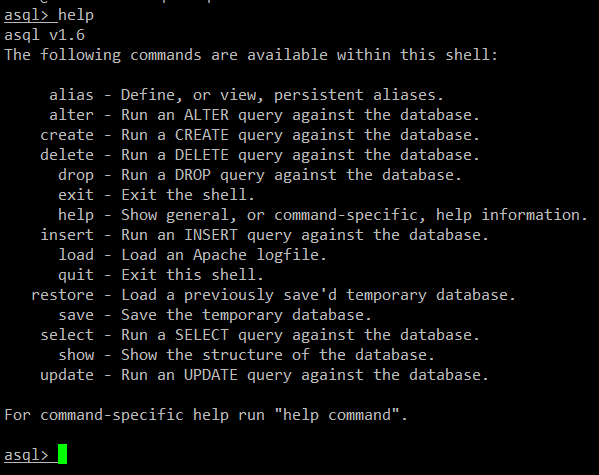
首先在 asql 中加载所有的 access 日志:
asql > load <apache-access-logs 的路径>
比如在 Debian 下:
asql > load /var/log/apache2/access.*
在 CentOS/RHEL 下:
asql > load /var/log/httpd/access_log*
当 asql 完成对 access 日志的加载后,我们就可以开始数据库查询了。注意一下,加载后生成的数据库是 "temporary" (临时)的,意思就是数据库会在你退出 asql 的时候被清除。如果你想要保留数据库,你必须先将其保存为一个文件。我们会在后面介绍如何这么做(参考 example 3 和 4)。
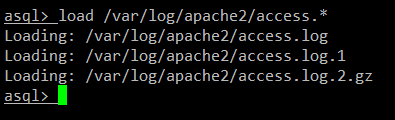
生成的数据库有一个名为 logs 的表。输入下面的命令列出 logs 表中提供的域:
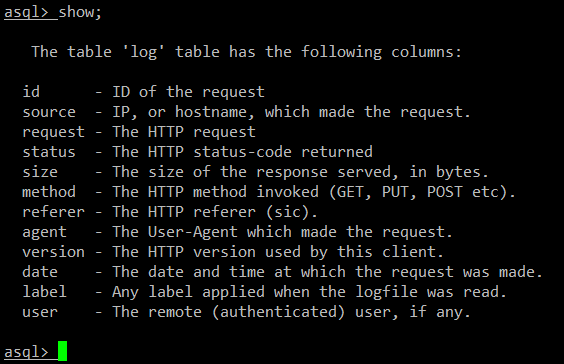
一个名为 .asql 的隐藏文件,保存于用户的 home 目录下,记录用户在 asql shell 中输入的命令历史。因此你可以使用方向键浏览命令历史,按下 ENTER 来重复执行之前的命令。
asql 上的示例 SQL 查询
下面是几个使用 asql 针对 Apache 日志文件运行 SQL 查询的示例:
Example 1:列出在 2014 年 10 月中请求的来源 / 时间以及 HTTP 状态码。
SELECT source, date, status FROM logs WHERE date >= '2014-10-01T00:00:00' ORDER BY source;

Example 2:从小到大显示单个客户端处理的请求大小(bytes)。
SELECT source, SUM(size), AS NUMBER FROM logs GROUP BY source ORDER BY Number DESC;

Example 3:在当前目录中保存数据库为 [filename]。
save [filename]
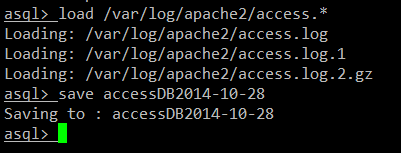
这样做可以避免使用 load 命令对日志的语法分析所占用的处理时间。
Example 4:在重新进入 asql 后载入数据库。
restore [filename]
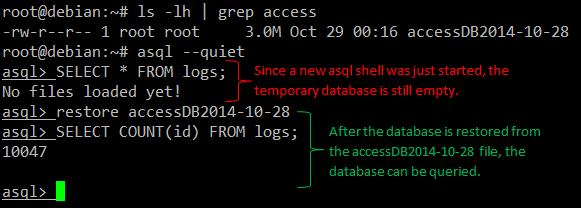
Example 5:返回 access 日志中记录的 error 情况。在这个例子中,我们将显示所有返回 HTTP 状态码为 403(access forbidden)的请求。
SELECT source, date, status, request FROM logs WHERE status='403' ORDER BY date
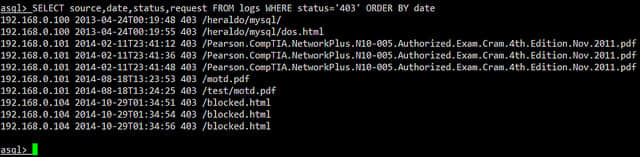
这个例子想要表现的是:虽然 asql 只分析 access 日志,我们还是可以通过使用请求的状态域来显示有 error 情况的请求。
小结:
我们体验了 asql 如何帮助我们分析 Apache 日志文件,并将结果通过友好的格式输出。虽然你也可以通过使用命令行的工具(例如 cat 与 grep,uniq,sort,wc 等等之间的管道)来实现类似功能,与此比较起来 asql 展示了它如同瑞士军刀一般的强大功能,使我们在自己的需求下能够通过标准 SQL 查询语句来过滤日志。
希望这篇教程能帮助到你们。
请不要拘束地将评论文章,分享文章,提出疑问。
via: http://xmodulo.com/sql-queries-apache-log-files-linux.html
作者:Gabriel Cánepa 译者:ThomazL 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出